
Figure 3.
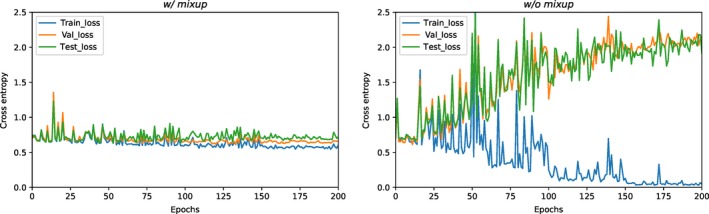
The learning curves of the best models with mixup training and those without, in terms of binary cross‐entropy loss. The losses on the HdH training, development (val) set and test Dataset were shown on the figures. “epochs” on the x‐axis means the training consumes once the entire training set