
FIG. 69.
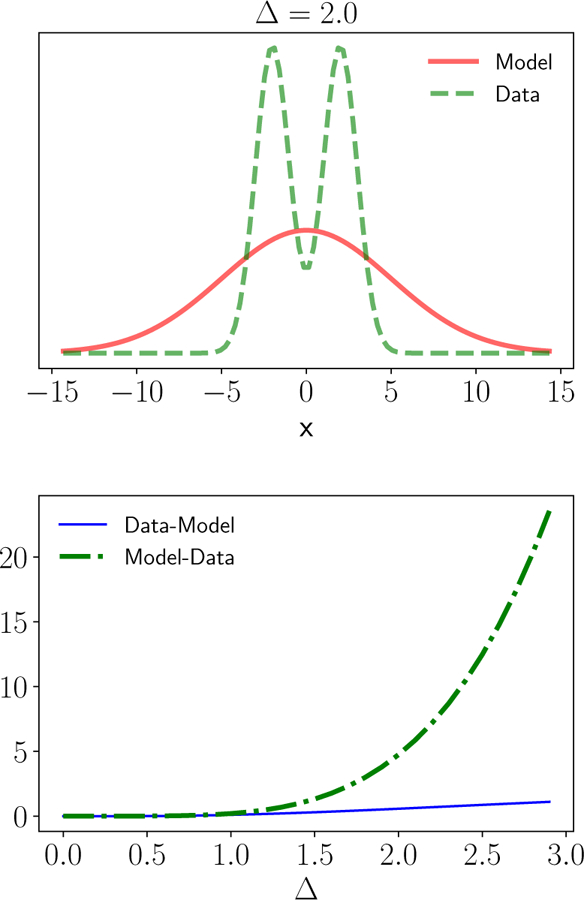
KL-divergences between the data distribution pdata and the model pθ. Data is drawn from a bimodal Gaus-sian distribution with unit variances peaked at ±∆ with ∆ = 2.0 and the model pθ(x) is a Gaussian with mean zero and same variance as pθ(x). (Top) pdata and pθ for ∆ = 2. (Bottom) DKL(pdata||pθ) (Data-Model) and DKL(pθ||pdata) (Model-Data) as a function of ∆. Notice that DKL(pdata||pθ) is insensitive to placing weight in the model distribution in regions where pdata ≈ 0 whereas DKL(pθ||pdata) punishes this harshly.