
Fig. 2.
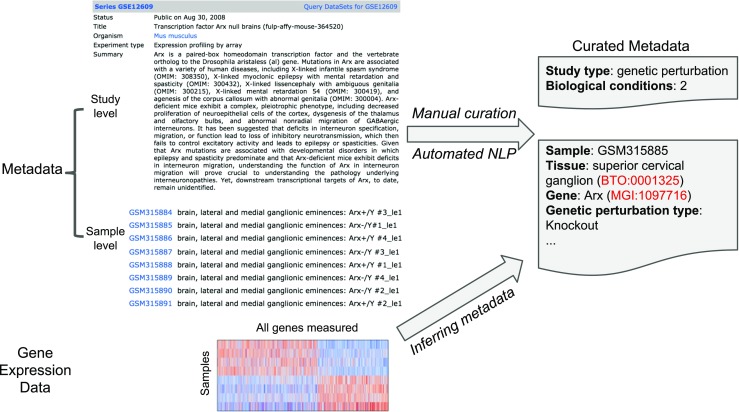
Graphical summary of various curation approaches for further annotating GEO datasets. Metadata and the gene expression data from an example GEO study are shown on the left. Metadata are composed of semi-structured textual annotations supplied by the authors of the dataset at both study-level and sample-level to describe the experimental design of the study, and the characteristics of the samples. The goal of further annotating GEO datasets is to generate structured metadata for each study (top right) and samples (bottom right). Annotations are linked to relevant controlled vocabularies such as ontologies. Three approaches are visualized as arrows: manual curation and automated NLP, both attempt to identify and extract structured metadata from the textual descriptions. In addition, metadata can be inferred from the gene expression data using supervised machine learning approaches