

Abstract
The ability to perform complex sequences of movements quickly and accurately is critical for many motor skills. Although training improves performance in a large variety of motor sequence tasks, the precise mechanisms behind such improvements are poorly understood. Here we investigated the contribution of single-action selection, sequence preplanning, online planning, and motor execution to performance in a discrete sequence production task. Five visually presented numbers cued a sequence of five finger presses, which had to be executed as quickly and accurately as possible. To study how sequence planning influenced sequence production, we manipulated the amount of time that participants were given to prepare each sequence by using a forced-response paradigm. Over 4 days, participants were trained on 10 sequences and tested on 80 novel sequences. Our results revealed that participants became faster in selecting individual finger presses. They also preplanned three or four sequence items into the future, and the speed of preplanning improved for trained, but not for untrained, sequences. Because preplanning capacity remained limited, the remaining sequence elements had to be planned online during sequence execution, a process that also improved with sequence-specific training. Overall, our results support the view that motor sequence learning effects are best characterized by improvements in planning processes that occur both before and concurrently with motor execution.
NEW & NOTEWORTHY Complex skills often require the production of sequential movements. Although practice improves performance, it remains unclear how these improvements are achieved. Our findings show that learning effects in a sequence production task can be attributed to an enhanced ability to plan upcoming movements. These results shed new light on planning processes in the context of movement sequences and have important implications for our understanding of the neural mechanisms that underlie skill acquisition.
Keywords: discrete sequence production, motor planning, sequence learning
INTRODUCTION
Many everyday skills require the production of sequences of individual movements. For example, typing on a computer keyboard consists of producing serially ordered sequences of finger presses. Whereas novices tend to type slowly, taking time to select every single press and frequently going back to correct their mistakes, experts can type quickly and flawlessly, executing a series of presses in one fluid motion. What makes this transformation possible? How do we learn complex dexterous skills such as typing or playing the piano?
Since the early 1950s the discrete sequence production (DSP) task (Fig. 1A) has been used as a model to study the acquisition of skilled motor sequences (see Abrahamse et al. 2013 for a recent review). Participants are typically presented with visual stimuli (e.g., numbers or other symbols) and asked to execute the corresponding responses (e.g., finger presses or reaches) as quickly and accurately as possible. Although it is known that systematic behavioral training improves performance in sequence execution, the exact processes involved in these behavioral changes remain elusive (Diedrichsen and Kornysheva 2015; Doyon et al. 2018; Wong et al. 2015b).
Fig. 1.

Discrete sequence production task. A: visual stimuli (e.g., numbers) instruct both which fingers to use and in what order (left to right). After a reaction time (RT), 5 key presses are executed (see force traces). B: preplanning takes place during the RT (i.e., before movement onset); online planning occurs in parallel with motor sequence execution (i.e., after movement onset).
Here we sought to characterize the components that underlie the performance improvements in sequence production. Specifically, we attempted to separate processes that occur before the start of the sequence and processes that occur during the execution of the sequence (Fig. 1B).
The first component that we considered is that participants may become better at identifying a stimulus (e.g., a number) and selecting the correct response (e.g., a finger press). With training, participants could become quicker and more accurate at performing this mapping (Haith et al. 2016; Hardwick et al. 2017), which would speed up both their reaction time (RT) and sequence execution. We collectively refer to improvements in stimulus identification or stimulus-response (S-R) mapping as single-item selection.
Although it is possible to perform sequences by selecting and executing one action at a time, participants may also preselect multiple elements before execution. This preplanning of multiple elements would make sequence production faster by removing the requirement of action selection during the execution phase. Note that for the purpose of this study we cannot clearly distinguish between action selection and motor planning. Although planning often implies the specification of details of movement beyond merely identifying it, our experimental paradigm does not allow us to make this distinction. Instead, here we use “selection” to refer to the selection and planning of one element at a time and “preplanning” as the process of selecting and planning multiple movements in parallel. Selection also includes the perceptual processes necessary to identify each digit.
If preplanning of the full sequence is not possible (e.g., because of the sequence being too long or preparation time being too short), participants must be able to plan the rest of the sequence “on the go.” Thus action selection processes would need to run in parallel to the execution of the first elements. We refer to this component as online planning.
Finally, motor sequence learning can take place at the level of execution processes that are unrelated to selection or planning (Diedrichsen and Kornysheva 2015; Shmuelof et al. 2012; Wong et al. 2015b). This could manifest as an improved ability to press and quickly release a single key or to transition from one preplanned key press to the next. We call this component motor execution.
To dissociate the influence of these different components to overall speed improvements in motor sequence production, we trained participants with 10 five-item sequences of finger presses. We combined the DSP task with a forced-response paradigm (Ghez et al. 1997; Haith et al. 2016; see methods) that enabled us to experimentally manipulate the amount of time to preplan a given sequence. We thus investigated how many items participants could preplan in advance and how long this process took. We also established the speed of single-item selection, using the same forced-response paradigm in a single-response task. Overall our experiment was designed to break down motor sequence performance into its component processes and to investigate how each process changed with learning.
METHODS
Participants
Twenty right-handed volunteers (5 men, 15 women; age range 18–33 yr, average 22.30 yr, SD = 4.24) participated in the training experiment (see Experiment Paradigm) in exchange for monetary compensation. Handedness was verified with the Edinburgh Handedness Inventory (average score 87.25, SD = 14.46). Fifteen subjects (4 men, 11 women; average age 22.47 yr, SD = 4.67) participated in the retention test (see Experiment Paradigm) roughly 3 mo after the last training day (average time difference 82 days, SD = 15.16). The experimental procedures were reviewed and approved by the local ethics committee at Western University, and all participants provided written informed consent. None of the participants was a professional musician (average musical experience 3.88 yr, SD = 3.82) or had any history of neurological disorder.
Apparatus and Stimuli
Sequences of finger presses were executed on a piano-like keyboard device (as shown in Fig. 1A) comprised of five keys equipped with force transducers (FSG-15N1A, Sensing and Control; Honeywell; dynamic range, 0–25 N) that measured isometric force presses exerted by each finger with an update rate of 2 ms. To account for sensor drifts, a zero-force baseline was recalibrated at the beginning of each block. A key press was recognized when the sensor force exceeded a press threshold of 1 N (see, e.g., Fig. 1A). A key was considered released when the force returned below 1 N (e.g., Fig. 1A). The device was custom built and has been described in detail previously (Kornysheva and Diedrichsen 2014; Wiestler and Diedrichsen 2013; Yokoi et al. 2017, 2018). The stimuli consisted of white numeric characters on a black background framed by a white rectangle (as shown in Fig. 1A) presented on a computer display (stimuli height 1.5 cm; visual angle ~2°).
DSP Task
A DSP task required participants to make isometric force presses with the fingers of their right hand. The instructing stimulus was a five-item sequence cue (a string of numbers ranging from 1 to 5) that indicated, from left to right, the order in which the fingers had to be pressed (e.g., 1 = thumb, 5 = little finger). Once present on the screen, the stimuli remained visible for the entire duration of the trial; thus participants had always full explicit knowledge of the sequence of finger presses to be executed. Participants were instructed to complete the sequence as quickly and accurately as possible. Performance was evaluated in terms of both speed and accuracy in sequence production. Speed was quantified by execution time (ET), defined as the time from the first key press to the release of the last key press (Fig. 2A). With each press, the corresponding white number turned either green for correct responses or red for erroneous responses (Fig. 2A, top). A single press error in the sequence, or timing error on the first press, invalidated the whole trial, so accuracy was calculated as percent error rate (ER) per block of trials (i.e., number of error trials/number of total trials × 100). In the case of an error, participants were instructed to complete the sequence and move on to the next trial. After the entire sequence was completed, performance points appeared on the screen, replacing the sequence cues (Fig. 2A, top right; see Feedback) during 500 ms of intertrial interval before moving on to the next trial.
