
Fig 6. Manipulating number of features and using all conditions to find simplest individualized models (Inset) and using the full 58 feature logistic regression (Log) as the performance to match.
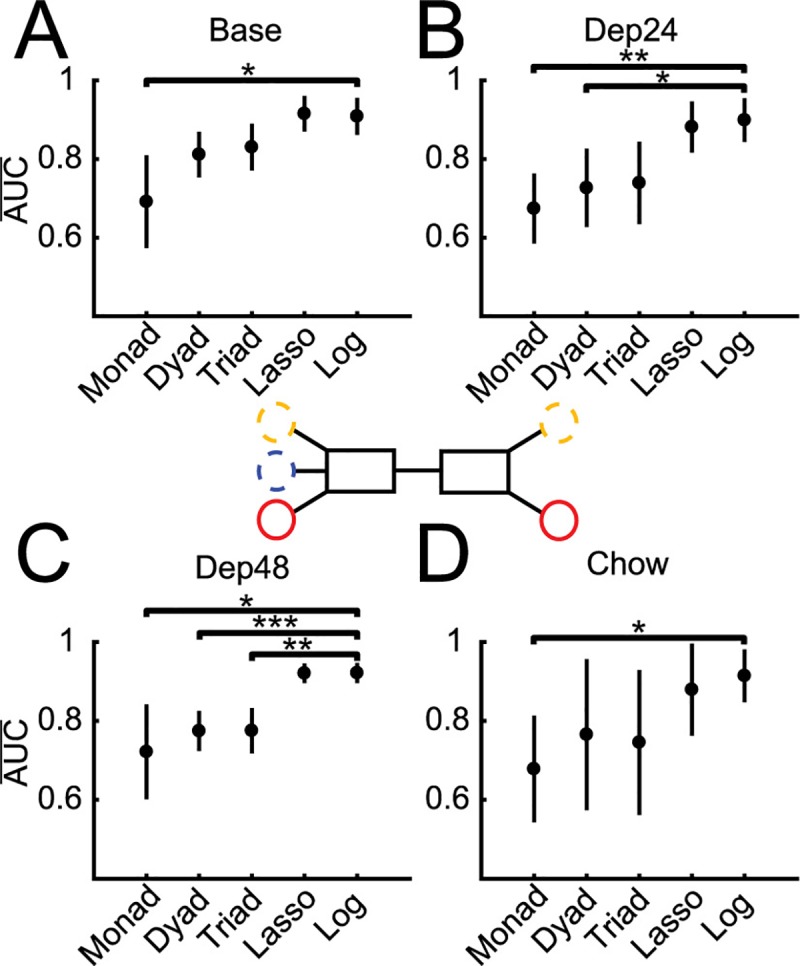
For predicting behavior at Base (A) and Chow (D) two features are sufficient to achieve maximal performance. For Dep24 (B) three features are sufficient and for Dep48 (C) Lasso is required. A. Only Monads have significantly lower performance than the full Log, t(14) = 4.04, p = .019. B. Monads, t(14) = 5.07, p = .0027, and Dyads, t(14) = 3.58, p = 0.049, p = have significantly lower performance than Log. C. Monads, t(14) = 3.85, p = .028, Dyads, t(14) = 6.12, p = .00042, and Triads, t(14) = 5.51, p = .0012, have lower performance than Log. D. Only Monads have significantly lower performance than Log, t(14) = 3.70, p = 0 = .038. * p < .05, ** p < .01, and *** p < .001. Averages represented by circles and 95% confidence intervals by vertical bars.