
Fig. 3.
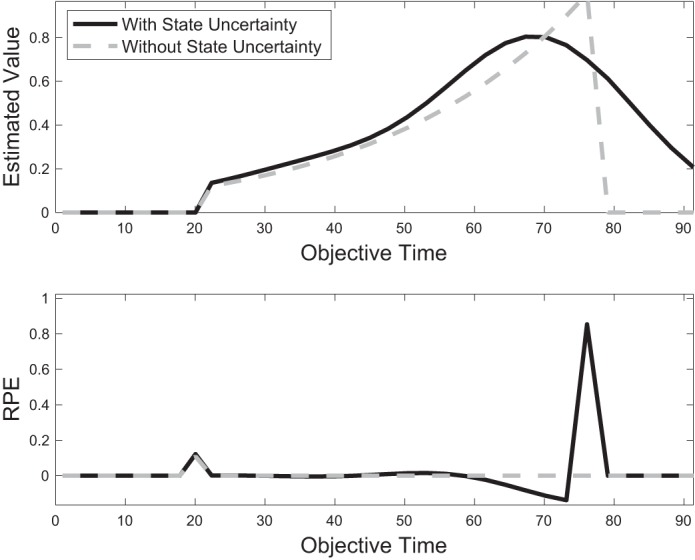
Effect of state uncertainty on value estimation and reward prediction error (RPE). With a perfectly learned value function (top, gray), δτ reduces to zero throughout the entire trial duration (bottom, gray). With state uncertainty, implemented by an overlapping feature set, value cannot be estimated perfectly (top, black), and δτ is nonzero even after extensive learning (bottom, black). (Figure for illustration only. For smaller T or larger γ, the initial phasic RPE can be larger than RPE at reward time, illustrated here at t = 20 and t = 75, respectively.)