Fig. 2.

Experimental task and paradigm. A: a series of 4 audio-visual signals (800 ms apart) specifies the timing of movement initiation (vertical arrow) within the acceptable response window. Sequence cues appear at 1 of 4 time points (yellow dots) before the 4th signal (preparation phase). After completing the sequence (execution phase), participants receive points depending on their performance. Colored lines illustrate schematic force traces for the 5 finger presses in a sequence. The horizontal dotted line denotes the force threshold for a press/release. Vertical lines indicate press onsets (IPI 1 = 1st interpress interval). The vertical dashed line represents the release of the last press (end of the execution phase). DSP, discrete sequence production; RT, reaction time; ET, execution time; ITI, intertrial interval. B, left: the training experiment (n = 20, 15 women, 5 men) consisted of 4 days of training on single-response (green), sequence training (blue), and random-sequences (orange) blocks. Right: after ~3 mo we called the same participants back for a retention test (n = 15, 11 women, 4 men) with blocks of trials including trained (blue), untrained (orange), or mixed trained-untrained (striped) sequences. Mixed blocks contained 30 trained and 10 untrained sequences presented in random order. We also alternated the Forced-RT (FC) and Free-RT (FR) paradigms every 2 blocks. The initial paradigm was counterbalanced across participants.
Forced-RT Paradigm
To manipulate sequence preparation time, we combined the DSP task with a forced-reaction time (Forced-RT) paradigm (see, e.g., Ghez et al. 1997; Haith et al. 2016).
On each trial, a fully predictable series of four regularly paced auditory tones (800 ms apart; Fig. 2A, bottom) cued the time of movement initiation. Participants were trained to press the first finger of the sequence as synchronously as possible with the fourth tone. The informative sequence cue (i.e., the numbers on the screen) could appear 400, 800, 1,600, or 2,400 ms before the fourth tone (Fig. 2A), giving participants variable time to plan the whole sequence before making the first press. To increase the salience of the Forced-RT paradigm, the tones were accompanied by visual cues (4 horizontally aligned white squares on black background, each turning yellow in synchrony with an auditory tone; Fig. 2A, top). A response window of 200 ms centered on the fourth tone (i.e., up to 100 ms before and 100 ms after the tone) defined the acceptable range of response times for the first press to count as correct timing. In case of a timing error, participants received immediate visual feedback, with the words “Early” or “Late” appearing on the screen above the sequence cue. This paradigm enabled us to manipulate the amount of time available for sequence preplanning (Fig. 1B) and indirectly assess the amount of sequence planning by forcing participants to start the sequence at faster-than-normal RTs, while measuring their performance as a function of the imposed preparation time (Haith et al. 2016).
For single-response blocks (Fig. 2B; see Experiment Paradigm), participants were presented with five numbers but were asked to only focus on the first (a number from 1 to 5), ignore the other four (filler numbers from 6 to 9 and 0), and produce the corresponding single finger press in synchrony with the fourth tone. Because single-item selection is faster than sequence preplanning, the preparation times in the single-response blocks ranged from 200 ms to 650 ms before the fourth tone in 10 steps of 50 ms.
Feedback
To motivate participants to improve further in sequence production speed once they became comfortable with the task, we provided them with feedback about their performance throughout each training and testing session.
At the end of each trial, participants received a performance score according to the following point system: −3 points for large timing errors (i.e., >300 ms before or after the last tone); −1 point for small timing errors (i.e., between 300 and 100 ms before or after the last tone); 0 points for correct timing (i.e., <100 ms before or after the last tone) but wrong finger press; +1 point for correct timing and press but ET ≥20% higher than upper ET threshold; +2 points for correct timing and press but ET between upper and lower ET thresholds; and +3 points for correct timing and press and ET ≥5% lower than lower ET threshold. Upper and lower ET thresholds determining the performance score would decrease from one block to the next if both of the following performance criteria were met: median ET in the last block faster than best median ET so far in the session and mean ER in the last block <30%. If either one of these criteria was not met, the thresholds for the next block remained unchanged (i.e., the same as previous block). At the end of each block of trials, the median ET, mean ER, and points earned were displayed to the participants.
The point system remained identical for single-response blocks (Fig. 2B; see Experiment Paradigm), with the exception that there was no sequence execution speed (i.e., no ET) but only finger selection accuracy. Thus making the correct finger press with correct timing directly produced +3 points. Given the shorter preparation time allowed in single-response blocks, we warned participants that the task was supposed to be challenging and that if they felt that they did not have enough time to plan the correct press they should randomly choose which finger to press, as it would be more beneficial for them to guess wrong at the right time (0 points) than to respond correctly with incorrect timing (negative points).
Experiment Paradigm
The present study was composed of two parts: a training experiment and a retention test (Fig. 2B).
Training experiment.
The main purpose of the training experiment was to examine the effects of training and preparation time (and their interaction) on single-response selection and sequence production. Sequence training was manipulated by using the DSP task and two nonoverlapping sets of five-item sequences: a set of 10 repeating sequences (trained sequences; each sequence presented 40 times per day, in random order) and a set of 80 novel sequences (untrained sequences; each sequence only presented once per day, in random order). The two sets of sequences were matched for probability of first-order finger transitions, i.e., how often a specific finger followed another specific finger. Thus differences between trained and untrained sequences cannot be attributed to simple differences in learning such first-order transitions. Each testing session of the training experiment (1 per day over 4 days) consisted of 14 blocks of trials performed in the following order: 2 single-response blocks (50 trials each), 10 sequence training blocks (40 trials each, trained sequences only), and 2 random sequences blocks (40 trials each, untrained sequences only). Single-response blocks were intended to assess eventual performance improvements in single-finger selection accuracy as a function of preparation time. Sequence training blocks served to train participants on the finger movements associated with each sequence in the set of trained sequences (i.e., to develop sequence-specific learning). Random sequences blocks were used to test sequence production performance on a novel set of untrained sequences.
Retention test.
Roughly 3 mo after the last session of the training experiment, we called participants back for a retention test. The main purpose of this retention test was to check 1) whether the components of sequence learning identified in the training experiment were stable or susceptible to forgetting and 2) whether the results obtained in the training experiment would replicate even when using a Free-RT paradigm (i.e., no time pressure requirements to start the sequence) or when mixing trained and untrained sequences within the same block. The retention test consisted of 16 blocks of sequence production in which we alternated the Forced-RT paradigm with a Free-RT paradigm every 2 blocks (the first paradigm type, whether Free- or Forced-RT, was counterbalanced between subjects). Each block could be a block of trained sequences (3 blocks per paradigm, 40 trials each), a block of untrained sequences (1 block per paradigm, 40 trials each), or a Mixed block (4 blocks per paradigm, 40 trials each: 30 trials of trained sequences and 10 trials of untrained sequences randomly interleaved), following the order shown in Fig. 2B, right. The sets of trained and untrained sequences, the preparation time levels, and the point system for feedback on performance remained identical to those in the training experiment. Additionally, to test for explicit sequence memory retention, both before and after the sequence production task we administered a questionnaire that included both free sequence recall (e.g., “fill in the numbers for each of the 10 repeating sequences—if you don’t remember, guess”) and sequence recognition tests (e.g., “for each of the following 30 sequences, indicate whether it was one of the repeating or novel sequences—if unsure, guess”).
