
Figure 2.
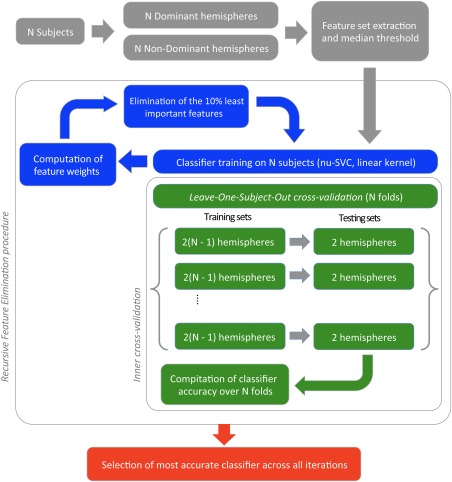
The same Machine Learning Procedure is applied to either the complete training set, or each fold of the leave‐one‐subject‐out (LOSO) cross validation scheme (in our context, each subject provides two hemispheres, therefore two observations). When applied to the full training set (N = 250 Typical participants), the procedure provides a classifier, able to discriminate between Dominant and Non‐Dominant hemispheres. The Machine Learning Procedure entails three steps. First, we select the voxels active in more than 50% of the observations in either the Dominant or Non‐Dominant hemispheres (gray path). Second, we apply a Recursive Feature Elimination procedure (blue path), in which several SVM classifiers are trained in succession, each time on a smaller feature set. For each iteration, we compute the feature weights, rank them, and eliminate the 10% least important features. For each iteration, we also compute a measure of the relative accuracy of the classifier using inner cross‐validation via a LOSO based on 250 folds (green path). For so doing, a classifier is trained on each fold of 249 subjects, and tested on the remaining, unseen subject. Last, we select the classifier exhibiting the best relative accuracy (red path). [Color figure can be viewed at http://wileyonlinelibrary.com]