
Figure 2.
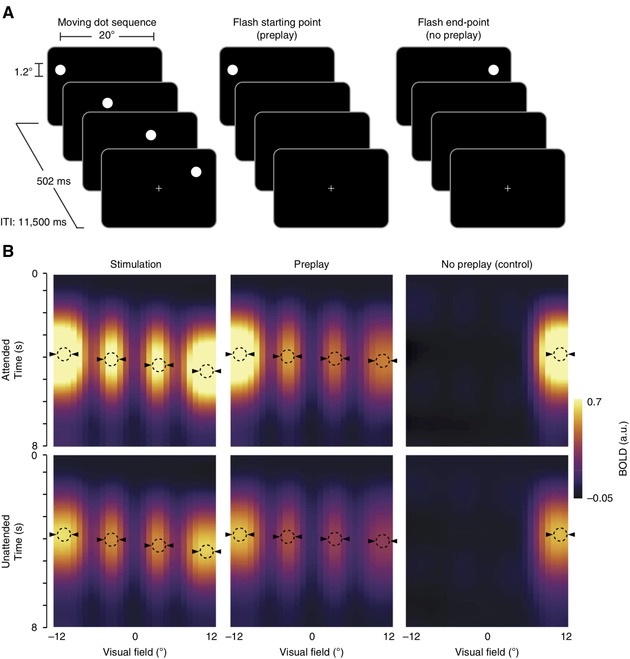
Task schematic and data from Ekman et al. (adapted from Ref. 51). (A) Human participants were repeatedly presented with a moving dot sequence for 4 minutes. Following this dot sequence, participants were then shown either the starting point of the sequence or the endpoint, which was briefly flashed on the screen. (B) The starting‐point stimulus generated a sequence of BOLD activity across the retinotopic locations of V1 corresponding to the positions of the actual dot stimulus, which reconstructed the stimulus sequence in a time‐compressed format (i.e., this activity unfolded more rapidly than the response to the actual stimuli). This “preplay” of the stimulus sequence was not elicited by the endpoint stimulus and was still observed in the absence of attention. The authors argued that the time‐compressed format indicated that this represented automatic predictive activity and not surprise at the omitted stimuli. Enhanced activity in hMT indicated that this activity is fed back from higher‐level regions.