

Abstract
Scientific theories can often be formulated using equality and order constraints on the relative effects in a linear regression model. For example, it may be expected that the effect of the first predictor is larger than the effect of the second predictor, and the second predictor is expected to be larger than the third predictor. The goal is then to test such expectations against competing scientific expectations or theories. In this paper, a simple default Bayes factor test is proposed for testing multiple hypotheses with equality and order constraints on the effects of interest. The proposed testing criterion can be computed without requiring external prior information about the expected effects before observing the data. The method is implemented in R-package called ‘lmhyp’ which is freely downloadable and ready to use. The usability of the method and software is illustrated using empirical applications from the social and behavioral sciences.
Keywords: Bayes factors, Bayesian hypothesis testing, Equality and order constraints, Regression modeling
Introduction
The linear regression model is the most widely used statistical method for assessing the relative effects of a given set of predictors on a continuous outcome variable. This assessment of the relative effects is an essential part when testing, fine-graining, and building scientific theories. For example, in work and organizational psychology, the regression model has been used to better understand the effects of discrimination by coworkers and managers on workers’ well-being (Johnson et al., 2012); in sociology to assess the effects of the different dimensions of socioeconomic status on one’s attitude towards immigrants (Scheepers, Gijsberts, & Coenders, 2002); and in experimental psychology to make inferences regarding the effects of gender when hiring employees (Carlsson & Sinclair, 2017). Despite the extensive literature on statistical tools for linear regression analysis, methods for evaluating multiple hypotheses with equality and order constraints on the relative effects in a direct manner are still limited. This paper presents a Bayes factor testing procedure with accompanying software for testing such hypotheses with the goal of aiding researchers in the development and evaluation of scientific theories.
As an example, let us consider the following linear regression model where a dependent variable is regressed on three predictor variables, say, X1, X2, and X3:
where yi is the dependent variable of the i-th observation, Xi,k denotes the k predictor variable of the i-th observation, βk is the regression coefficient of the k-th predictor, for k = 1,…,3, β0 is the intercept, and 𝜖i are independent normally distributed errors with unknown variance σ2, for i = 1,…,n.
In exploratory studies, the interest is typically whether each predictor has an effect on the dependent variable, and if there is evidence of a nonzero effect, we would be interested in whether the effect is positive or negative. In the proposed methodology, such an exploratory analysis can be executed by simultaneously testing whether an effect is zero, positive, or negative. For the first predictor, the exploratory multiple hypothesis test would be formulated as
| 1 |
The proposed Bayes factor test will then provide a default quantification of the relative evidence in the data between these hypotheses.
In confirmatory studies, the interest is typically in testing specific hypotheses with equality and order constraints on the relative effects based on scientific expectations or psychological theories (Hoijtink, 2011). Contrasting regression effects against each other using equality or order constraints can be more informative than interpreting them at certain benchmark values (e.g., standardized effects of .2, .5, and 1, are sometimes interpreted as ‘small’, ‘medium’, and ‘large’ effects, respectively) because effects are not absolute but relative quantifications; relative to each other and relative to the scientific field and context (Cohen, 1988). For example, a standardized effect of .4 may be important for an organizational psychologist who is interested in the effect of discrimination on well-being on the work floor but less so for a medical psychologist who wishes to predict the growth of a tumor of a patient through a cognitive test. As such, interpreting regression effects relative to each other using equality and order constraints would be more insightful than interpreting the effects using fixed benchmarks.
In the above regression model for instance, let us assume that β1, β2, and β3 denote the effects of a strong, medium, and mild treatment, respectively. It may then be hypothesized that the effect of the strong treatment is larger than the effect of the medium treatment, the effect of the medium treatment is expected to be larger than the effect of the mild treatment, and all effects are expected to be positive. Alternatively, it may be expected that all treatments have an equal positive effect. These hypotheses can then be tested against a third hypothesis which complements the other hypotheses. This comes down to the following multiple hypothesis test:
| 2 |
Here the complement hypothesis H3 covers the remaining possible values of β1, β2, and β3 that do not satisfy the constraints under H1 and H2. Subsequently, the interest is in quantifying the relative evidence in the data for these hypotheses.
A general advantage of Bayes factors for testing statistical hypotheses is that we obtain a direct quantification of the evidence in the data in favor of one hypothesis against another hypothesis. Furthermore, Bayes factors can be translated to the posterior probabilities of the hypotheses given the observed the data and the hypotheses of interest. These probabilities give a direct answer to the research question which hypothesis is most likely to be true and to what degree given the data. These posterior probabilities can be used to obtain conditional error probabilities of drawing an incorrect conclusion when ‘selecting’ a hypothesis in light of the observed data. These and other properties have greatly contributed to the increasing popularity of Bayes factors for testing hypotheses in psychological research (Mulder & Wagenmakers, 2016).
The proposed testing criterion is based on the prior adjusted default Bayes factor (Mulder, 2014b). The method has various attractive properties. First, the proposed Bayes factor has an analytic expression when testing hypotheses with equality and order constraints in a regression model. Thus, computationally demanding numerical approximations can be avoided, resulting in a fast and simple test. Furthermore, by allowing users to formulate hypotheses with equality as well as ordinal constraints, a broad class of hypotheses can be tested in an easy and direct manner. Another useful property is that no proper (subjective) prior distribution needs to be formulated based on external prior knowledge, and therefore the method can be applied in an automatic fashion. This is achieved by adopting a fractional Bayes methodology (O’Hagan, 1995) where a default prior is implicitly constructed using a minimal fraction of the information in the observed data and the remaining (maximal) fraction is used for hypothesis testing (Gilks, 1995). This default prior is then relocated to the boundary of the constrained space of the hypotheses. In the confirmatory test about the unconstrained default prior for (β1,β3,β3) would be centered around 0. Because this Bayes factor can be computed without requiring external prior knowledge, it is called a ‘default Bayes factor’. Thereby, these default Bayes factors differ from regular Bayes factors where a proper prior is specified reflecting the anticipated effects based on external prior knowledge (e.g., Rouder & Morey, 2015). Other default Bayes factors that have been proposed in the literature are the fractional Bayes factor (O’Hagan, 1995), the intrinsic Bayes factor (Berger & Pericchi, 1996), and the Bayes factor based on expected-posterior priors (Pérez & Berger, 2002; Mulder et al., 2009).
Although various alternative testing procedures are available for hypothesis testing for linear regression analysis, these methods are limited to some degree. First, classical significance tests are only suitable for testing a null hypothesis against a single alternative, and unsuitable for testing multiple hypotheses with equality as well as order constraints (Silvapulle & Sen, 2004). Second, traditional model comparison tools (e.g., the AIC, BIC, or CFI) are generally not suitable for evaluating models (or hypotheses) with order constraints on certain parameters (Mulder et al., 2009; Braeken, Mulder, & Wood, 2015). Third, currently available Bayes factor tests cannot be used for testing order hypotheses (Rouder & Morey, 2015), are not computationally efficient (Mulder, Hoijtink, & de Leeuw, 2012; Kluytmans, van de Schoot, Mulder, & Hoijtink, 2012), or are based on large sample approximations (Gu, Mulder, & Hoijtink, 2018). The proposed Bayes factor, on the other hand, can be used for testing hypotheses with equality and/or order constraints, is very fast to compute due to its analytic expression, and is an accurate default quantification of the evidence in the data in the case of small to moderate samples because it does not rely on large sample approximations. Other important properties of the proposed methodology are its large sample consistent behavior and its information consistent behavior (Mulder, 2014b; Böing-Messing & Mulder, 2018).
