

Abstract
Motivation. Anomaly EEG detection is a long-standing problem in analysis of EEG signals. The basic premise of this problem is consideration of the similarity between two nonstationary EEG recordings. A well-established scheme is based on sequence matching, typically including three steps: feature extraction, similarity measure, and decision-making. Current approaches mainly focus on EEG feature extraction and decision-making, and few of them involve the similarity measure/quantification. Generally, to design an appropriate similarity metric, that is compatible with the considered problem/data, is also an important issue in the design of such detection systems. It is however impossible to directly apply those existing metrics to anomaly EEG detection without any consideration of domain specificity. Methodology. The main objective of this work is to investigate the impacts of different similarity metrics on anomaly EEG detection. A few metrics that are potentially available for the EEG analysis have been collected from other areas by a careful review of related works. The so-called power spectrum is extracted as features of EEG signals, and a null hypothesis testing is employed to make the final decision. Two indicators have been used to evaluate the detection performance. One is to reflect the level of measured similarity between two compared EEG signals, and the other is to quantify the detection accuracy. Results. Experiments were conducted on two data sets, respectively. The results demonstrate the positive impacts of different similarity metrics on anomaly EEG detection. The Hellinger distance (HD) and Bhattacharyya distance (BD) metrics show excellent performances: an accuracy of 0.9167 for our data set and an accuracy of 0.9667 for the Bern-Barcelona EEG data set. Both of HD and BD metrics are constructed based on the Bhattacharyya coefficient, implying the priority of the Bhattacharyya coefficient when dealing with the highly noisy EEG signals. In future work, we will exploit an integrated metric that combines HD and BD for the similarity measure of EEG signals.
1. Introduction
In recent years, we have witnessed significant improvements of using electroencephalogram (EEG) measurement for data acquisition in a wide range of clinical applications. It has also led to the development of data mining methods that discover potential patterns in the data, aiming at characterization of dynamic EEG behaviours. Representative examples include early detection of epileptic seizure [1–3], sleep process monitoring [4–7], and many other neurological disordering related health assessment and surgery problems [8–10].
Time series is an important class of EEG data. One of its mining tasks is to detect potential anomaly event(s)/pattern(s) at an early stage in a long-term EEG monitoring process, which is highly required by change detection [11–13], seizure prediction [14, 15], etc. Hence, the notion of “anomaly EEG detection” is defined in the following sections.
The basic premise of anomaly EEG detection is consideration of the similarity between two nonstationary EEG recordings. A well-established scheme is based on sequence matching. Figure 1 illustrates the computation process of this scheme. The continuously monitored EEG signal is first divided into nonoverlapping (or overlapping) segments; then, the ongoing segment under inspection is compared with those ones that are usual under normal states. It is worth noting that these normal EEG segments can be collected with a prior collection phase or directly taken from the past within the signal itself. The resulting comparison results, i.e., the similarity scores, allow for a change detection by testing a null hypothesis, H0 : θ=θ0 against HA : θ ≠ θ0 on the parameters θ of an assumed distribution. The Gaussian distribution is the most typical assumption, and some other quantifiers, e.g., a direct threshold, can be also applicable to achieve this end. To summarize, three techniques are crucial to the success of anomaly detection, described as follows:
Feature Extraction. To extract explanatory parameters from the raw EEG data in order to reduce data redundancy
Similarity Measure. To employ a specific metric to measure/quantify the similarity between two data recordings, i.e., individual EEG segments
Decision-Making. To make a decision by testing a null hypothesis based on the resulting similarity scores
Figure 1.
