
Fig. 1.
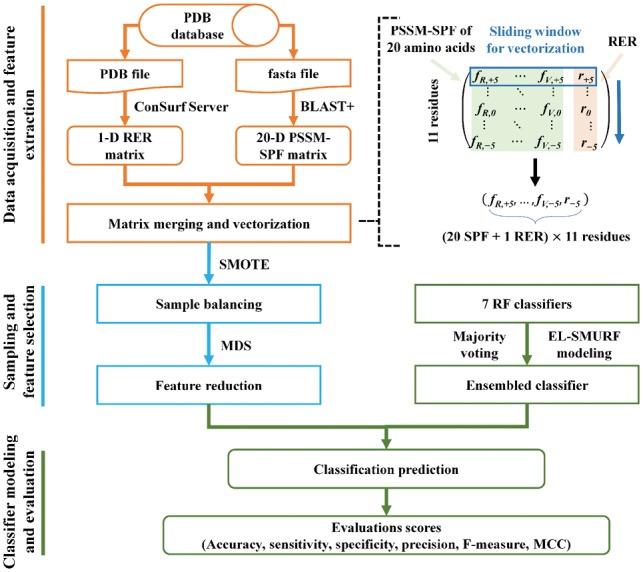
The flowchart of EL-SMURF with three steps: (A) Data acquisition and feature extraction. The PDB file and the FASTA file are downloaded from the PDB database, and the feature subsets of protein sequences are obtained by the combination of RER features and PSSM-SPF where a 231-D subset can be obtained by the sliding window. (B) Sampling and feature selection. A small number of samples (interface residues) were oversampled by SMOTE algorithm to get the balanced samples, and the MDS was used to reduce the feature redundancy and improve the classification performance. (C) Classifier modeling and classification. Using the optimal feature subset as the input vector, the majority voting method is used as the ensemble learning strategy to integrate the RF classifier and construct the integrated learning model EL-SMURF. The comparison of Acc, Se, Sp, Pr, F-Measure and MCC was carried out among several classifiers and prediction methods