The Bayesian test is implemented in the R-package ‘lmhyp’, which is freely downloadable and ready for use in R. The main function ‘test_hyp’ needs a fitted modeling object using the ‘lm’ function together with a string that formulates a set of hypotheses with equality and order constraints on the regression coefficients of interest. The function computes the Bayes factors of interest as well as the posterior probabilities that each hypothesis is true after observing the data.
The paper is organized as follows. Section “A default Bayes factor for equality and order hypotheses in a linear regression model” presents the derivation of the default Bayes factor between hypotheses with equality and order hypotheses on the relative effects in a linear regression model. Section “Software” presents the ‘lmhyp’ package and explains how it can be used for testing scientific expectations in psychological research. Section “Application of the new testing procedure using the software package ‘lmhyp’” shows how to apply the new procedure and software for testing scientific expectations in work and organizational psychology and social psychology. The paper ends with a short discussion.
A default Bayes factor for equality and order hypotheses in a linear regression model
Model and hypothesis formulation
For a linear regression model,
| 3 |
where y is a vector of length n of outcome variables, X is a n × k matrix with the predictor variables, and β is a vector of length k containing the regression coefficients, consider a hypothesis with equality and inequality constraints on certain regression coefficients of the form
| 4 |
where [RE|rE] and [RI|rI] are the augmented matrices with qE and qI rows that contain the coefficients of the equality and inequality constraints, respectively, and k + 1 columns. For example, for the regression model from the introduction, with β = (β0,β1,β2,β3)′, and the hypothesis H1 : β1 > β2 > β3 > 0 in Eq. 2, the augmented matrix of the inequalities is given by
and for the hypothesis H2 : β1 = β2 = β3 > 0, the augmented matrices are given by
The prior adjusted default Bayes factor will be derived for a constrained hypothesis in Eq. 4 against an unconstrained alternative hypothesis, denoted by , with no constraints on the regression coefficients. First, we transform the regression coefficients as follows
| 5 |
where D is a (k − qE) × k matrix consisting of the unique rows of . Thus, ξE is a vector of length qE and ξI is a vector of length k − qE. Consequently, model (3) can be written as
because
where and D− 1 are the (Moore–Penrose) generalized inverse matrices of RE and D, and the hypothesis in Eq. 4 can be written as
| 6 |
because
and
A default Bayes factor for testing hypotheses
The Bayes factor for hypothesis H1 against H2 is defined as the ratio of their respective marginal likelihoods,
The marginal likelihood quantifies the probability of the observed data under a hypothesis (Jeffreys, 1961; Kass & Raftery, 1995). For example, if B12 = 10 this implies that the data were ten times more likely to have been observed under H1 than under H2. Therefore, the Bayes factor can be seen as a relative measure of evidence in the data between two hypotheses. The marginal likelihood under a constrained hypothesis Ht in Eq. 4 is obtained by integrating the likelihood over the order constrained subspace of the free parameters weighted with the prior distribution,
| 7 |
where pt(y|β,σ2) denotes the likelihood of the data under hypothesis Ht given the unknown model parameters, and πt denotes the prior distribution of the free parameters under Ht. The prior quantifies the plausibility of possible values that the model parameters can attain before observing the data.
Unlike in Bayesian estimation, the choice of the prior can have a large influence on the outcome of the Bayes factor. For this reason, ad hoc or arbitrary prior specification should be avoided when testing hypotheses using the Bayes factor. However, specifying a prior that accurately reflects one’s uncertainty about the model parameters before observing the data can be a time-consuming and difficult task (Berger, 2006). A complicating factor in the case of testing multiple, say, 3 or more, hypotheses, is that priors need to be carefully formulated for the free parameters under all hypotheses separately. Because noninformative improper priors also cannot be used when computing marginal likelihoods, there has been increasing interest in the development of default Bayes factors where ad hoc or subjective prior specification is avoided. In these default Bayes factors, a proper default prior is often (implicitly) constructed using a small part of the data while the remaining part is used for hypothesis testing. An example is the fractional Bayes factor (O’Hagan, 1995) where the marginal likelihood is defined by
| 8 |
where the (subjective) proper prior in Eq. 7 is replaced by a proper default prior based on a (minimal) fraction “b” of the observed data,1 and the likelihood is raised to a power equal to the remaining fraction “1 − b”, which is used for hypothesis testing.
In this paper, an adjustment of fractional Bayes factor is considered where the default prior is centered on the boundary (or null value) of the constrained space. The motivation for this adjustment is twofold. First, when testing a precise hypothesis, say, H0 : β = 0 versus H1 : β≠ 0, Jeffreys argued that a default prior for β under H1 should be concentrated around the null value because, if the null would be false, the true effect would likely to be close to the null, otherwise there would be no point in testing H0. Second, when testing hypotheses with inequality or order constraints, the prior probability that the constraints hold serves as a measure of the relative complexity (or size) of the constrained space under a hypothesis (Mulder, Hoijtink, & Klugkist, 2010). This quantification of relative complexity of a hypothesis is important because the Bayes factor balances fit and complexity as an Occam’s razor. This implies that simpler hypotheses (i.e., hypotheses having “smaller” parameter spaces) would be preferred over more complex hypotheses in the case of an approximately equal fit. Only when centering the prior at 0 when testing H1 : β < 0 versus H2 : β > 0, both hypotheses would be considered as equally complex with prior probabilities of .5 corresponding to half of the complete parameter space of β of all real values ().
Given the above considerations, the fractional Bayes factor is adjusted such that the default prior is (i) centered on the boundary of the constrained parameter space and (ii) contains minimal information by specifying a minimal fraction. Because the model consists of k + 1 unknown parameters (k regression coefficients and an unknown error variance), a default prior is obtained using a minimal fraction2 of .
In order to satisfy the prior property (i) when testing a hypothesis (6), the prior for β under the alternative should thus be centered at R− 1r, where R′ = [RE′ RI′] and r′ = (rE′,rI′), which is equivalent to centering the prior for ξ at μ0 = (μE0′,μI0′)′ = TR− 1r = (rE′,μI0′ )′, with R~IμI0 = r~I. The following lemma gives the analytic expression of the default Bayes factor of a hypothesis with equality and order constraints on the regression coefficients versus an unconstrained alternative.
