
Fig. 2.
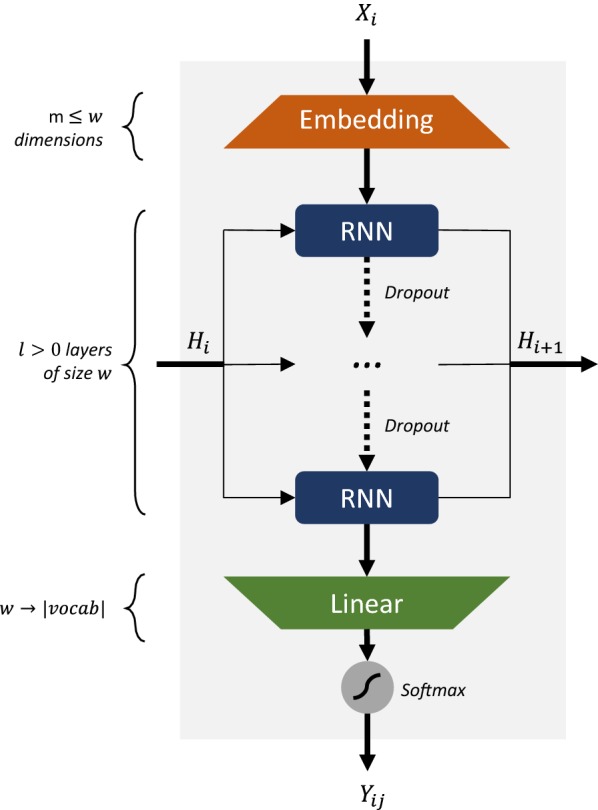
Architecture of the RNN model used in this study. For every step , input one-hot encoded token goes through an embedding layer of size , followed by GRU/LSTM layers of size with dropout in-between and then a linear layer that has dimensionality and the size of the vocabulary. Lastly a softmax is used to obtain the token probability distribution . symbolizes the input hidden state matrix at step