
Figure 4.
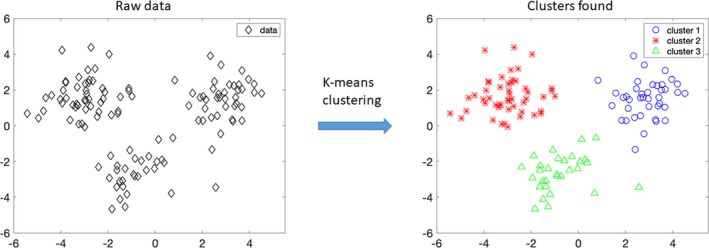
Clustering is a form of unsupervised learning. Clustering is a task of grouping unannotated data into distinct groups, such that samples of the same group are more similar to each other than those from the other groups. In this figure, unannotated data (data) on the left‐hand side are provided as input to the k‐means algorithm with k=3, and the algorithm groups the raw data into 3 distinct clusters, namely cluster 1, cluster 2, and cluster 3, as shown on the right‐hand side.