Lemma 1
The prior adjusted default Bayes factors for an equality-constrained hypothesis,H1 : REβ = rE,an order-constrained hypothesis,H2 : RIβ > rI,and a hypothesis with equality and order constraints,H3 : REβ = rE,RIβ > rI,against an unconstrained hypothesisaregiven by
| 9 |
| 10 |
| 11 |
| 12 |
where , t(ξ;μ,S,ν) denotes a Student’s t density for ξ with location parameter μ, scale matrix S, and degrees of freedom ν, is the maximum likelihood estimate (MLE) of β and is the sums of squares, and the (conditional) distributions are given by
with
Proof
Appendix A.
Note that the factors in Eqs. 9 and 12 are multivariate Savage–Dickey density ratio’s (Dickey 1971; Wetzels, Grasman, & Wagenmakers, 2010; Mulder et al., 2010). These ratios have an analytic expression because the marginal posterior and default prior have multivariate Student’s t distributions. In R, these can be computed using the dmvt function in the mvtnorm-package (Genz et al., 2016).
The ratios of (conditional) probabilities in Eqs. 10 and 12 can also be computed in a straightforward manner. If is of full row-rank, then the transformed parameter vector, say, has a Student’s t distribution so that can be computed using the pmvt function from the mvtnorm-package (Genz et al., 2016). If the rank of is lower than qI, then the probability can be computed as the proportion of draws from an unconstrained Student’s t distribution satisfying the order constraints.
The posterior quantities in the numerators reflect the relative fit of a constrained hypothesis, denoted by “f ”, relative to the unconstrained hypothesis: a larger posterior probability implies a good fit of the order constraints and a large posterior density at the null value indicates a good fit of a precise hypothesis. The prior quantities in the denominators reflect the relative complexity of a constrained hypothesis, denoted by “c”, relative to the unconstrained hypothesis: a small prior probability implies a relatively small inequality constrained subspace, and thus a ‘simple’ hypothesis, and a small prior density at the null value corresponds to a large spread (variance) of possible values under the unconstrained alternative implying the null hypothesis is relatively simple in comparison to the unconstrained hypothesis.
Figure 1 gives more insight about the nature of the expressions in Eqs. 9 to 12 in Lemma 1 for an equality constrained hypothesis, H1 : β1 = β2 = 0 (upper panels), an inequality constrained hypothesis, H2 : β > 0 (middle panels), and hypothesis with an equality constraint and an inequality constraint, H3 : β1 > β2 = 0 (lower panels). The Bayes factor for H1 against the unconstrained hypothesis Hu in Eq. 9 corresponds to the ratio of the unconstrained posterior density and the unconstrained default prior (which has a multivariate Cauchy distribution centered at the null value) evaluated at the null value. The Bayes factor for H2 against Hu in Eq. 10 corresponds to the ratio of posterior and default prior probabilities that the constraints hold under Hu. In the case of independent predictors, for example, the prior probability would be equal .25 as a result of centering the default prior at 0. The inequality constrained hypothesis would then be quantified as four times less complex than the unconstrained hypothesis. Finally, for a hypothesis with equality and inequality constraints, H3 : β1 > β2 = 0, the Bayes factor in Eqs. 11–12 corresponds to the ratio of the surfaces of cross section of the posterior and prior density on the line β1 > 0, β2 = 0.
Fig. 1.
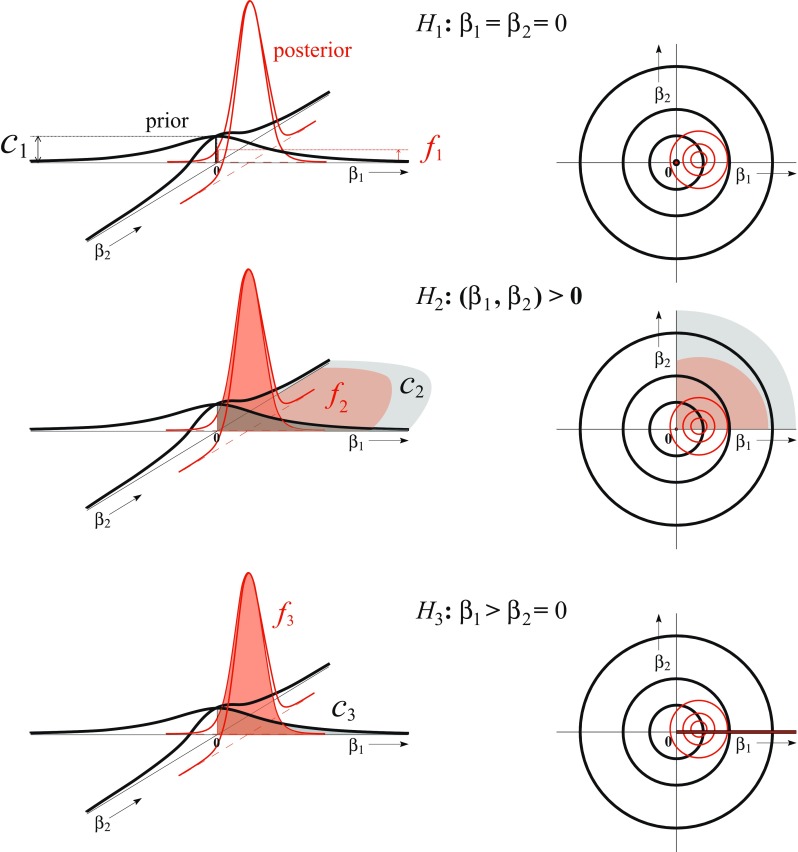
Graphical representation of the default Bayes factor for H1 : β1 = β2 = 0 (upper panels), H2 : β > 0 (middle panels), and H3 : β1 > β2 = 0 (lower panels) as the ratios of the posterior (red thin lines) and prior (black thick lines) density at the null value, the posterior and prior probabilities, and the surfaces of the cross sections of the posterior and prior density, respectively
The default Bayes factors between these hypotheses are computed for a simulated data set with MLEs (Appendix B) that results in B1u = f1Ec1E = 0.061 0.159 = 0.383,B2u = f2Ic2I = 0.546 0.250 = 2.183,B3u = f3Ec3E ×f3I|Ec3I|E = 1.608 0.318 ×0.996 0.500 = 10.061. As will be explained in the next section, it is recommendable to include the complement hypothesis in an analysis. The complement hypothesis covers the subspace of that excludes the subspaces under H1, H2, and H3. In this example, the Bayes factor of the complement hypothesis against the unconstrained hypothesis equals .
After having obtained the default Bayes factor of each hypothesis against the unconstrained hypothesis, Bayes factors between the hypotheses of interest can be obtained through the transitivity property of the Bayes factor, e.g., . This implies that there is strong evidence for H3 relative to H1, as the data were approximately 26 times more likely to have been produced under H3 than under H1.