Data Analysis
All data were analyzed off-line with custom code written in MATLAB (The MathWorks, Natick, MA). To assess behavioral improvements in the single-response task, for each subject and training day, we calculated the mean finger selection accuracy as a function of preparation time. For this analysis we considered only trials in which the timing had been correct (i.e., press within the response window). To quantify improvements in mean finger selection accuracy (an indirect measure of single-item selection speed), we fitted the data from each training day to the following logistic function, separately for each subject:
where is the predicted finger selection accuracy for trial n; xn is the manipulated preparation time; and a and b are free parameters determining, respectively, the steepness of the function at the midpoint and the location of the midpoint on the x-axis (i.e., the preparation time where the midpoint occurs). The offset c = 0.2 constrained the logistic function to range between 0.2 (chance selection accuracy) and 1. The parameters a and b were then fitted to the data of each day separately using MATLAB’s fminsearch routine to minimize the Bernoulli loss function:
where y is the observed and y′ the predicted selection accuracy. Because of poor performance in single-response blocks and an insufficient number of trials for some of the conditions, the data from one subject could not be fitted and were therefore excluded from this analysis (thus n = 19).
Statistical analyses to assess sequence-general and sequence-specific learning and improvements in sequence preplanning speed included two-tailed paired-samples t-tests and a within-subject repeated-measures ANOVA with factors training and preparation time. Error trials (both timing and press errors) were excluded from this analysis. Additionally, as a visual aid to the interaction between preparation time and training, we plotted the ET of trained and untrained sequences in terms of percentage of the ET for the longest preparation time (2,400 ms). This allowed us to show the benefit of longer preparation times as gain in sequence execution speed while directly comparing trained and untrained sequences.
Finally, for each participant, explicit sequence-memory retention was quantified as mean free sequence-recall accuracy, and mean d′ was taken as a measure of sensitivity in sequence recognition.
RESULTS
Training Leads to Sequence-Specific and Sequence-General Learning
Improvements in speed were observed both for trained as well as for novel, untrained sequences. From the first to the last training day, participants improved their average ET from 1,564 ± 131 ms to 1,288 ± 94 ms even on untrained sequences (t19 = 5.029, P = 7.456e-05; Fig. 3A), demonstrating sequence-general learning. To determine the amount of sequence-specific learning, we compared the performance on the two untrained blocks at the end of each day to the two preceding blocks of trained sequences. On the fourth day, we observed that participants executed trained sequences significantly faster than untrained sequences (trained: 958 ± 75 ms, untrained: 1,288 ± 94 ms, t19 = 9.637, P = 9.523e-09; Fig. 3A) while maintaining comparable accuracy levels (trained: 77.5 ± 2.5%, untrained: 79.3 ± 2.2%, t19 = 0.962, P = 0.348; Fig. 3B; average proportion of timing errors: trained 14.8 ± 1.4%, untrained 15.6 ± 1.6%). Thus, in addition to the substantial improvement even for the execution of untrained sequences, participants showed a 330-ms advantage for trained sequences.
Fig. 3.

Sequence-general and sequence-specific learning. A: mean sequence execution time plotted as a function of block number separately for trained and untrained sequences. Vertical dotted lines demarcate the beginning and the end of each testing session (1 per day). Shaded areas indicate SE. B: mean sequence execution accuracy (among trials with correct timing) as a function of training day separately for trained and untrained sequences. Shaded areas indicate SE. C: mean press duration (light colors) and average delay between presses (dark colors) as a function of block number separately for trained and untrained sequences. Other conventions are the same as in A.
We also investigated whether the decrease in ET was caused by participants producing faster individual presses (i.e., shorter press-to-release durations) or whether they used less time between presses (i.e., shorter release-to-press delays). Figure 3C shows that the great majority of ET was composed of press-to-release durations, whereas release-to-press delays gradually decreased. At the end of training, many presses overlapped considerably, leading to negative press delays. Furthermore, press durations tended to be shorter for untrained than for trained sequences. This means that participants did not improve their overall speed by shortening their press durations. Rather, they may have strategically produced longer presses and optimized the execution of the sequence by binding together consecutive presses.
Single-Item Selection Becomes Quicker with Practice
One factor that may underlie sequence-general learning effects is an improved ability to associate each number with the corresponding finger. We measured this ability with a forced-response paradigm on single-item selection. Consistent with previous results (Haith et al. 2016; Hardwick et al. 2017), we found that participants were able to select the correct finger with increasing probability for shorter preparation times (Fig. 4A). In this analysis, timing errors (22.5 ± 1.9%) were excluded. Fitting a logistic function to these data allowed us to quantify learning in terms of both selection accuracy and speed (Fig. 4B). Given a preparation time of 400 ms, single-finger selection improved by 12.10% from day 1 to day 4 of testing (t18 = −3.576, P = 0.002). Correspondingly, the average preparation time required to reach at least 80% finger selection accuracy decreased by 89 ± 27 ms (t18 = 3.241, P = 0.005).
Fig. 4.
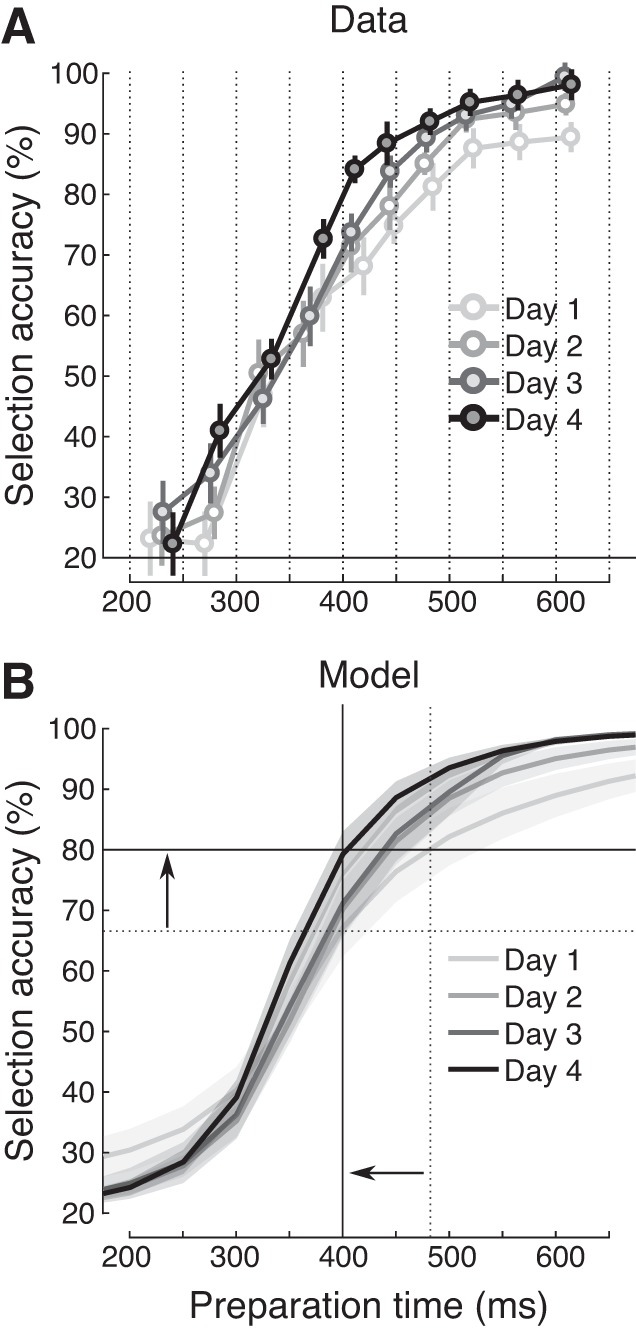
Selection of individual action elements improves with practice. A: mean single-finger selection accuracy plotted as a function of actual average reaction time (RT) separately for each testing day. Vertical dotted lines indicate the instructed preparation time as determined by Forced-RT. The horizontal solid line denotes chance level for selection accuracy (1 out of 5 fingers). Between-subject variability is plotted as error bars. B: logistic function model fits for data shown in A separately for each testing day. Solid lines and arrows serve as a visual aid to appreciate performance improvements in selection accuracy given a 400-ms preparation time (vertical solid line), and improvements in selection speed to reach 80% selection accuracy (horizontal solid line) from day 1 (dotted lines) to day 4. Shaded areas indicate SE.
