
Figure 2.
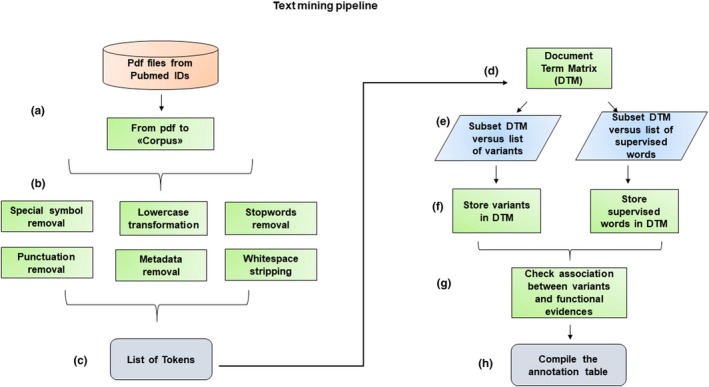
Workflow describing text mining pipeline. The main steps are: (a) transformation of the PDF article text into a “Corpus”; (b) preprocessing of the Corpus; (c) creation of the token list; (d) definition of the Document‐Term Matrix (DTM); (e) subsetting of the DTM versus the list of variant annotated with different token formats and versus the list of supervised words related to functional evidences; (f) creation of the list of mined variants and related annotations; (g) check the association of variants and specific functional evidences; (h) compilation of the annotation tables