
Figure 1. Schematic representing the utility of HYDRA over SVMs for parsing heterogeneity.
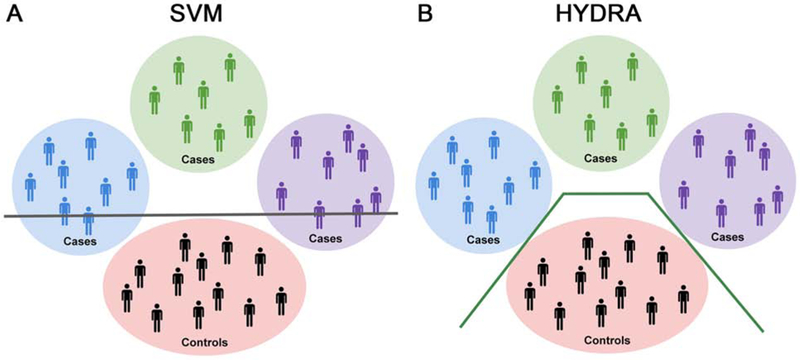
A) Schematic illustrating the use of a linear support vector machine (SVM) to separate cases from controls with a separating hyperplane, shown here as a gray line. Heterogeneity within the cases is represented by the blue, green, and purple circles. As can be seen in this schematic, linear SVMs do not capture the heterogeneity that exists in the cases. B) Conversely, HYDRA is able to classify each cluster of cases separately from the controls. This is accomplished by using multiple classifiers that form linear hyperplanes (green lines) whose segments separate the clusters of cases from the controls. The goal is to estimate k hyperplanes that distinguish the controls and cases with the largest margin, thus allowing HYDRA to identify heterogeneous groups within the cases.