These results indicate that learning effects in sequence production can be partly explained by improvements in the selection and execution of individual sequence elements. Indeed, an ~90-ms speed improvement per digit could potentially fully account for the observed improvements for untrained sequences. However, it cannot account for the added performance benefit for trained sequences, as the speed-up in single-digit selection would benefit trained and untrained sequences equally.
Participants Preplan the First Three Items in a Sequence
Although sequence preplanning cannot be measured directly at the behavioral level (Haith et al. 2016), having more time to plan a sequence should result in better (i.e., faster, more accurate) sequence execution. Therefore, we used a forced-response paradigm to infer how much of a sequence had been preplanned. Indeed, we found that longer preparation times led to faster sequence execution (Fig. 5A) in any phase of training. This was confirmed by a within-subject ANOVA that included the last two trained and the last two untrained blocks of each day: averaged across day and sequence type (i.e., trained or untrained), the main effect of preparation time on ET was significant (F3,57 = 58.632, P = 5.551e-16). In other words, with more time to prepare sequences are planned better and executed faster.
Fig. 5.
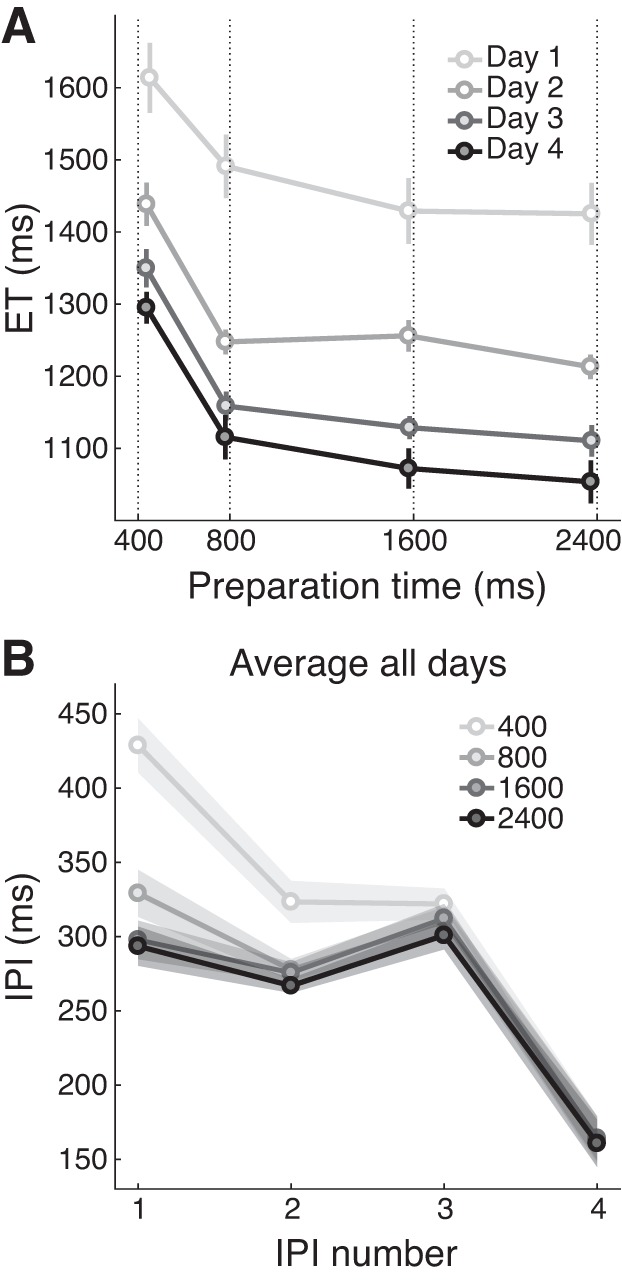
Preparation time affects the quality of sequence preplanning. A: mean execution time (ET) as a function of preparation time. Separate lines indicate results for each training day. Results are averaged across trained and untrained sequences, using the last 4 blocks for each training day. Error bars reflect SE. For each preparation time, the actual average reaction time (RT) is shown, with the instructed RT indicated by the dotted line. B: mean duration for each interpress interval (IPI), averaged across training days, with separate lines for each preparation time level. As in A, results are averaged over the last 4 blocks of each day, collapsing across trained and untrained sequences. Shaded areas indicate SE.
The results of the single-response task indicate that 400 ms is enough to select and plan the first item in the sequence. Therefore, 2,400 ms should be enough time to fully select and plan a five-item sequence. But how many steps ahead do participants actually preplan, i.e., what is their preplanning capacity? To answer this question, we inspected the profile of interpress intervals (IPIs), averaged across training days and trained or untrained sequences (last 4 blocks from each day), separately for each preparation time level (Fig. 5B). We observed that IPI 1 took 100 ± 14 ms longer in the 400-ms than the 800-ms preparation time condition, indicating that participants were making use of the extra preparation time to preplan the transitions between the first and the second finger press (t19 = 6.909, P = 1.377e-06). The difference between 400-ms and 800-ms preparation time conditions was also significant for IPI 2 (mean difference = 46 ± 10 ms; t19 = 4.409, P = 3.016e-04) and IPI 3 (mean difference = 12 ± 5 ms; t19 = 2.458, P = 0.024). In contrast, no effect of preparation time on IPI duration was found for IPI 4 (F3,57 = 0.232, P = 0.874). This suggests that, even for the longest preparation times, participants did not preplan the entire sequence. Longer preparation times only resulted in faster execution of the first three elements in the sequence (an indirect estimate of sequence preplanning) and did not affect the execution speed of the last two elements (i.e., these elements were not preplanned in advance).
Taken together, our results provide evidence that on average participants preplan at least three elements into the future. It follows that even short five-element sequences could not be fully preplanned, regardless of the given amount of preparation time. As the remaining elements still need to be selected and planned, this type of planning has to occur online, i.e., while already executing the beginning of the sequence.
As a side observation, we noted that IPI 4, the transition from second-to-last to last press, was consistently the fastest among all IPIs. There are two possible, not mutually exclusive, explanations for this phenomenon: first, because the last press is not followed by any further presses, participants may have been able to choose a biomechanically faster way of executing the last press, i.e., motor planning only needed to concentrate on an efficient way of releasing the last finger, not to transition to a new press. Alternatively (or additionally), toward the end of the sequence participants had nothing left to plan online (i.e., no further cognitive load), allowing them to fully optimize the execution of the last transition. Future studies will be needed to distinguish between these possibilities. Apart from overall faster performance, however, IPI 4 showed effects of preparation time and training similar to IPI 3.
Sequence-Specific Learning Speeds Up Preplanning but Does Not Increase Preplanning Capacity
Next, we asked how much the ability to preplan improves with training. To investigate the influence of sequence-specific learning on preplanning speed, we compared the effects of varying preparation time on ET for trained and untrained sequences at day 4 (Fig. 6A). Although we observed the general decrease in ET with longer preparation times (F3,57 = 40.317, P = 4.108e-14), trained sequences were always faster than untrained sequences (F1,19 = 107.624, P < 1e-16), even for the longest preparation time (mean difference = 283 ± 38 ms; t19 = 7.349, P = 5.777e-07). This suggests that even if preplanning has reached full capacity, there is a substantial advantage for extensively trained sequences. This advantage might reflect learning to execute coordinated transitions between finger presses or improvements in online planning (see below).
