
Figure 2.
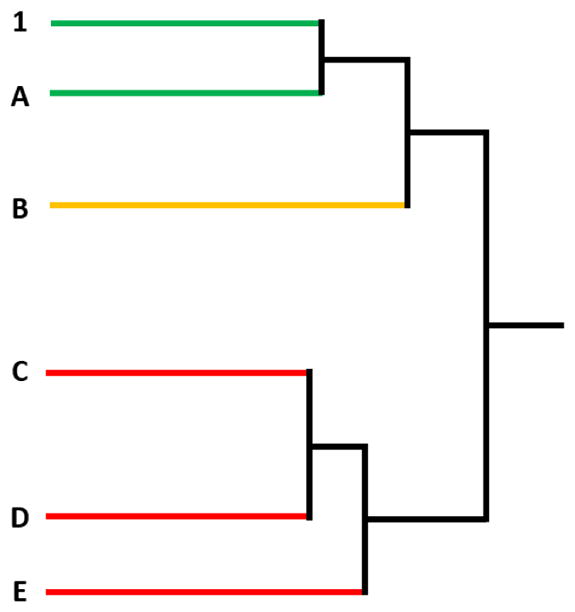
Illustration of hierarchical clustering-based categorization of samples as “similar” to, “maybe similar” to, and “different” from the GBE reference (sample 1). According to rule 1, sample A is considered to be “similar” to sample 1 because they are in the “most similar” cluster. According to rule 2, samples C, D, and E are “different” from sample 1 because they are in the “most different” clusters. According to rule 3, sample B is “maybe similar” to sample 1 because it does not belong to either of the two categories described above.