Once the default Bayes factors of the hypotheses of interest against the unconstrained hypothesis are computed using Lemma 1, posterior probabilities can be computed for the hypotheses. In the case of, say, four hypotheses of interest against, the posterior probability that hypothesis Ht is true can be obtained via
| 13 |
for t = 1, 2, or 3, where Pr(Ht) denotes the prior probability of hypothesis Ht, i.e., the probability that Ht is true before observing the data. As can be seen, the posterior probability is a weighted average of the Bayes factors weighted with the prior probabilities. Throughout this paper, we will work with equal prior probabilities, but other choices may be preferred in specific applications (e.g., Wagenmakers, Wetzels, Borsboom, & van der Maas, 2011). For the example data from Appendix B and Fig. 1, the posterior probabilities would be equal to P(H1|y) = 0.029, P(H2|y) = 0.165, P(H3|y) = 0.760, and P(Hc|y) = 0.046. Based on these outcomes, we would conclude that there is most evidence for H3 that the effect of the first predictor is positive and the effect of the second predictor is zero with a posterior probability of .76. In order to draw a more decisive conclusion (e.g., when obtaining a posterior probability for a hypothesis larger than, say, .99) more data are needed. □
Software
The Bayes factor testing criterion for evaluating equality and order-constrained hypotheses was implemented in a new R package called ‘lmhyp’ to ensure general utilization of the methodology.3 As input, the main function ‘test_hyp’ needs a fitted linear regression modeling object from the lm-function as well as a string that specifies the constrained hypotheses of interest.
As output, the function provides the default Bayes factors between all pairs of hypotheses. By default a complement hypothesis is also included in the analysis. For example, when testing the hypotheses, say, H1 : β1 > β2 > β3 > 0 versus H2 : β1 = β2 = β3 > 0, a third complement hypothesis H3 will be automatically added, which covers the remaining parameter space, i.e., excluding the subspaces under H1 and H2. The reason for including the complement hypothesis is that Bayes factors provide relative measures of evidence between the hypotheses. For example, it may be that H2 receives, say, 30 times more evidence than H1, i.e., B21 = 30, which could be seen as strong evidence for H2 relative to H1, yet it may be that H2 still badly fits to the data in an absolute sense. In this case, the evidence for the complement hypothesis H3 against H2 could be very large, say, B32 = 100.
Besides the default Bayes factor, the function also provides the posterior probabilities of the hypotheses. Posterior probabilities may be easier for users to interpret than Bayes factors because the posterior probabilities sum up to 1. Note that when setting equal prior probabilities between two hypotheses, the posterior odds of the hypotheses will be equal to the Bayes factor. By default, all hypotheses receive equal prior probabilities. Thus, in the case of T hypotheses, then , for t = 1,…,T. Users can manually specify the prior probabilities by using the ‘priorprobs’ argument. In the remaining part of the paper, we will work with the default setting of equal prior probabilities. A step-by-step guide for using the software will be provided in the following section.
Application of the new testing procedure using the software package ‘lmhyp’
In this section, we illustrate how to use the ‘lmhyp’ package to test hypotheses, by applying the procedure to two empirical examples from psychology. We begin by describing the published research. In the two following subsections, we then formulate hypotheses for each example and test these using the function test_hyp from our R-package lmhyp.4
For the first example, we use data from a study of mental health workers in England (Johnson et al., 2012). The data of Johnson et al. measured health workers’ well-being and its correlates, such as perceived discrimination from managers, coworkers, patients, and visitors. Well-being was operationalized by scales measuring anxiety, depression, and job dissatisfaction, the first two scales consisting of three items and the latter of five. The perceived discrimination variables are binary variables that were meant to capture whether the worker believed they had been discriminated against from the four different sources in the last 12 months. This example demonstrates hypothesis testing in regards to single variables and the “exploratory” option of the test_hyp function.
Our second empirical example comes from research by Carlsson and Sinclair (2017). Over four experiments, Carlsson and Sinclair compare two theoretical explanations for perceptions of gender discrimination in hiring, although we use data from only the first experiment (available at https://osf.io/qcdgp/). In this study, Carlsson and Sinclair showed university students two fictive job applications from a man and a woman for a position as either a computer specialist or nurse. Participants were told that the fictive job applications had been sent to real companies as part of a previous study, but that only one of the two applicants had been invited to a job interview despite being equally qualified. A two-item scale was then used to measure participants’ belief the outcome was due to gender discrimination. Several potential correlates were also measured using two-item scales, such as the individual’s belief that (wo)men are generally discriminated against, their expectation that they are gender-stereotyped by others (‘stigma consciousness’) and the extent to which they identify as feminists. This example demonstrates testing hypotheses involving multiple variables.
Hypothesis testing of single effects in organizational psychology
In our first example, we illustrate how our approach might be used to explore competing hypotheses for single variables. It is common when testing the effect of an independent variable in regression to look at whether it is significantly different from zero, or to do a one-sided test of a positive versus a negative effect. When using a Bayes factor test, we can test all these hypotheses directly against each other and compare the relative evidence for each hypothesis.
Braeken et al., (2015) theorized that workplace discrimination has a negative impact on workers’ well-being. Here, we are testing this expectation against a positive effect and a zero effect, while controlling for discrimination from different sources. For example, in the case of discrimination by managers we have
| 14 |
while controlling for discrimination by coworkers, patients, and visitors through the following regression model
where the β’s are the regression effects of the various sources of discrimination on anxiety.
Evaluating these three hypotheses in R is straightforward with the test_hyp function from our R-package lmhyp. This function takes as arguments ‘object’, a fitted object using the lm function, ‘hyp’, a string vector specifying one or several hypotheses (separated by semicolons), ‘priorprob’, specifying the prior probabilities of each hypotheses (by default equal, priorprob = 1), and ‘mcrep’, an integer that specifies the number of draws to compute the prior and posterior probabilities in the (unusual) case the matrix with the coefficients of the order constraints is not of full row rank (by default mcrep= 1e6). In addition, the argument hyp also allows as input the string ”exploratory”, which will test the likelihood of the data for a zero, positive, or negative effect of all variables in the regression model, including the intercept. We will make use of this functionality below, after first discussing how to test the three hypotheses for a single variable. To test the hypotheses, we first fit a linear model on the variables as usual:
fit <- lm(anx ~ discM + discC + discP+ discV, data = dat1)
Next, hypotheses are specified in R as character strings using the variable names from the fitted linear model. It is possible to test the traditional null hypothesis of βmanager = 0 against the two-sided alternative example βmanager≠ 0 by writing
H2 <- "discM = 0"
Note that the complement hypothesis, βmanager≠ 0, is automatically included. However, by testing whether the effect is zero, positive, or negative simultaneously, we obtain a more complete picture of the possible existence and direction of the population effect. This can be achieved by specifying all hypotheses as a single character vector in which the hypotheses are separated by semicolons:
Hyp1v2v3 <- "discM < 0; discM = 0; discM > 0"
Note that spacing does not matter. Once the hypotheses have been specified, they are tested by simply inputting them together with the fitted linear model object into the function test_hyp:
result <- test_hyp(fit, Hyp1v2v3)
This will compute the default Bayes factors from Lemma 1 between the hypotheses, as well as the posterior probabilities for the hypotheses. The posterior probabilities are printed as the primary output:
## Hypotheses:#### H1: "discM<0"## H2: "discM=0"## H3: "discM>0"#### Posterior probability of each hypothesis (rounded):#### H1: 0.000## H2: 0.000## H3: 1.000
As can be seen, the evidence is overwhelmingly in favor of a positive effect of discrimination from managers on anxiety amongst health workers. In fact, when concluding that H3 : βmanager > 0 is true, we would have a conditional error probability of drawing the wrong conclusion of approximately zero. To perform this test for all regression effects, one simply needs to set the second hyp argument equal to "exploratory":
result <- test_hyp(fit, "exploratory")
This option assumes that each hypothesis is equally likely a priori. In the current example, we then get the following output:
## Hypotheses:#### H1: "X < 0"## H2: "X = 0"## H3: "X > 0"#### Posterior probabilities for each variable (rounded),## assuming equal prior probabilities:#### H1 H2 H3## X < 0 X = 0 X > 0## (Intercept) 0.000 0.000 1.000## discM 0.000 0.000 1.000## discC 0.005 0.780 0.216## discP 0.003 0.628 0.369## discV 0.007 0.911 0.082
The posterior probabilities for discrimination by managers are the same as when tested separately. In regards to the other variables, there seems to be positive evidence that there is no effect of discrimination by coworkers, patients, or visitors on anxiety. Note that the evidence for this is not as compelling as for the effect of discrimination by managers, as can be seen from the conditional error probabilities of .216, .369, and .082, respectively, which are quite large. Therefore more data are needed in order to draw more decisive conclusions. Note here that classical significance tests cannot be used for quantifying the evidence in the data in favor of the null; the classical test can only be used to falsify the null. When a null hypothesis cannot be rejected, we are left in a state of ignorance because we cannot reject the null but also not claim there is evidence for the null (Wagenmakers, 2007).