Fig. 6.

Training makes preplanning faster but not more complete. To assess sequence-general learning we compared performance for untrained sequences between day 1 and day 4. To assess sequence-specific learning, we compared trained and untrained sequences on day 4 (the last 4 blocks: 2 trained, 2 untrained). A: mean execution time (ET) as a function of preparation time, separately for untrained sequences on day 1 (orange dotted) and trained (blue) and untrained (orange solid) sequences on day 4. Other figure conventions are the same as in Fig. 5A. B: speed (1/ET), expressed as % of the individual speed reached at 2,400-ms preparation time, separately for untrained sequences on day 1 (orange dotted) and trained (blue) and untrained (orange solid) sequences on day 4. C: mean interpress interval (IPI) duration on day 4 separately for untrained (left) and trained (right) sequences and preparation time levels. Shaded areas indicate SE.
Importantly, however, longer preparation times benefited the execution of untrained sequences more than the trained ones, as confirmed by a significant interaction between preparation time and sequence type (F3,57 = 4.168, P = 0.009). To visualize this effect better, we normalized the speed for each condition (1/ET) by the speed reached given the longest preparation time (2,400 ms; Fig. 6B). This analysis shows that participants could reach preplanning capacity for trained sequences in 1,600 ms, whereas they still benefited from additional time to preplan the untrained sequences. This result indicates that sequence-specific learning makes the preplanning of known action sequences faster.
In contrast, sequence-general learning did not seem to improve the speed of preplanning. We compared the performance curve for untrained sequences between day 1 and day 4 (Fig. 6A). Despite the clear improvement in sequence execution speed from day 1 to day 4 for untrained sequences (F1,19 = 10.405, P = 0.005), we found no significant interaction between preparation time and day (F3,57 = 0.186, P = 0.906). After normalization to the fully prepared execution (2,400-ms preparation time), the speed of preplanning remained stable (Fig. 6B). Together these analyses reveal that improvements in preplanning speed are present for trained but not for untrained sequences.
We then inspected the IPI profiles of trained and untrained sequences on day 4 (Fig. 6C) to ask whether sequence-specific learning would also increase preplanning capacity. This analysis confirmed that on average participants can preplan at least three elements into the future: a 4 × 1 within-subject repeated-measures ANOVA revealed a main effect of preparation time for both trained and untrained sequences on IPI 1 (both F3,57 > 19.751, P < 6.676e-09) and IPI 2 (both F3,57 > 2.861, P < 0.045). However, the lack of an effect of preparation time for both sequence types on IPI 3 (both F3,57 < 1.986, P > 0.126) and IPI 4 (both F3,57 < 1.916, P > 0.137) suggested that, even provided the longest preparation time, preplanning was not complete. This means that despite the improvements in preplanning speed that resulted from extensive training, preplanning capacity did not substantially improve.
At the same time, even for the 2,400-ms preparation time condition, the last IPI (IPI 4) was executed substantially faster for trained compared with untrained sequences (mean difference = 67 ± 11 ms; t19 = 5.944, P = 1.011e-05). From this we concluded that improvements in online planning of the remaining elements played a significant role in the behavioral improvements observed in sequence production.
Retention Test: Learning Effects Are Robust to Experimental Variations
The results of the training experiment suggest that improvements in single-item selection, preplanning, and online planning drive the development of skilled sequence performance. To show that the observed effects are stable across time, and that they are not dependent on how sequence performance was tested, we conducted a retention test ~3 mo after the training experiment.
First, we sought to test whether the sequence-specific advantages could arise from a general motivational effect given by the fact that in the training experiment trained and untrained sequences were executed in blocked fashion. Knowledge of being in a sequence training block might have acted as a reward, increasing participants’ motivation and thus leading to performance improvements (Wong et al. 2015b). Therefore, we tested trained and untrained sequences under Mixed and Blocked conditions (Fig. 7). We replicated the main effects of preparation time (F3,42 = 34.121, P = 2.456e-11) and sequence type (F1,14 = 89.283, P = 1.876e-07) and the significant interaction between preparation time and sequence type on mean ET (F3,42 = 3.379, P = 0.027). The fact that trained sequences were executed faster than untrained sequences in the retention test suggests that participants had some memory of the trained sequences. Notably, for both Blocked (Fig. 7A) and Mixed (Fig. 7C) presentation of trained and untrained sequences, we could confirm that there was a benefit of sequence-specific training even for fully prepared sequences (2,400-ms preparation time: Blocked 131 ± 36 ms, t14 = 3.641, P = 0.003; Mixed 131 ± 29 ms, t14 = 4.551, P = 4.529e-04). Hence the superior performance on trained compared with untrained sequences cannot be explained by a difference in overall motivation between blocks.
Fig. 7.

Performance improvements are stable across time and experiment paradigm (retention test). A: mean execution time (ET) as a function of preparation time levels with the factor sequence type Blocked separately for trained and untrained sequences in the Forced-reaction time (RT) condition and trained (Tr) and untrained (Un) sequences in the Free-RT condition. For visualization purposes, data from the Free-RT condition were subdivided into bins separated by actual RT quartiles (4 data points per subject, from left to right, respectively), but statistical analyses were performed on unsplit data (1 data point per subject). Other figure conventions are the same as in Fig. 5A. B: mean duration for each interpress interval (IPI) in Blocked blocks separately for untrained (left) and trained (right) sequences and preparation time (in ms). For sake of comparison, mean IPI durations for the Free-RT task are also plotted. Shaded areas indicate SE. C: same as A but with factor sequence type Mixed. D: same as B but for Mixed blocks of trials.
Second, the retention test allowed us to test whether the results obtained in the training experiment with a Forced-RT paradigm would replicate when participants were free to start the sequence at will. The analysis of the Free-RT blocks (Fig. 7, A and C) confirmed that trained sequences were executed faster than untrained ones (mean ET difference: Blocked 222 ± 45 ms, t14 = 4.908, P = 2.308e-04; Mixed 177 ± 25 ms, t14 = 7.007, P = 6.183e-06). Moreover, we found a significant RT advantage for trained compared with untrained sequences in Free-RT blocks (mean RT difference across block type: 174 ± 54 ms; t14 = 3.705, P = 0.002), suggesting that trained sequences could be preplanned more quickly (although there might be other factors in play as well to explain this difference). Taken together, these results corroborate the findings of the training experiment and indicate that these results can be replicated outside of the Forced-RT paradigm.
Interestingly, when allowed to take as much time as needed before starting the sequence, participants had an average RT of ~1,300 ms but showed better performance than the 1,600- and 2,400-ms preparation time conditions in the Forced-RT paradigm: ET in the Free-RT condition with RT of ~1,300 ms was marginally faster than in the Forced-RT condition with 1,600-ms preparation time (mean ET difference across sequence type and block type: 85 ± 36 ms; t14 = 2.326, P = 0.036). This effect likely reflects the dual-task nature of the Forced-RT paradigm: participants had to keep track of the audio-visual cues and plan the response at the same time. In line with this view, the main difference between Free-RT and Forced-RT conditions could be seen in IPI 1. Because correct timing was so important for reward in the Forced-RT condition, participants first aimed to get the first press timed correctly and only afterwards worried about producing the sequence. In the Free-RT condition this requirement did not exist, leading to fast execution of the first three (preplanned) presses.
An additional important observation is that IPI 2 was slower in the Free-RT condition for untrained sequences than for trained sequences and also slower than for the Forced-RT condition with 2,400-ms preparation time. This observation likely reflects the fact that participants started the execution of untrained sequences before preplanning was complete, again supporting the argument that preplanning may be faster for trained sequences.
