
Figure 2.
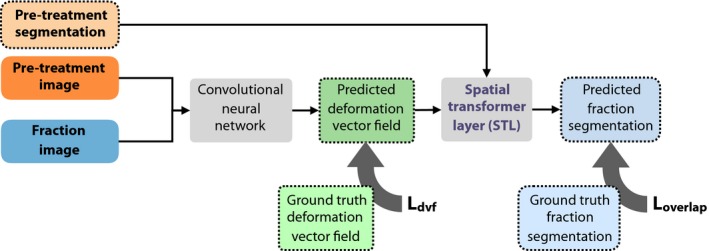
General overview of the method. The method consists of two parts. In the first part, a convolutional neural network predicts a deformation field from a pretreatment image and fraction image. In the second part, the predicted deformation field is used by a spatial transformer layer to deform the segmentation as delineated on the pretreatment image. The loss functions and are only computed during training. [Color figure can be viewed at http://wileyonlinelibrary.com]