Because the prior probabilities of the hypotheses are equal, the ratio of the posterior probabilities of two hypotheses corresponds with the Bayes factor, e.g., , for the effect of discrimination by coworkers. By calling BF_matrix, we obtain the default Bayes factors between all pairs of hypotheses. For convenience, the printed Bayes factors are rounded to three digits, though exact values can be calculated from the posterior probabilities (unrounded posterior probabilities are available by calling result$post_prob). The Bayes factor matrix for discC (discrimination from coworkers) can be obtained by calling
result\(BF_matrix\)discC## H1 H2 H3## H1 1.000 0.006 0.022## H2 162.367 1.000 3.615## H3 44.913 0.277 1.000
Hence, the null hypothesis of no effect is 162 times more likely than hypothesis H1 which assumes a negative effect (B21 = 162.367), but only 3.6 times more likely than hypothesis H3, which assumes a positive effect (B23 = 3.615). Similar Bayes factor matrices can be printed for all variables when using the “exploratory” option.
To summarize the first application, regressing the effects of perceived discrimination from managers, coworkers, patients, and visitors on the anxiety levels of English health workers, we found very strong evidence for a positive effect of perceived discrimination from managers on anxiety, mild-to-moderate evidence for no effect of discrimination from coworkers, patients, and visitors on anxiety. More research is needed to draw clearer conclusions regarding the existence of a zero or positive effect of these latter three variables.
Hypothesis testing of multiple effects in social psychology
In our second example, we illustrate how our testing procedure can be used when testing multiple hypotheses with competing equal and order constraints on the effect of different predictor variables. Carlsson and Sinclair (2017) compared two different theoretical explanations for perceptions of gender discrimination in hiring for the roles of computer specialist and nurse. To test individual differences, they regressed perceptions of discrimination towards female victims on belief in discrimination against women, stigma consciousness, and feminist identification, while controlling for gender and belief in discrimination against men. As a regression equation, this can be expressed as
where the β’s are standardized regression effects of the variables on perceived discrimination. Since in this subsection we will compare the beta-coefficients of different variables against each other, it facilitates interpretation if they are on the same scale. As such, we standardize all variables before entering them in the model.
The two theories that Carlsson and Sinclair (2017) examined make different explanations for what individual characteristics are most important to perceptions of gender discrimination. The ‘prototype explanation’ suggests that what matters are the individual’s beliefs that the gender in question is discriminated against, whereas the ‘same-gender bias explanation’ suggests that identification with the victim is most important. In our example, the victim of discrimination is female and Carlson and Sinclair operationalize identification with the victim as stigma consciousness and feminist identity. Note that neither theory makes any predictions regarding the control variables (gender and general belief that men are discriminated against). A first hypothesis, based on the prototype explanation, might thus be that belief in discrimination of women in general is positively associated with the belief that the female applicant has been discriminated against, whereas stigma consciousness and feminist identity have no effect on this belief. Formally, this can be expressed as
| 15 |
which is equivalent to:
| 16 |
Alternatively, we might expect all three variables to have a positive effect on the dependent variable (all β’s > 0), but that, in accordance with the prototype explanation, a belief that women are generally discriminated against should have a larger effect on perceptions of discrimination than identifying with the job applicant. Formally this implies:
| 17 |
A third hypothesis, based on the same-gender bias explanation, would be the reverse of the H1, namely that stigma consciousness and feminist identity are positively associated with the outcome while a general belief in discrimination against women has no impact on the particular case. That is:
| 18 |
In this example, we have thus specified three contradicting hypotheses regarding the relationships between three variables and wish to know which hypothesis receives most support from the data at hand. However, there is one additional implied hypothesis in this case: the complement. The complement, Hc, is the hypothesis that none of the specified hypotheses are true. The complement exists if the specified hypotheses are not exhaustive, that is, do not cover the entire parameter space. In other words, the complement exists if there are possible values for the regression coefficients, which are not contained in the hypotheses, for example, (β1,β2,β3) = (− 1,− 1,− 1) is a combination of effects which do not satisfy the constraints of either H1, H2, or H3. Thus, the interest is in testing the following hypotheses:
As before, we begin by fitting a linear regression on the (standardized) variables:
fit <- lm(discW ~ beliefW + stigma+ feminist+ beliefM + gender, data = dat2)
Next, we specify the hypotheses separated by semicolons as a character vector, here on separate lines for space reasons:
hyp1v2v3 <- "beliefW > (stigma,feminist)= 0;beliefW > (stigma, feminist) > 0;(stigma, feminist) > beliefW = 0"
The complement does not need to be specified, as the function will include it automatically if necessary. For this example, we get the following output:
## Hypotheses:#### H1: "beliefW>(stigma,feminist)=0"## H2: "beliefW>(stigma,feminist)>0"## H3: "(stigma,feminist)>beliefW=0"## Hc: "Not H1-H3"#### Posterior probability of each hypothesis (rounded):#### H1: 0.637## H2: 0.359## H3: 0.000## Hc: 0.004
From the output posterior probabilities, we see that H1 and H2, both based on the prototype explanation, received the most support, whereas H3, which was derived from the same-gender bias model, and the complementary hypothesis are both highly unlikely. These results can be succinctly reported as: “Using a default Bayes factor approach, we obtain overwhelming evidence that either hypothesis H1 or H2 is true with posterior probabilities of approximately .637, .359, .000, and .004 for H1, H2, H3, and H4, respectively.” Printing the Bayes Factor matrix yields:
result$BF_{m}atrix## H1 H2 H3 Hc## H1 1.000 1.776 1634.299 163.201## H2 0.563 1.000 920.205 91.892## H3 0.001 0.001 1.000 0.100## Hc 0.006 0.011 10.014 1.000
We see that the evidence for both H1 and H2 is very strong compared to the complement and in particular compared to H3, but that H1 is only 1.8 times as likely as H2 (B12 = 1.777).
