
Fig. 4.
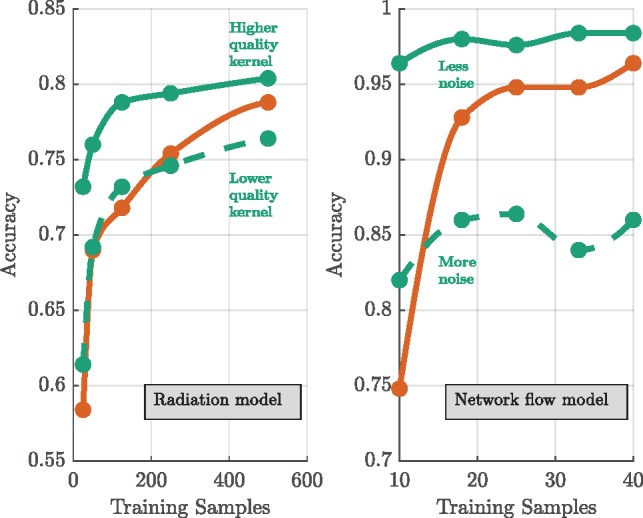
Varying prior knowledge experiments for the radiation model (left) and varying parameter noise experiments for the network flow model (right). Performance metrics of SimKern ML based on simulations with less and more prior knowledge (green) and Standard ML (orange). For each line, the best performing algorithm of SimKern ML or Standard ML is selected (see Section 2.5). Note, the waviness of the less noise case for the network flow model is an artifact of how the data from the box plots was converted into a line plot; the full data, Supplementary Figure S7, reveals a flat relationship