
Figure 1.
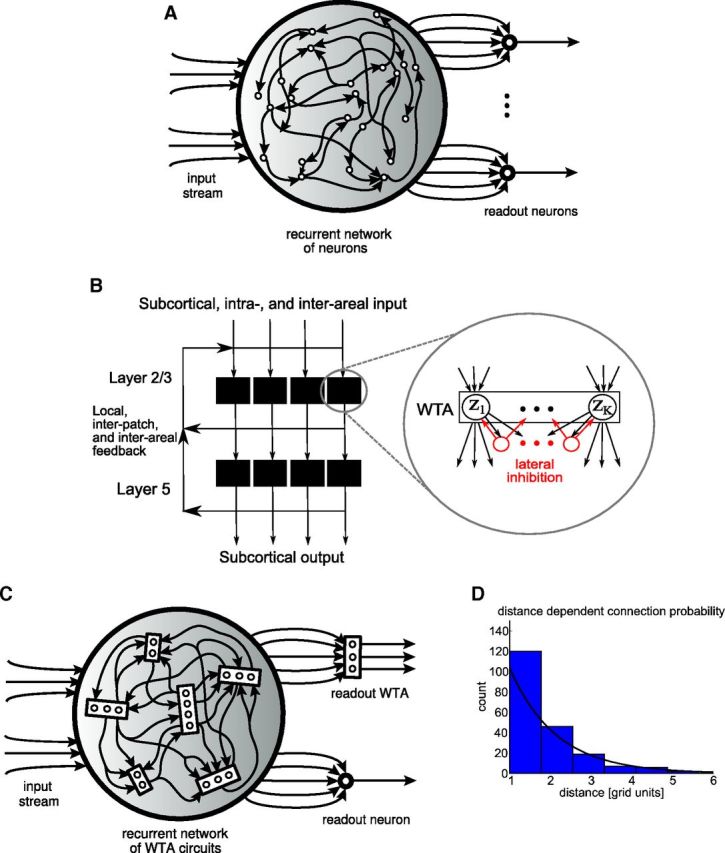
Traditional and modified liquid computing model. A, Traditional liquid computing model. B, More structured generic microcircuit model from Douglas and Martin (2004): a recurrent network of WTA circuits on superficial and deep layers. C, Resulting modified liquid computing model: a recurrent network of WTA circuits. Each WTA circuit is assumed to be positioned on a grid point of a 2D grid to define a spatial distance between them. Each WTA circuit consists of some randomly drawn number K of stochastically spiking excitatory neurons zK that are subject to lateral inhibition. WTA circuits within the network receive spike inputs from randomly selected excitatory neurons in other WTA circuits in the network and from the external input to the network. We will focus in the “Liquid computing with long-term memory” section (Fig. 10) on WTA circuits as readouts that do not require a teacher for learning (linear readouts trained by linear regression with the help of a teacher, as in the traditional liquid computing model, are only considered for control experiments in Fig. 12). D, Smooth line shows the distance-dependent connection probability λexp(−λd) between any two excitatory neurons in two WTA circuits at distance d. A histogram of resulting connections for a typical network is also shown.