
Figure 7.
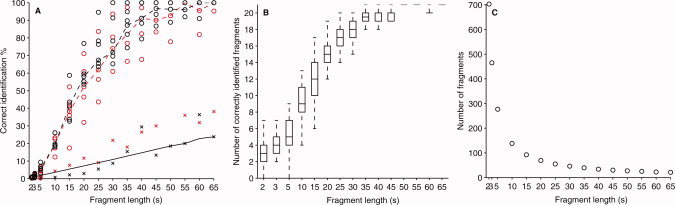
A: The performance of the speech‐fragment identification for each of the seven subjects using the Bayesian mixture of CCA models (red) and with the classical CCA (black). Points with “x”‐signs are outliers that originate from the Subject 7 data. The dashed line marks the median performance, and the solid line represents the minimum level for statistically significant identification (P < 0.05). B: Subject 1 data was reassessed by repeating the identification procedure 50 times with randomly chosen set of 21 separate fragments. The boxplots represents the 25th, 50th, and 75th percentile and the whiskers mark the extent of the correctly identified fragments. C: The testing data of 23 min were divided into consecutive time frames of equal length that determine the maximum number of fragments.