
Figure 2. Four common scenarios of health outcomes and their relation to the usefulness of machine learning for measuring health outcomes from electronic health record (EHR) data.
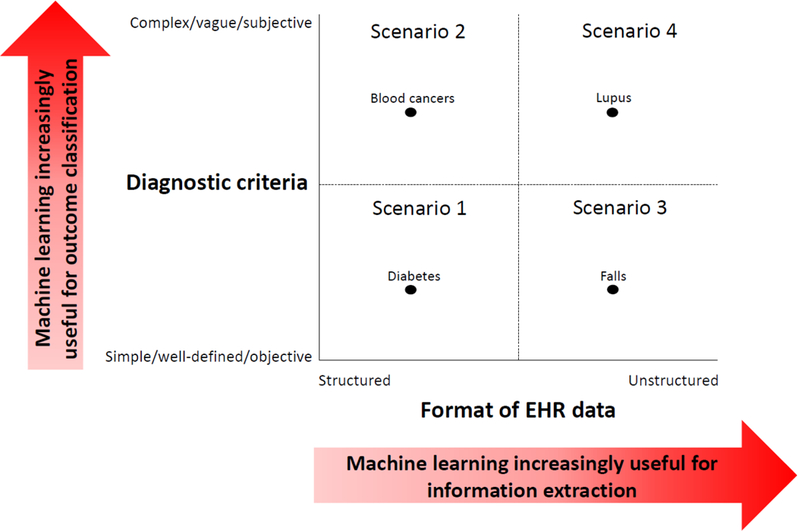
These scenarios arise by jointly considering two dimensions of a health outcome and the conditions under which machine learning may be useful in each dimension. The first dimension (Y-axis) considers several characteristics related to the diagnostic criteria for a given health outcome: 1) the number of clinical parameters involved, which may vary from few (simple) to many (complex), 2) the clarity of the outcome definition, which may vary from having clear boundaries (well-defined) to fuzzy boundaries (vague), and 3) the degree to which clinicians draw upon their personal interpretations during the diagnostic process, which may vary from small (objective) to large (subjective). For health outcomes with more complex, vague, or subjective diagnostic criteria, machine learning may be increasingly useful for predicting the presence of the health outcome based on a vector of clinical inputs (‘outcome classification’). The second dimension (X-axis) considers the format in which important diagnostic information about the health outcome is stored within EHR systems (which may vary from structured to unstructured). For health outcomes where diagnostic information is stored largely in unstructured formats, machine learning may be increasingly useful for facilitating the extraction of important clinical information in a more structured form (‘information extraction’). We dichotomize these two dimensions to create four common scenarios of health outcomes, illustrated by the four quadrants. The black dots represent examples of health conditions that fall within each quadrant.