Finally, the retention test allowed us to explore also the degree to which sequence-specific learning depends on an explicit memory of the trained sequences. The development of explicit sequence memory might have facilitated conscious retrieval of trained sequences in the retention test, perhaps contributing to the observed performance advantage in sequence planning and execution. However, it should be noted that participants were always provided with full explicit sequence knowledge during the task, as the sequence cues remained visible on the screen throughout the execution of both trained and untrained sequences, so there was no incentive for the participants to memorize the sequences. This became evident from the results of the tests for explicit sequence knowledge retention. Participants performed poorly in both free sequence recall (mean recall out of 10 sequences: before sequence production 12.67 ± 3.16%, after sequence production 23.33 ± 3.33%; overall 18.00 ± 2.88%) and sequence recognition (mean d′: before sequence production 0.65 ± 0.33, after sequence production 1.05 ± 0.17; overall 0.85 ± 0.23). These results indicate that the memory of trained sequences was predominantly implicit.
Overall, the results of the retention test support the idea that the sequence-specific improvements in planning observed in the training experiment did not depend on the particular choice of design or the presence of dual-task requirements in the Forced-RT paradigm.
Improvements in Online Planning Drive Sequence-Specific Learning
The retention test also allowed us to more closely investigate sequence-specific improvements in online planning. As in the training experiment, we confirmed that participants could still preplan an average of three elements into the future, and we found no effect of preparation time on IPI 4 across sequence type and block type (F3,42 = 2.650, P = 0.061; Fig. 7, B and D). Once again, we took this result as a sign that participants could not preplan the whole sequence at once, which indirectly implies that online planning must have occurred.
To further investigate the contribution of online planning to sequence-specific learning, we reanalyzed the IPIs from the training and retention experiments, grouping the first two (IPIs 1 and 2) and the last two (IPIs 3 and 4) IPIs in the sequence (Fig. 8). As we have shown, the first two IPIs could be largely preplanned (as their speed varied with preparation time), whereas the last two IPIs needed to rely on online planning to a much greater extent. Thus if we found an effect of sequence type on IPIs 1 and 2 at the longest preparation time (i.e., for well-preplanned presses), it would provide evidence that sequence execution processes had improved beyond the advantages of preplanning. Additionally, if we found a larger effect of sequence type on IPIs 3 and 4 (i.e., for less preplanned presses), we would take this as evidence that online planning got better after sequence-specific training.
Fig. 8.

Improved online planning robustly underlies sequence-specific learning. Mean duration of interpress interval (IPI) pairs (IPIs 1 and 2, left; IPIs 3 and 4, right) as a function of preparation time (in ms) separately for trained and untrained sequences in the Forced-reaction time (RT) condition and trained (Tr) and untrained (Un) sequences in the Free-RT condition. Other figure conventions are the same as in Fig. 7A. A: training experiment, day 4, last 4 blocks (2 trained, 2 untrained). B: retention test, Blocked blocks. C: retention test, Mixed blocks.
In the training experiment (day 4, last 4 blocks: 2 trained, 2 untrained) we found that IPIs 1 and 2 of trained sequences were significantly faster than those of the untrained sequences for all preparation times (all pairwise comparisons: t19 > 5.436, P < 3.029e-05; Fig. 8A). However, in the retention test this was only true for the Blocked paradigm (preparation time 2,400 ms, IPIs 1 and 2, t14 = 2.643, P = 0.0192; Fig. 8B, left). In Mixed blocks, we found no significant difference in mean ET between trained and untrained sequences (preparation time 2,400 ms, IPIs 1 and 2, mean difference: 24 ± 25 ms, t14 = 0.945, P = 0.361; Fig. 8C, left). Overall, these mixed results point to a limited role of motor execution processes to sequence learning.
However, for IPIs 3 and 4, we found a robust main effect of sequence type across all preparation times (Fig. 8, right), regardless of experiment (training: F1,19 = 91.214, P = 1.098e-08; retention: F1,14 = 68.340, P = 9.328e-07), block type (Blocked: F1,14 = 49.981, P = 5.597e-06; Mixed: F1,14 = 47.621, P = 7.315e-06), or paradigm (Forced-RT: F1,14 = 68.340, P = 9.328e-07; Free-RT: t14 = 6.317, P = 1.900e-05). Furthermore, in the retention test, a within-subject ANOVA on ET at 2,400 ms (full preparation) revealed a significant interaction between IPI pair (1 and 2 vs. 3 and 4) and sequence type (trained vs. untrained; F1,14 = 6.987, P = 0.019), indicating that at 2,400 ms there was a bigger sequence type effect for IPIs 3 and 4 than for IPIs 1 and 2. Thus when preplanning is complete (IPIs 1 and 2) the ET advantage for trained sequences was small, whereas when online planning played a bigger role (IPIs 3 and 4) trained sequences were executed consistently faster than untrained sequences. Taken together, these results demonstrate that 1) online planning improved as a consequence of sequence training and that 2) improvements in online planning, rather than in motor execution or sequence preplanning, underlie most of the sequence-specific execution advantage observed at the end of training.
DISCUSSION
Sensorimotor sequence learning manifests when individual action elements can be accurately executed in rapid succession (Beukema and Verstynen 2018; Diedrichsen and Kornysheva 2015; Verwey and Wright 2014). We combined the DSP task with a Forced-RT paradigm to uncover which elementary components supported such skilled motor performance and how they change with learning. One element of skill is the selection and initiation of a single response (out of 5 possible alternatives), an ability that improves with practice (Haith et al. 2016; Hardwick et al. 2017). We also show that on average participants preplan the first three sequence elements and can do so in <2 s. The speed of preplanning improves with sequence-specific, but not sequence-general, learning. However, regardless of the amount of time allowed to prepare, the preplanning capacity (i.e., how many actions can be preplanned into the future) appears to be limited. Therefore, for sequences longer than three items, or when there is little time to prepare, the remaining sequence elements have to be planned online during the execution of the beginning of the sequence. We show that this process is faster for trained than untrained sequences. Overall, our results support the view that sequence-specific learning is explained by improvements in planning processes both before (i.e., preplanning) and during (i.e., online planning) sequence execution.
Quicker Single-Item Selection Underlies Sequence-General Learning
Many studies show that behavioral training improves performance in the execution of repeating (i.e., trained) sequences. However, in the DSP task there are also substantial performance improvements for the execution of novel (i.e., untrained) sequences (Fig. 3; Kornysheva and Diedrichsen 2014; Waters-Metenier et al. 2014; Wiestler et al. 2014). One component of this sequence-general learning is the process of action selection: regardless of the specific sequence order, participants become better at mapping visual stimuli to motor responses for each individual finger press. Indeed, consistent with previous findings (Haith et al. 2016; Hardwick et al. 2017), we show that the speed and accuracy of selection (or S-R mapping) of individual items improved with practice. Thus faster selection of individual items can account for sequence-general learning in the context of the serial reaction time and DSP tasks. However, given that it is defined to work on one element at a time, this process cannot account for sequence-specific learning effects.
Preplanning of Multiple Items Leads to Faster Sequence Execution
In our task, all sequence elements are shown to the participant before the start of the execution. Therefore, other than improvements in single-item selection, performance benefits could also arise from an improved ability to preplan multiple sequential movements before execution (Magnuson et al. 2008; O’Shea and Shenoy 2016; Sheahan et al. 2016; Verwey 1994, 2001; Wong et al. 2015a). Indeed, given enough time before sequence initiation, preplanning does not stop at the first element of the motor sequence (Verwey et al. 2010, 2015). Instead, participants tend to look ahead and preplan more than one sequence element at a time. By combining the DSP task with a Forced-RT paradigm, we obtained an indirect measure of sequence planning (Haith et al. 2016): short preparation times resulted in slower execution for the first few IPIs compared with longer preparation times. From these results we infer that more motor planning has occurred during longer preparation times. Given that ETs seemed to reach an asymptote, it is likely that this process was fully completed by 2,400 ms. However, even when provided with the longest preparation time, participants only prepared the first three or four elements of the sequence.