To summarize the second application, our data demonstrated strong evidence for the prototype explanation and a lack of support for the same-gender bias explanation in explaining perceptions of discrimination against female applicants in the hiring process of computer specialist and nurses. The relative evidence for the prototype explanation depended on its exact formulation, but was at least 919 times stronger than for the same-gender bias explanation, and 91 times stronger than for the complement. However, further research is required to determine whether identification with a female victim has zero or a positive effect on perceived discrimination.
Supplementary output
When saving results from the test_hyp function to an object it is possible to print additional supplementary output. This output is provided to support a deeper understanding of the method and the primary output outlined in the above subsections. We illustrate these two additional commands using the example in Section “Hypothesis testing of multiple effects in social psychology”. Calling BF_computation prints the measures of relative fit “f ” and complexity “c” in Eqs. 9 – 12 of the Bayes factor of each hypothesis against the unconstrained hypothesis. Thus, for the data and hypotheses of “Hypothesis testing of multiple effects in social psychology” we get
result$BF_computation## c(E) c(I|E) c f(E) f(I|E) f B(t,u) PP(t)## H1 0.151 0.500 0.075 4.398 1.000 4.398 58.265 0.639## H2 NA 0.020 NA NA 0.650 NA 32.525 0.357## H3 0.273 0.201 0.055 0.002 0.985 0.002 0.036 0.000## Hc NA 0.980 NA NA 0.350 NA 0.357 0.004
where c(E) is the prior density at the null value, c(I|E) the prior probability that the constraints hold, c the product of these two, and the columns labeled as f(E), f(I|E), and f have similar interpretations for the posterior quantities. B(t,u) is the Bayes factor of hypothesis Ht against the unconstrained (Hu) and PP(t) is the posterior probability of hypothesis Ht. We rounded the output to three decimals for convenience. Cells with “NA” indicate that a column is “Not Available” to a particular hypothesis. For example, because H2 contains only inequality comparisons it has a prior (and posterior) probability but no prior density evaluated at a null value. Hypothesis H1 and H3 contain both equality and inequality comparisons and thus has both prior and posterior densities and probabilities. The Bayes factor for H1 and H3 against Hu can thus be calculated as B1u = 4.398 0.075 = 58.265 and B3u = 0.002 0.055 = 0.036 (see column B(t,u)). The posterior hypothesis probabilities are calculated using Eq. 13 by setting equal prior probabilities, i.e., , yielding, for example, Pr(H1|y) = 58.265 58.265 + 32.525 + 0.036 + 0.357 = 0.639 (as indicated in column PP(t)).
If RI is not of full row rank, the posterior and prior that the inequality constraints hold are computed as the proportion of draws from unconstrained Student’s t distributions. Under these circumstances, there will be a, typically small, numerical Monte Carlo error. The 90% credibility intervals of the numerical estimate of the Bayes factors of the hypotheses against the unconstrained hypothesis can be obtained by calling
result\InEq{$BFu_{C}I## B(t,u) lb. (5## H1 58.265 58.169 58.360## H2 32.525 32.152 32.910## H3 0.036 NA NA## Hc 0.357 0.356 0.358
where B(t,u) is the Bayes factor of hypothesis t against the unconstrained (u), lb. (5%) is the lower bound of the 90% credibility interval estimate of the Bayes factor and ub. (95%) is the upper bound. Credibility intervals are only printed when the computed Bayes factors have numerical errors. If the user finds the Monte Carlo error to be too large, they can increase the number of draws from the Student’s t distributions by adjusting the input value for the mcrep argument (default 106 draws).
Discussion
The paper presented a new Bayes factor test for evaluating hypotheses on the relative effects in a linear regression model. The proposed testing procedure has several useful properties such as its flexibility to test multiple equality and/or order constrained hypotheses directly against each other, its intuitive interpretation as a measure of the relative evidence in the data between the hypotheses, and its fast computation. Moreover, no prior information needs to be manually specified about the expected magnitude of the effects before observing the data. Instead, a default procedure is employed where a minimal fraction of the data is used for default prior specification and the remaining fraction is used for hypothesis testing. A consequence of this choice is that the statistical evidence cannot be updated using Bayes’ theorem when observing new data. This is common in default Bayes factors (e.g., O’Hagan, 1997; Berger & Pericchi, 2004). Instead, the statistical evidence needs to be recomputed when new data are observed. This, however, is not a practical problem because of the fast computation of the default Bayes factor due to its analytic expression.
Furthermore, the readily available lmhyp-package can easily be used in combination with the popular lm-package for linear regression analysis. The new method will allow researchers to perform default Bayesian exploratory analyses about the presence of a positive, negative, or zero effect and to perform default Bayesian confirmatory analyses where specific relationships are expected between the regression effects which can be translated to equality and order constraints. The proposed test will therefore be a valuable contribution to the existing literature on Bayes factor tests (e.g., Klugkist, Laudy, & Hoijtink, 2005; Rouder, Speckman, Sun, Morey, & Iverson, 2009; Klugkist, Laudy, & Hoijtink, 2010; van de Schoot et al., 2011; Wetzels & Wagenmakers 2012; Rouder, Morey, Speckman, & Province, 2012; Rouder & Morey 2015; Mulder et al., 2012; Mulder 2014a; Gu, Mulder, Decovic, & Hoijtink, 2014; Mulder 2016; Böing-Messing, van Assen, Hofman, Hoijtink, & Mulder, 2017; Mulder & Fox 2018), which are gradually winning ground as alternatives to classical significance tests in social and behavioral research. Due to this increasing literature, a thorough study about the qualitative and quantitative differences between these Bayes factors is called for. Another useful direction for further research would be to derive Bayesian (interval) estimates under the hypothesis that receives convincing evidence from the data.
Acknowledgements
We would like to thank Stephen Wood for allowing us to use the empirical data in the first empirical application in this paper. These data are from the Service Delivery and Organisation (SDO) National Inpatient Staff Morale Study, which was funded by the National Institute for Health Research Service Delivery and Organisation (NIHR SDO) programme (Project Number 08/1604/142) and of which Stephen Wood was a co-investigator. The views and opinions expressed in the article are those of the authors and do not necessarily reflect those of the NIHR SDO programme or the Department of Health. The first author was supported by a NWO Vidi grant (452-17-006).
