
Figure 7.
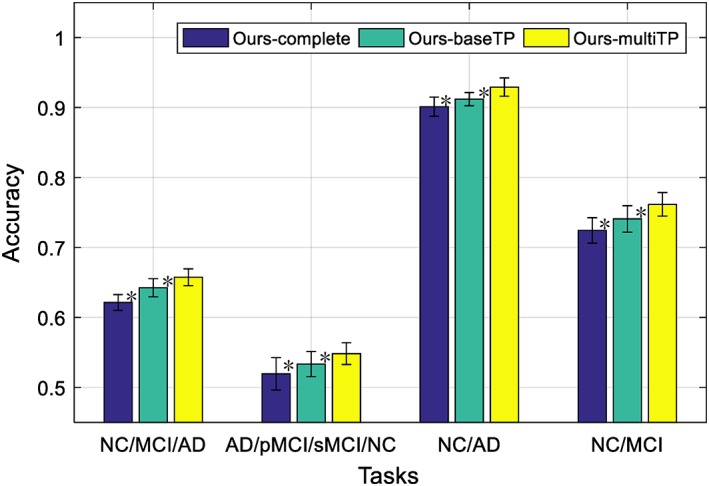
Comparison of classification accuracy for the four classification tasks by using different methods, where “ours‐complete” use baseline time‐point data with complete modalities, “ours‐baseTP” use the baseline time‐point data, while “ours‐multiTP” exploits the longitudinal data by using the data scanned at multiple time‐points (* denotes the Friedman test with p < .001) [Color figure can be viewed at http://wileyonlinelibrary.com]