
Figure 4.
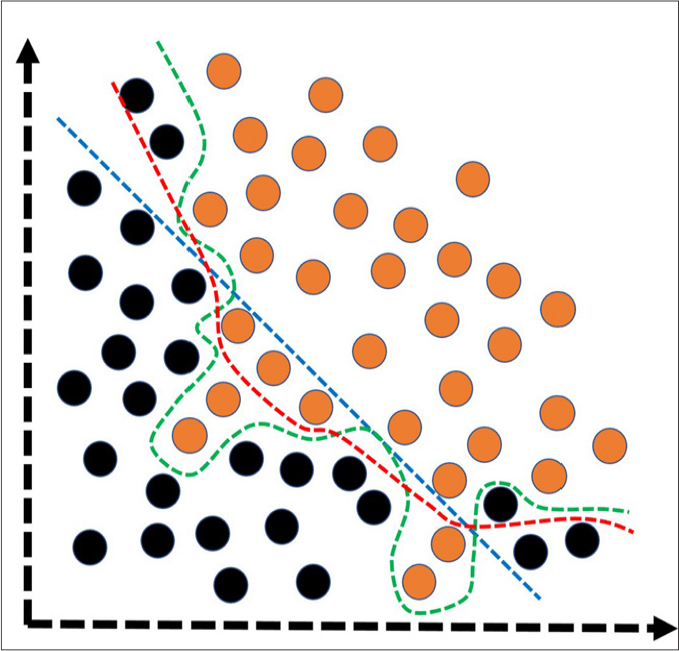
Simplified illustration of the model fitting spectrum. Under-fitting (blue dashed-line) and over-fitting (green dashed-line) are common problems to be solved to create more optimally-fitted (red dashed-line) and generalizable models that are useful on unseen or new data. Under-fitting corresponds to the models having poor performance on both training and test data. In general, the under-fitting problem is not discussed because it is evident in the evaluation of performance metrics. Over-fitting, on the other hand, refers to the models having an excellent performance in training data, but very poor performance on test data. In models with over-fitting, the algorithm learns both the relevant data and the noise that is the primary reason of the over-fitting. In reality, all data sets have noise to some extent. However, in case of small data, the effect of the noise could be much more evident. To reduce the over-fitting, possible steps would be to expand the data size, to use data augmentation techniques, to utilize architectures that generalize well, to use regularization techniques (e.g., L1–L2 regularizations and drop-out), and to reduce to the complexity of the architecture or to use less complex classification algorithms. Black and orange circles represent different classes.