
Figure 2.
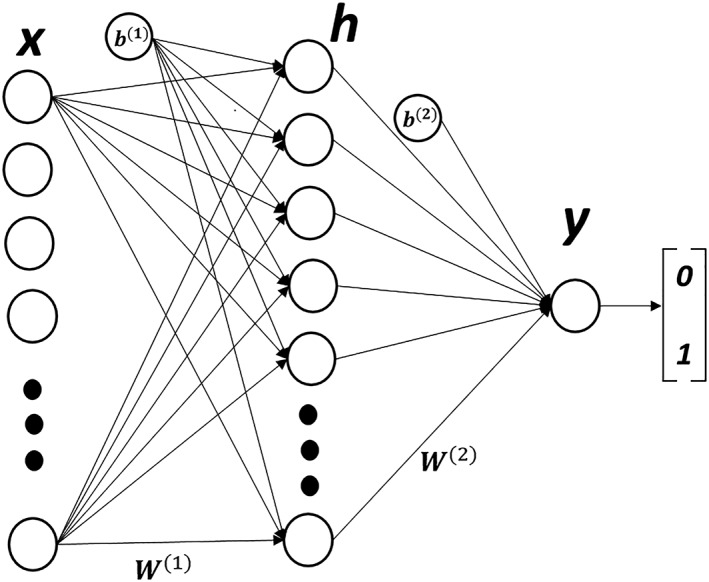
Our three‐layer multi‐layer perceptron network with one hidden layer ‘h’ containing 50 hidden nodes. ‘W’ represents the node weights, ‘b’ denotes the node biases, ‘x’ is the input feature vector, and ‘y’ represents the binary output.
Official websites use .gov
A
.gov website belongs to an official
government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you've safely
connected to the .gov website. Share sensitive
information only on official, secure websites.
Our three‐layer multi‐layer perceptron network with one hidden layer ‘h’ containing 50 hidden nodes. ‘W’ represents the node weights, ‘b’ denotes the node biases, ‘x’ is the input feature vector, and ‘y’ represents the binary output.