
Figure 2.
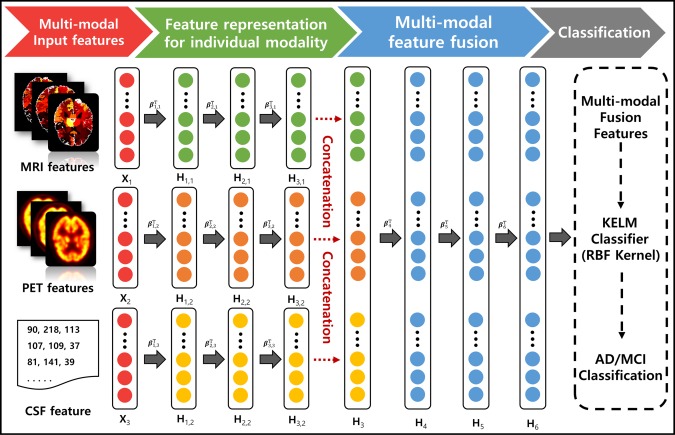
Proposed multi‐modal architecture for fusing MRI, PET, and CSF features. High‐level feature representations extracted from each modality are individually computed using the stacked sparse ELM auto‐encoder (sELM‐AE). Another stacked sELM‐AE is utilized to obtain the joint hierarchical feature representation of MRI, PET, and CSF, taking the high‐level representations of each modality as the input. The obtained joint hierarchical feature representation is classified via the kernel‐based extreme learning machine (KELM) [Color figure can be viewed at http://wileyonlinelibrary.com]