
Fig. 2. Speaker-independent speech separation with ODAN.
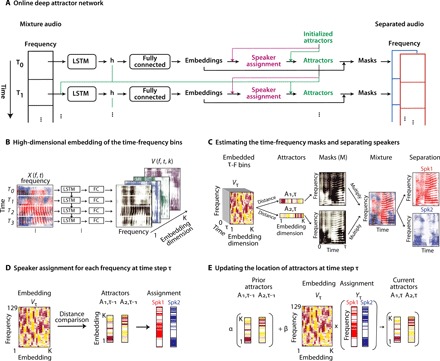
(A) The flowchart of the ODAN for speech separation. (B) The T-F representation of the mixture sound is projected into a high-dimensional space in which the T-F points that belong to the same speaker are clustered together. (C) The center of each speaker representation in the embedding space is referred to as the attractors. The distance between the embedded T-F points and the attractors defines a mask for each speaker that multiplies the T-F representation to extract the speakers. (D) The location of the attractors is updated at each time step. First, the previous location of the attractors is used to determine the speaker assignment for the current frame. (E) Then, the attractors are updated based on a weighted average of the previous attractors and the center of the current frame defined by the speaker assignments.