
Figure 6.
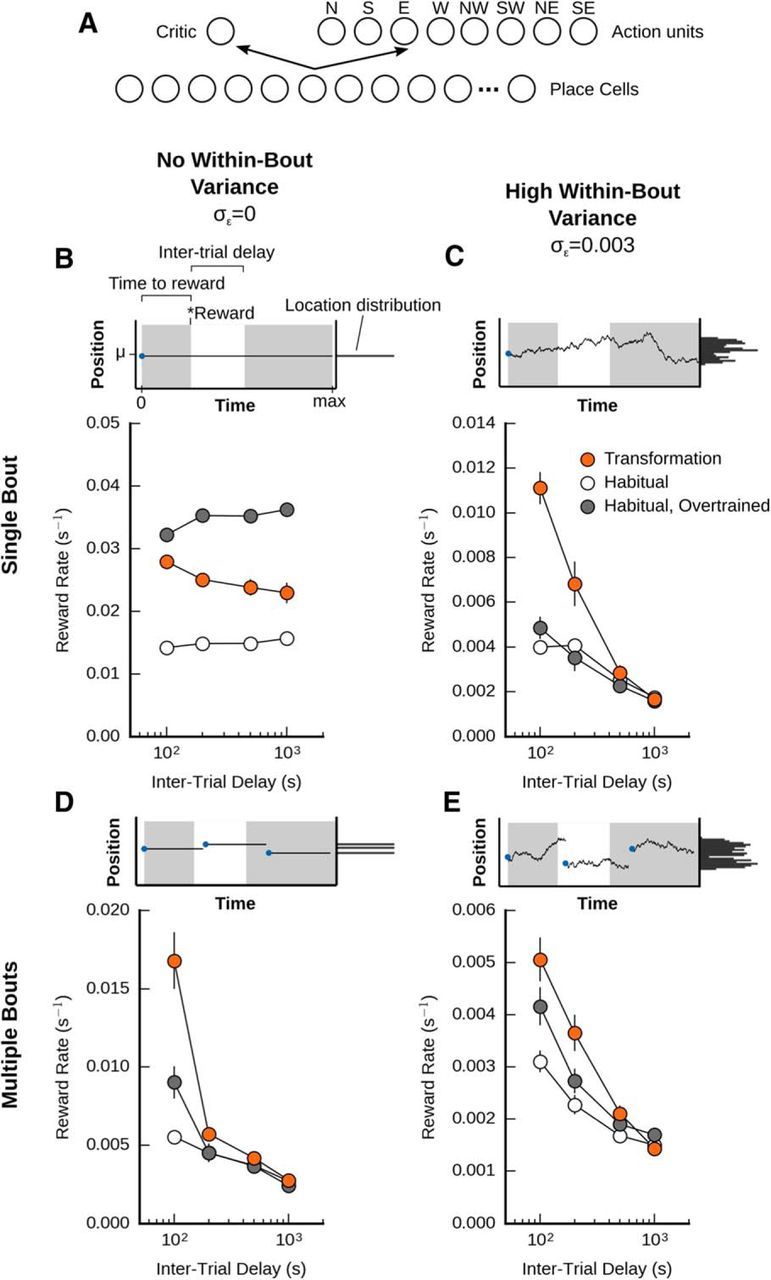
A habitual agent is not as effective at foraging as the memory transformation agent in a variable environment. A, Illustration of the habitual agent architecture. The agent with memory transformation was pitted against a habitual (model-free) system, composed of place cells that interacted with a critic, which learned a value function, and an actor that learned a place-to-action function. B, Performance of the agents when the reward location was constant. When tasked to find a stationary reward within a single bout, the habitual system with 400 trials of extra training outperforms an episodic model-based system, which in turn outperforms a model-free system that received an equivalent amount of training. C, Performance of the agents with some within-bout variance (incremental changes), but no new bouts (i.e., no between-bout variance). D, Performance of the agents with no within-bout variance, but some between-bout variance (i..e. multiple bouts). E, Performance of the agents with both between-bout and within-bout variance.