
Figure 1.
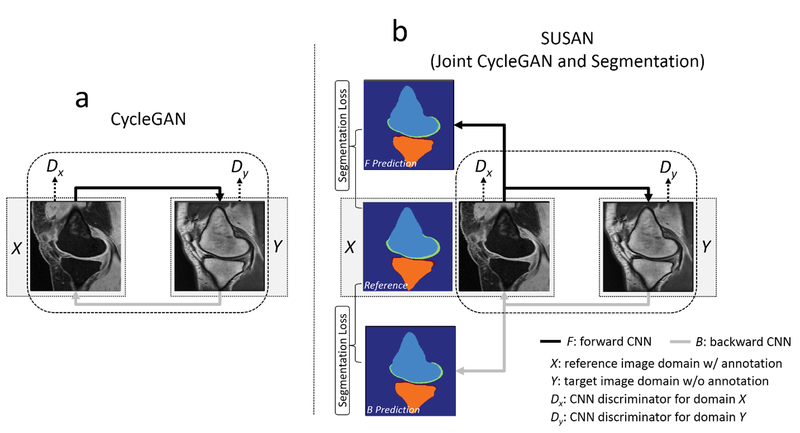
a) The CycleGAN model contains two CNNs, F and B, for forward and backward mapping between image domain X (with annotation) and Y (without annotation), and associated adversarial discriminators DX and DY. DY encourage F to translate images from domain X into outputs indistinguishable from domain Y, and vice versa for DX and B. The cycle consistency loss is used to enforce the idea that if an image is translated from one domain to the other and back again, the image should look identical to its original version. b) SUSAN: the proposed joint CycleGAN and segmentation model incorporates an additional segmentation branch from the mapping CNNs. Joint training is performed for image translation between X and Y, and image segmentation for all image x from domain X and synthetic F (x) which have origins from domain X using segmentation loss.