
Figure 4.
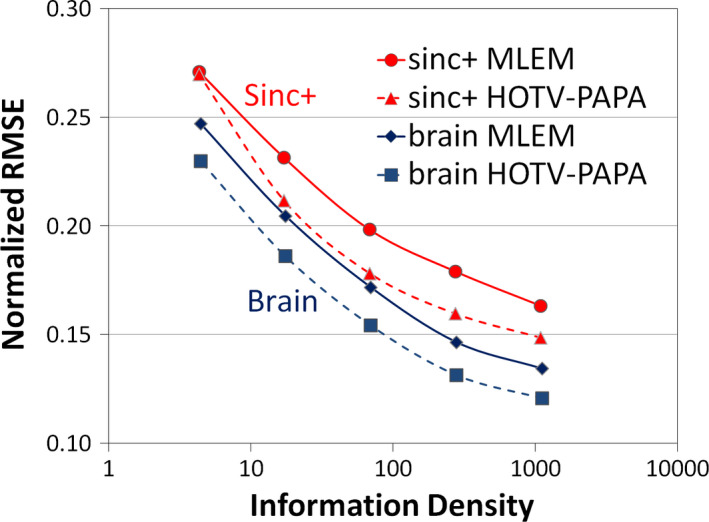
Normalized RMSE as a function of information density is shown for the simulated phantoms. The improvement in RMSE of HOTV‐PAPA compared with optimally Gaussian postfiltered ML‐EM for both the Sinc+ and brain phantoms. The ID is increased by a factor of four for each sequential marker. [Color figure can be viewed at wileyonlinelibrary.com]