Appendix A: Proof of Lemma 1
A derivation is given for the prior adjusted default Bayes factor for a hypothesis H1 : REβ = rE,RIβ > rI against an unconstrained hypothesis Hu : β ∈ ℝk in Eq. 9 – 10. Based on the reparameterization ξ = [ ξEξI ] = [ RED ]β in Eq. 5, the hypothesis is equivalent to H1 : ξE = rE,R~IξI > r~I against an unconstrained hypothesis Hu : ξ ∈ ℝk. The marginal likelihood under the constrained hypothesis H1 is defined as in the fractional Bayes factor (O’Hagan, 1995) with the exception that we integrate over an adjusted integration region (Mulder, 2014b; Böing-Messing et al., 2017). This adjustment ensures that the implicit default prior is centered on the boundary of the constrained space. The marginal likelihood under H1 is defined by
| 19 |
As can be seen, the adjustment implies that in the denominator the fraction of the likelihood is evaluated at ξ^E instead of rE and the integration region equals
because R~IμI0 = r~I, instead of R~IξI > r~I. Note that ξ^I = Dβ^. This adjustment of the fractional Bayes factor ensures that the proposed default Bayes factor is computed using an implicit default prior that is centered on the boundary of the constrained space, following Jeffreys’ heuristic argument (see Mulder 2014b, for a more comprehensive motivation). Furthermore, this ensures that the complexity of an order-constrained hypothesis is properly incorporated in the Bayes factor (Mulder, 2014a). The marginal likelihood under Hu is defined by
| 20 |
The fraction b will be set to k+ 1n because k + 1 observations are needs to obtain a finite marginal likelihood when using a noninformative prior πuN(ξE,ξI,σ2) = σ− 2 under Hu.
The default Bayes factor is then given by
| 21 |
Furthermore, using standard calculus it can be shown that the marginal posterior for β for a fraction b of the data and a noninformative prior has a Student’s t distribution
and therefore, because ξ = Tβ|yb, it holds that
where T = [ RED ], ξ^ = (ξ^E′,ξ^I′)′ with ξ^E = REβ^ and ξ^I = Dβ^, and t(ξ;m,K,ν) denotes a Student’s t distribution for ξ with location parameters m, scale matrix K, and ν degrees of freedom. Then it is well known that the marginal distribution of ξE and the conditional distribution of ξI|ξE also have Student’s t distributions (e.g., Press 2005) given by
| 22 |
| 23 |
with
Thus, when plugging in b = 1 and ξE = rE in Eqs. 22 and 23, and then in Eq. 21, gives the numerators in Eqs. 9 and 10, and plugging in b = k+ 1 n and ξE = ξ^E in Eqs. 22 and 23, and then in Eq. 21, gives the denominators in Eqs. 9 and 10, which completes the proof.
Appendix B: Example analysis for Fig. 1
# consider a regression model with two predictors:# y_{i} = beta_{0} + beta_{1} * x1_{i} + beta_{2} * x2_{i} + errorlibrary(lmhyp)n <- 20 #sample sizeX <- mvtnorm::rmvnorm(n,sigma=diag(3))# For this example we transform X to get exact independent# predictor variables and errors. X <- X - rep(1,n)X <- Xerrors <- X[,3] #a population variance of 1X <- X[,1:2]beta <- c(.7,.03) #data generating regression effectsy <- 1 + Xdf1 <- data.frame(y=y,x1=X[,1],x2=X[,2])fit1 <- lm(y~x1+x2,df1)test1 <- test_{h}yp(fit1,"x1=x2=0;(x1,x2)>0;x1>x2=0")test1 #get posterior probabilities test1$}BF_matrix #get Bayes factorstest1\(BF_{c}omputation #get details on the computationstest1\)BFu_CI #get 90
Footnotes
The proper default prior in Eq. 8 is obtained by updating the noninformative improper (independence) Jeffreys’ prior, πN(β,σ2) ∝ σ− 2, with a fraction b of the data: πt(β,σ2|yb) ∝ πN(β,σ2)ft(y|β,σ2)b (Gilks, 1995).
Updating the noninformative Jeffreys prior πN(β,σ) ∝ σ− 2 with a sample of k + 1 observations yields a proper marginal distribution for β having a multivariate Student’s t distribution with 1 degree of freedom, which is equivalent to a multivariate Cauchy distribution.
Run ‘devtools::install_github("jaeoc/lmhyp")’ in R to install the package.
The R-script used to produce the results in this section is available at https://osf.io/g8c9p/
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
J. Mulder, Email: j.mulder3@tilburguniversity.edu
A. Olsson-Collentine, Email: j.a.e.olssoncollentine@tilburguniversity.edu
References
- Berger JO. The case for objective Bayesian analysis. Bayesian Analysis. 2006;1:385–402. doi: 10.1214/06-BA115. [DOI] [Google Scholar]
- Berger JO, Pericchi LR. The intrinsic Bayes factor for model selection and prediction. Journal of the American Statistical Association. 1996;91:109–122. doi: 10.1080/01621459.1996.10476668. [DOI] [Google Scholar]
- Berger JO, Pericchi LR. Training samples in objective Bayesian model selection. The Annals of Statistics. 2004;32(3):841–869. doi: 10.1214/009053604000000238. [DOI] [Google Scholar]
- Böing-Messing F, Mulder J. Automatic Bayes factors for testing equality- and inequality-constrained hypotheses on variances. Psychometrika. 2018;83:586–617. doi: 10.1007/s11336-018-9615-z. [DOI] [PubMed] [Google Scholar]
- Böing-Messing F, van Assen M, Hofman A, Hoijtink H, Mulder J. Bayesian evaluation of constrained hypotheses on variances of multiple independent groups. Psychological Methods. 2017;22:262–287. doi: 10.1037/met0000116. [DOI] [PubMed] [Google Scholar]
- Braeken J, Mulder J, Wood S. Relative effects at work: Bayes factors for order hypotheses. Journal of Management. 2015;41:544–573. doi: 10.1177/0149206314525206. [DOI] [Google Scholar]
- Carlsson R, Sinclair S. Prototypes and same-gender bias in perceptions of hiring discrimination. The Journal of Social Psychology. 2017;158(3):285–297. doi: 10.1080/00224545.2017.1341374. [DOI] [PubMed] [Google Scholar]
- Cohen J. Statistical power analysis for the behavioral sciences. 2nd. Hillsdale: Lawrence Erlbaum; 1988. [Google Scholar]
- Dickey J. The weighted likelihood ratio, linear hypotheses on normal location parameters. The Annals of Statistics. 1971;42:204–223. doi: 10.1214/aoms/1177693507. [DOI] [Google Scholar]
- Genz, A., Bretz, F., Miwa, T., Mi, X., Leisch, F., Scheipl, F., & Hothorn, T. (2016). R-package ‘mvtnorm’ [Computer software manual]. (R package version 1. 14. 4 — For new features, see the ’Changelog’ file (in the package source)).
