
Figure 1.
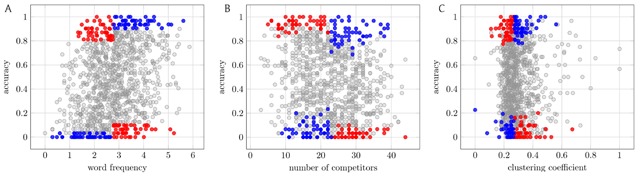
Maximizing the apparent positive and negative effect of an explanatory variable on SWR accuracy. Each panel shows all 1081 words in SWR1081, plotting for each word w an explanatory variable against the response variable accuracy, the fraction of participants who correctly identified this word when it was presented in a noisy environment. The explanatory variables are (A) the log frequency of w in a large corpus of natural text (Brysbaert & New, 2009), (B) the number of competitors of w in the ELP lexicon (Balota et al., 2007), and (C) the clustering coefficient of w in the ELP lexicon. (Every word in SWR1081 has at least three competitors, so clustering coefficient is well defined.) Each panel identifies two pairs of 50-word subsets {A1, B1} (blue; positive effect) and {A2, B2} (red; negative effect). Each pair of color-matched subsets controls for all explanatory variables in previous panels: in (B), Ai and Bi’s average frequency (in z-score) differ by less than δ = 0.05, and likewise in (C) for both average frequency and number of competitors. Among all such δ-balanced 50-element subsets, the displayed subsets show the largest possible difference (positive and negative) in y for low-x and high-x words. (See Supplementary Materials for how these subsets are computed.)