
Fig. 4.
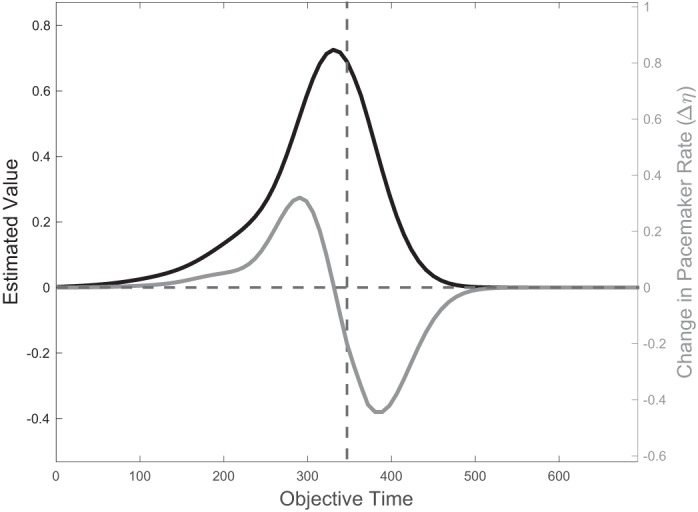
Bidirectional learning rule for η. Because of feature overlap, the learned value V̂ (black curve, plotted here against objective time) does not drop immediately to zero after reward time T (dashed vertical line). This gradual decrease allows its derivative to be negative over a nonzero domain of time, which in turn allows the update rule for η in Eq. 6 to take negative values over that same domain. It follows that η increases if reward is delivered roughly before T and decreases if reward is delayed past T (gray curve).