What determines this upper limit of preplanning capacity that we observed? It may be somewhat surprising that participants could not fully preplan a five-item sequence, especially after a multiday training period. One possibility is that preplanning is limited by the capacity of general working memory (Miller 1956). Although chunking and other strategies usually allow participants to remember a five-item sequence, the attentional demands of motor preplanning may limit the working memory capacity to a smaller number (Bays and Husain 2008; Cowan 2010; Luck and Vogel 1997). Thus the result may reflect a general limitation of the motor system to only be able to preplan three or four elementary movements into the future. Another possibility is that this limit in preplanning capacity was in fact dictated by the dual-task requirements of our forced-response paradigm (Ghez et al. 1997). This paradigm required participants to attend to two demands concurrently: to initiate a response in synchrony with the last in a series of tones and to preplan the correct finger presses. Thus it may be that under unconstrained conditions people can actually preplan a few more elements. Our Free-RT condition in the retention test shows that RTs can be faster than long preparation times in the Forced-RT condition while still reaching comparable sequence execution speed (Fig. 7, A and C). However, a closer inspection of the IPI profiles (Fig. 7, B and D) suggests that the difference in execution speed between Free-RT and Forced-RT conditions is mostly driven by the first IPI (i.e., the first 2 presses). In fact, in the retention test we did not find a difference in the last two IPIs (of either trained or untrained sequences) between Free-RT and Forced-RT conditions. This indicates that 1) 2,400 ms is sufficient to reach preplanning capacity and that 2) dual-task requirements of the Forced-RT paradigm did not limit preplanning capacity.
Results obtained from both invasive recordings in nonhuman primates and neuroimaging in humans under unconstrained conditions also seem to support the notion of a limited preplanning capacity (Averbeck et al. 2002; Kornysheva et al. 2018; Tanji and Shima 1994). In accordance with the competitive queuing hypothesis (see for review Rhodes et al. 2004), these studies show that three or four specific segments of sequential reaching movements are already preactivated before movement onset, with the strength of representation for each segment reflecting the serial position of the planned element in the motor sequence.
The main implication of this idea is that if the length of the sequence exceeds the preplanning capacity, later sequence elements need to be selected and planned during the ongoing execution of earlier sequence elements. This is clearly evident from Fig. 6C, showing that the first two IPIs were significantly faster in the 2,400-ms vs. 400-ms preparation time conditions (an index of superior preplanning), whereas the last two IPIs were not. Therefore sequence planning does not end at the onset of execution (Verwey 1996) but continues during execution as online planning.
Sequence Training Improves Preplanning Ability
We then investigated whether preplanning, online planning, and motor execution processes improved with sequence-specific learning. Our first novel result, consistent across training and retention experiments, was that preplanning became faster for trained sequences (Fig. 6B). In other words, participants needed less time to reach a fully prepared state (i.e., to reach planning capacity). As a consequence, longer preparation times were only beneficial for the execution of unfamiliar sequences. The faster preplanning was also evident in faster RTs when movement initiation was not constrained in the retention experiment (i.e., Free-RT paradigm). Interestingly, we found that, despite the overall gain in execution speed, there was no change in preplanning speed for untrained sequences between day 1 and day 4 (Fig. 6B), suggesting that the ability to improve preplanning is sequence specific and depends on sequence familiarity (developed through training). Furthermore, our data indicated that the preplanning capacity of three or four items was relatively fixed and could not be increased with training.
Does Sequence-Specific Learning Affect Motor Execution Skills?
In the training experiment we found that trained sequences were executed faster than untrained sequences even when participants were provided with ample time to prepare the sequences (Fig. 6A). This effect was also observed for the first two IPIs, which participants could fully prepare (Fig. 8A), and for which online planning should play a minor role. These findings could therefore be taken as evidence that sequence-specific learning improves motor execution itself, beyond the benefit of sequence preplanning.
What could explain such an improvement in motor execution? It should be noted that trained and untrained sequences were matched for probability of first-order transitions. That is, learning to execute specific transitions between any two fingers should have benefited the production of trained and untrained sequences equally. A putative sequence-specific learning effect on the execution level therefore must consist of learning-specific transitions between three or more fingers.
Although there was a clear execution advantage for the first two IPIs of trained sequences in the training experiment and the Blocked retest, we did not replicate this finding in the Mixed retest (Fig. 8C, left): the difference between IPIs 1 and 2 of trained and untrained sequences for the longest preparation time (2,400 ms) was not significant. Therefore, our results remain somewhat inconclusive in respect to sequence-specific improvements in motor execution. Although learning to execute specific three-finger transitions may have played a role in speed improvements, the result was more pronounced in Blocked conditions (Fig. 7, A–C). This may suggest a role of increased motivation in blocks with only trained sequences (Wong et al. 2015b). Alternatively, the difference could indicate that sequence-specific execution skills are not as readily recalled under the uncertainty of a Mixed block.
Improved Online Planning Drives Sequence Learning Effects
Even though the sequence-specific advantage of trained over untrained sequences was not always evident on the first two IPIs, we found clear evidence for a strong and robust difference on subsequent IPIs. Indeed, we showed that the speed difference between sequence types was more pronounced for the end, compared with the beginning, of the sequence. The most likely origin of this effect is that IPIs 1 and 2 could be preplanned in advance (and comparably well for either sequence type), whereas IPIs 3 and 4 required online planning, which became faster with training.
The sequence-specific improvement in online planning could have two explanations. First, as it happens for preplanning, selection and planning processes may become more efficient when acting on a trained sequence. Alternatively, execution of well-learned sequences may require less central attentional resources, and instead rely more on the autonomous “motor processor” (Verwey 2001). The “cognitive processor” would therefore have more resources to look ahead and prepare the next responses, i.e., the possible interference between planning and execution processes would thus be reduced. Either way, our results indicate that sequence-specific learning likely occurs through improvements at the very interface between cognitive (selection) and motor (execution) processes (Diedrichsen and Kornysheva 2015).
Conclusions
The combination of experimental approaches used here allowed us to disentangle different components of skill learning in a sequence production task. We showed that performance improvements cannot be fully explained by either faster single-item selection or improved motor execution. Instead, much of the sequence-specific advantage can be attributed to an enhanced ability to select and plan multiple sequence elements into the future, evident both before sequence production starts as well as during sequence execution. Whether these findings generalize to other types of actions (e.g., reaching) remains to be seen. If they do, it would open up the possibility of investigating the neural mechanisms of online planning in animal models. For such experiments, however, it will be critical to ensure that the number of sequence elements is higher than the preplanning capacity, such that online planning and motor execution processes can be dissociated. Overall, online motor planning constitutes a central mechanism at the interface between the cognitive and motor systems that allows the brain to deal with a continuous stream of stimuli and motor demands.
GRANTS
This work was supported by a James S. McDonnell Foundation Scholar award, a Natural Sciences and Engineering Research Council of Canada Discovery Grant (RGPIN-2016-04890), and the Canada First Research Excellence Fund (BrainsCAN).
DISCLOSURES
No conflicts of interest, financial or otherwise, are declared by the authors.
AUTHOR CONTRIBUTIONS
G.A. and J.D. conceived and designed research; G.A. performed experiments; G.A. analyzed data; G.A. and J.D. interpreted results of experiments; G.A. prepared figures; G.A. drafted manuscript; G.A. and J.D. edited and revised manuscript; G.A. and J.D. approved final version of manuscript.
