
Figure 2. Dynamic State Changes.
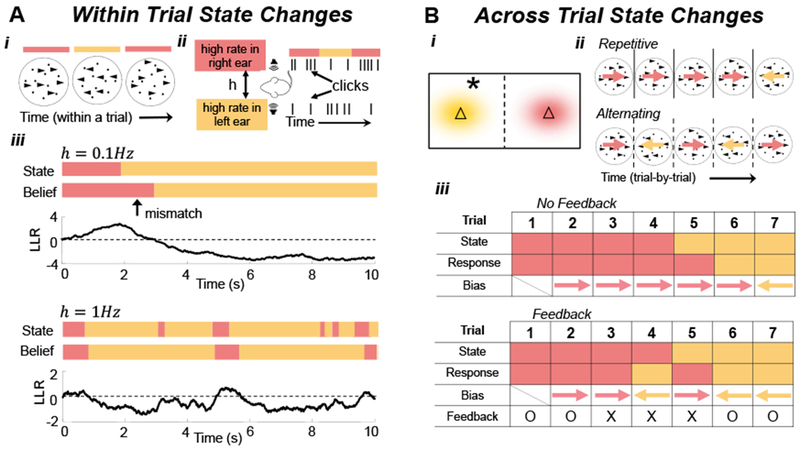
(A) State changes within trials in a (Ai) random dot motion discrimination (RDMD) task, in which drift direction switches throughout the trial5, and (Aii) dynamic auditory clicks task, in which the side of the higher rate stream alternates during the trial6. (Aiii) An ideal observer’s LLR (See Eq. (2) in Box 1) when the hazard rate is low (top panels: h=0.1Hz) and high (bottom panels: h=1Hz). Immediately after state changes, the belief typically does not match the state. (B) State changes across trials. (Bi) In the triangles task5, samples (star) are drawn from one of two Gaussian distributions (yellow and red clouds) whose centers are represented by triangles. The observers must choose the current center (triangle). (Bii) In an RDMD task, dots on each trial move in one of two directions (colored arrows) chosen according to a two-state Markov process. Depending on the switching rate, trial sequences may include excessive repetitions (Top), or alternations (Bottom). (Biii) (Top) Responses can be biased by decisions from previous trials. (Bottom) Probabilistic feedback (‘O’: correct; ‘X’: incorrect) affects initial bias (e.g., trials 3, 4, and 5), even when not completely reliable.