- Gilks WR. Discussion to fractional Bayes factors for model comparison (by O’Hagan) Journal of the Royal Statistical Society Series B. 1995;56:118–120. [Google Scholar]
- Gu X, Mulder J, Decovic M, Hoijtink H. Bayesian evaluation of inequality constrained hypotheses. Psychological Methods. 2014;19:511–527. doi: 10.1037/met0000017. [DOI] [PubMed] [Google Scholar]
- Gu X, Mulder J, Hoijtink H. Approximated adjusted fractional Bayes factors. A general method for testing informative hypotheses. British Journal of Mathematical and Statistical Psychology. 2018;71(2):229–261. doi: 10.1111/bmsp.12110. [DOI] [PubMed] [Google Scholar]
- Hoijtink H. Informative hypotheses: Theory and practice for behavioral and social scientists. New York: Chapman & Hall/CRC; 2011. [Google Scholar]
- Jeffreys H. Theory of probability-3rd ed. New York: Oxford University Press; 1961. [Google Scholar]
- Johnson S, Osborn D, Araya R, Wearn E, Paul M, Stafford M, Wood S. Morale in the English mental health workforce: Questionnaire survey. British Journal of Psychiatry. 2012;201:239–246. doi: 10.1192/bjp.bp.111.098970. [DOI] [PubMed] [Google Scholar]
- Kass RE, Raftery AE. Bayes factors. Journal of American Statistical Association. 1995;90:773–795. doi: 10.1080/01621459.1995.10476572. [DOI] [Google Scholar]
- Klugkist I, Laudy O, Hoijtink H. Inequality constrained analysis of variance: A Bayesian approach. Psychological Methods. 2005;10:477–493. doi: 10.1037/1082-989X.10.4.477. [DOI] [PubMed] [Google Scholar]
- Klugkist I, Laudy O, Hoijtink H. Bayesian evaluation of inequality and equality constrained hypotheses for contingency tables. Psychological Methods. 2010;15:281–299. doi: 10.1037/a0020137. [DOI] [PubMed] [Google Scholar]
- Kluytmans, A., van de Schoot, R., Mulder, J., & Hoijtink, H. (2012). Illustrating Bayesian evaluation of informative hypotheses for regression models. Frontiers in Psychology, 3, 1–11. 10.3389/fpsyg.2012.00002 [DOI] [PMC free article] [PubMed]
- Mulder, J. (2014a). Bayes factors for testing inequality constrained hypotheses: Issues with prior specification. British Journal of Statistical and Mathematical Psychology, 67, 153–171. [DOI] [PubMed]
- Mulder, J. (2014b). Prior adjusted default Bayes factors for testing (in)equality constrained hypotheses. Computational Statistics and Data Analysis, 71, 448–463.
- Mulder J. Bayes factors for testing order-constrained hypotheses on correlations. Journal of Mathematical Psychology. 2016;72:104–115. doi: 10.1016/j.jmp.2014.09.004. [DOI] [Google Scholar]
- Mulder, J., & Fox, J. P. (2018). Bayes factor testing of multiple intraclass correlations. Bayesian Analysis.
- Mulder, J., Hoijtink, H., & de Leeuw, C. (2012). Biems: A Fortran 90 program for calculating Bayes factors for inequality and equality constrained model. Journal of Statistical Software, 46(2), 46.
- Mulder J, Hoijtink H, Klugkist I. Equality and inequality constrained multivariate linear models: Objective model selection using constrained posterior priors. Journal of Statistical Planning and Inference. 2010;140:887–906. doi: 10.1016/j.jspi.2009.09.022. [DOI] [Google Scholar]
- Mulder, J., Klugkist, I., van de Schoot, A., Meeus, W., Selfhout, M., & Hoijtink, H. (2009). Bayesian model selection of informative hypotheses for repeated measurements. Journal of Mathematical Psychology, 53, 530–546.
- Mulder J, Wagenmakers EJ. Editors’ introduction to the special issue Bayes factors for testing hypotheses in psychological research: Practical relevance and new developments. Journal of Mathematical Psychology. 2016;72:1–5. doi: 10.1016/j.jmp.2016.01.002. [DOI] [Google Scholar]
- O’Hagan A. Fractional Bayes factors for model comparison (with discussion) Journal of the Royal Statistical Society Series B. 1995;57:99–138. [Google Scholar]
- O’Hagan A. Properties of intrinsic and fractional Bayes factors. Test. 1997;6:101–118. doi: 10.1007/BF02564428. [DOI] [Google Scholar]
- Pérez JM, Berger JO. Expected posterior prior distributions for model selection. Biometrika. 2002;89:491–502. doi: 10.1093/biomet/89.3.491. [DOI] [Google Scholar]
- Press S. Applied multivariate analysis: Using Bayesian and frequentist methods of inference. 2nd. Malabar: Krieger; 2005. [Google Scholar]
- Rouder JN, Morey RD. Default Bayes factors for model selection in regression. Multivariate Behavioral Research. 2015;6:877–903. doi: 10.1080/00273171.2012.734737. [DOI] [PubMed] [Google Scholar]
- Rouder JN, Morey RD, Speckman PL, Province JM. Default Bayes factors for ANOVA designs. Journal of Mathematical Psychology. 2012;56(5):356–374. doi: 10.1016/j.jmp.2012.08.001. [DOI] [Google Scholar]
- Rouder JN, Speckman PL, Sun D, Morey RD, Iverson G. Bayesian t tests for accepting and rejecting the null hypothesis. Psychonomic Bulletin & Review. 2009;16:225–237. doi: 10.3758/PBR.16.2.225. [DOI] [PubMed] [Google Scholar]
- Scheepers P, Gijsberts M, Coenders M. Ethnic exclusion in European countries: Public opposition to civil rights for legal migrants as a response to perceived ethnic threat. European Sociological Review. 2002;18:17–34. doi: 10.1093/esr/18.1.17. [DOI] [Google Scholar]
- Silvapulle MJ, Sen PK. Constrained statistical inference: Inequality, order and shape restrictions. 2nd. Hoboken: Wiley; 2004. [Google Scholar]
- van de Schoot, R., Mulder, J., Hoijtink, H., van Aken, M. A. G., Semon Dubas, J., Orobio de Castro, B., & Romeijn, J. W. (2011). An introduction to Bayesian model selection for evaluating informative hypotheses. European Journal of Developmental Psychology, 8, 713–729.
- Wagenmakers EJ. A practical solution to the pervasive problem of p values. Psychonomic Bulletin and Review. 2007;14:779–804. doi: 10.3758/BF03194105. [DOI] [PubMed] [Google Scholar]
- Wagenmakers EJ, Wetzels R, Borsboom D, van der Maas HLJ. Why psychologists must change the way they analyze their data: The case of psi. Journal of Personality and Social Psychology. 2011;100:426–432. doi: 10.1037/a0022790. [DOI] [PubMed] [Google Scholar]
- Wetzels R, Grasman RPPP, Wagenmakers EJ. An encompassing prior generalization of the Savage–Dickey density ratio test. Computational Statistics and Data Analysis. 2010;38:666–690. [Google Scholar]
- Wetzels R, Wagenmakers EJ. A default Bayesian hypothesis test for correlations and partial correlations. Psychonomic Bulletin & Review. 2012;19:1057–1064. doi: 10.3758/s13423-012-0295-x. [DOI] [PMC free article] [PubMed] [Google Scholar]