ACKNOWLEDGMENTS
The authors thank Eva Berlot and Spencer Arbuckle for comments on the manuscript.
REFERENCES
- Abrahamse EL, Ruitenberg MFL, de Kleine E, Verwey WB. Control of automated behavior: insights from the discrete sequence production task. Front Hum Neurosci 7: 82, 2013. doi: 10.3389/fnhum.2013.00082. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Averbeck BB, Chafee MV, Crowe DA, Georgopoulos AP. Parallel processing of serial movements in prefrontal cortex. Proc Natl Acad Sci USA 99: 13172–13177, 2002. doi: 10.1073/pnas.162485599. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bays PM, Husain M. Dynamic shifts of limited working memory resources in human vision. Science 321: 851–854, 2008. doi: 10.1126/science.1158023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Beukema P, Verstynen T. Predicting and binding: interacting algorithms supporting the consolidation of sequential motor skills. Curr Opin Behav Sci 20: 98–103, 2018. doi: 10.1016/j.cobeha.2017.11.014. [DOI] [Google Scholar]
- Cowan N. The magical mystery four: how is working memory capacity limited, and why? Curr Dir Psychol Sci 19: 51–57, 2010. doi: 10.1177/0963721409359277. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Diedrichsen J, Kornysheva K. Motor skill learning between selection and execution. Trends Cogn Sci 19: 227–233, 2015. doi: 10.1016/j.tics.2015.02.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Doyon J, Gabitov E, Vahdat S, Lungu O, Boutin A. Current issues related to motor sequence learning in humans. Curr Opin Behav Sci 20: 89–97, 2018. doi: 10.1016/j.cobeha.2017.11.012. [DOI] [Google Scholar]
- Ghez C, Favilla M, Ghilardi MF, Gordon J, Bermejo R, Pullman S. Discrete and continuous planning of hand movements and isometric force trajectories. Exp Brain Res 115: 217–233, 1997. doi: 10.1007/PL00005692. [DOI] [PubMed] [Google Scholar]
- Haith AM, Pakpoor J, Krakauer JW. Independence of movement preparation and movement initiation. J Neurosci 36: 3007–3015, 2016. doi: 10.1523/JNEUROSCI.3245-15.2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hardwick RM, Forrence AD, Krakauer JW, Haith AM. Skill acquisition and habit formation as distinct effects of practice (Preprint). bioRxiv 201095, 2017. doi: 10.1101/201095. [DOI]
- Kornysheva K, Bush D, Meyer S, Sadnicka A, Barnes G, Burgess N. Neural competitive queuing of ordinal structure underlies skilled sequential action(Preprint). bioRxiv 383364, 2018. doi: 10.1101/383364. [DOI] [PMC free article] [PubMed]
- Kornysheva K, Diedrichsen J. Human premotor areas parse sequences into their spatial and temporal features. eLife 3: e03043, 2014. doi: 10.7554/eLife.03043. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luck SJ, Vogel EK. The capacity of visual working memory for features and conjunctions. Nature 390: 279–281, 1997. doi: 10.1038/36846. [DOI] [PubMed] [Google Scholar]
- Magnuson CE, Robin DA, Wright DL. Motor programming when sequencing multiple elements of the same duration. J Mot Behav 40: 532–544, 2008. doi: 10.3200/JMBR.40.6.532-544. [DOI] [PubMed] [Google Scholar]
- Miller GA. The magical number seven plus or minus two: some limits on our capacity for processing information. Psychol Rev 63: 81–97, 1956. doi: 10.1037/h0043158. [DOI] [PubMed] [Google Scholar]
- O’Shea DJ, Shenoy KV. The importance of planning in motor learning. Neuron 92: 669–671, 2016. doi: 10.1016/j.neuron.2016.11.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rhodes BJ, Bullock D, Verwey WB, Averbeck BB, Page MP. Learning and production of movement sequences: behavioral, neurophysiological, and modeling perspectives. Hum Mov Sci 23: 699–746, 2004. doi: 10.1016/j.humov.2004.10.008. [DOI] [PubMed] [Google Scholar]
- Sheahan HR, Franklin DW, Wolpert DM. Motor planning, not execution, separates motor memories. Neuron 92: 773–779, 2016. doi: 10.1016/j.neuron.2016.10.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shmuelof L, Krakauer JW, Mazzoni P. How is a motor skill learned? Change and invariance at the levels of task success and trajectory control. J Neurophysiol 108: 578–594, 2012. doi: 10.1152/jn.00856.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tanji J, Shima K. Role for supplementary motor area cells in planning several movements ahead. Nature 371: 413–416, 1994. doi: 10.1038/371413a0. [DOI] [PubMed] [Google Scholar]
- Verwey WB. Evidence for the development of concurrent processing in a sequential keypressing task. Acta Psychol (Amst) 85: 245–262, 1994. doi: 10.1016/0001-6918(94)90038-8. [DOI] [Google Scholar]
- Verwey WB. Buffer loading and chunking in sequential keypressing. J Exp Psychol Hum Percept Perform 22: 544–562, 1996. doi: 10.1037/0096-1523.22.3.544. [DOI] [Google Scholar]
- Verwey WB. Concatenating familiar movement sequences: the versatile cognitive processor. Acta Psychol (Amst) 106: 69–95, 2001. doi: 10.1016/S0001-6918(00)00027-5. [DOI] [PubMed] [Google Scholar]
- Verwey WB, Abrahamse EL, de Kleine E. Cognitive processing in new and practiced discrete keying sequences. Front Psychol 1: 32, 2010. doi: 10.3389/fpsyg.2010.00032. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Verwey WB, Shea CH, Wright DL. A cognitive framework for explaining serial processing and sequence execution strategies. Psychon Bull Rev 22: 54–77, 2015. doi: 10.3758/s13423-014-0773-4. [DOI] [PubMed] [Google Scholar]
- Verwey WB, Wright DL. Learning a keying sequence you never executed: evidence for independent associative and motor chunk learning. Acta Psychol (Amst) 151: 24–31, 2014. doi: 10.1016/j.actpsy.2014.05.017. [DOI] [PubMed] [Google Scholar]
- Waters-Metenier S, Husain M, Wiestler T, Diedrichsen J. Bihemispheric transcranial direct current stimulation enhances effector-independent representations of motor synergy and sequence learning. J Neurosci 34: 1037–1050, 2014. doi: 10.1523/JNEUROSCI.2282-13.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wiestler T, Diedrichsen J. Skill learning strengthens cortical representations of motor sequences. eLife 2: e00801, 2013. doi: 10.7554/eLife.00801. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wiestler T, Waters-Metenier S, Diedrichsen J. Effector-independent motor sequence representations exist in extrinsic and intrinsic reference frames. J Neurosci 34: 5054–5064, 2014. doi: 10.1523/JNEUROSCI.5363-13.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wong AL, Haith AM, Krakauer JW. Motor planning. Neuroscientist 21: 385–398, 2015a. doi: 10.1177/1073858414541484. [DOI] [PubMed] [Google Scholar]
- Wong AL, Lindquist MA, Haith AM, Krakauer JW. Explicit knowledge enhances motor vigor and performance: motivation versus practice in sequence tasks. J Neurophysiol 114: 219–232, 2015b. doi: 10.1152/jn.00218.2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yokoi A, Arbuckle SA, Diedrichsen J. The role of human primary motor cortex in the production of skilled finger sequences. J Neurosci 38: 1430–1442, 2018. doi: 10.1523/JNEUROSCI.2798-17.2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yokoi A, Bai W, Diedrichsen J. Restricted transfer of learning between unimanual and bimanual finger sequences. J Neurophysiol 117: 1043–1051, 2017. doi: 10.1152/jn.00387.2016. [DOI] [PMC free article] [PubMed] [Google Scholar]