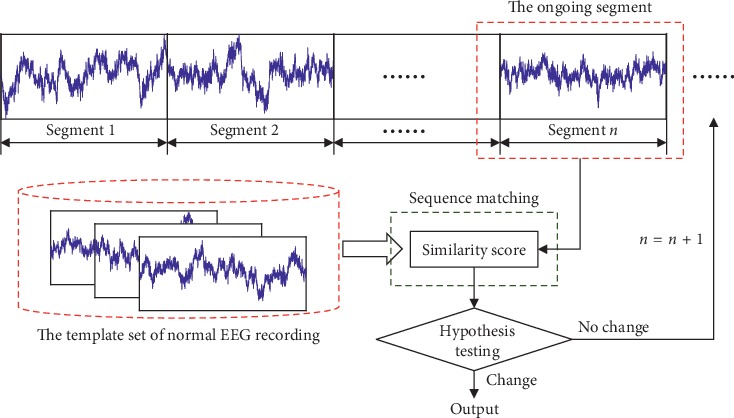
The basic premise of anomaly EEG detection.
Along this line of research, many efforts have been made to enhance the feature extraction as seen in [16–18], and some of them also involve the decision-making [4, 19, 20]. Nonetheless, we should be aware that it is also an important aspect to design an appropriate similarity metric, that is compatible with the considered data, when designing such an anomaly detection system [21]. Here, one can note that although the design of similarity metric has been an important problem in the context of statistics and data mining [22–24], the metric used for EEG signal processing still needs to be clarified due to the domain specificity. However, to the best of our knowledge, few of existing studies associated with the EEG signal processing takes into account this issue in the design of anomaly EEG detection systems.
The main objective of this work is to investigate the impacts of different similarity metrics on anomaly EEG detection based on a sequential matching scheme, which uses similarity measure coupled with a null hypothesis testing. Thus, we collect a variety of most popular and state-of-the-art metrics from other areas that would be potentially available for our problem and modify/extend them if necessary to incorporate with the anomaly EEG detection. Impacts of different metrics on anomaly detection results are evaluated based on two data sets. The experimental results reveal the different impacts of investigated metrics. Especially, the HD and BD are demonstrated outperforming performances than other competitors including PCCD, SKLD, KD, BD, and the typically used ED. This study therefore provides a preliminary basis for the EEG signal processing.
The organization of the rest of this paper is given as follows. Section 2 formulates the considered problem. Section 3 introduces several typical metrics that are potentially available for EEG signal analysis. Section 4 describes the testing data and the experimental implementation. Section 5 shows the results with some discussion. Section 6 finally concludes this paper and shows the future work.
2. Problem Formulation
In this section, we first assume that the collected EEG recordings have been already represented by employed features (the feature extraction will be given in the following Section 4.2.1). We then review the method of anomaly EEG detection in the following [25].
The anomaly detection is concerned with recognising new inputs that differ in some way from those that are usual under normal states [26]. Based on this, for a given query EEG recording x, it is a common practice to compare it with a set of normal templates {yj}, j=1,…, M, where yj is a EEG recording template and M is the total number. This size of the templates is a trade-off between sensitiveness to EEG status change and robustness to noise. If the size of the template is larger, it will be more robust to noise but less sensitive to change because the change often occurs instantaneously, and vice versa. In this paper, the size of the templates was set as 20 seconds empirically according to our clinical experience. The (anti-)similarity can be then quantified as the maximum similarity between the query recording and the templates using a similarity metric s. We denote it as , where the and are the features extracted from x and yj. The x is inspected as an anomaly event if the resulting similarity score S(x) exceeds a predefined threshold λ, i.e., S(x) < λ; otherwise, it is inspected as normal. Here, it is worth to mention that the detection can achieve a scalable and flexible detection result with using a different value of λ. However, since the focus of this paper is on the investigation of similarity metric, we do not make additional discussion on this issue. The interested reader can refer to [27, 28] for more discussions on this issue.
The similarity metric s is essential to report an accurate and reliable detection result, and its construction normally relies on a specific distance metric. A greater value of distance indicates a smaller level of similarity. More importantly, for the two given EEG recordings and , the employed distance metric needs to satisfy several fundamental properties:
Nonnegativity, i.e.,
Identity, i.e., if and only if
Symmetry, i.e.,
Triangle inequality, i.e., , where is a third EEG recording that is not equivalent to both and
Here, one can note that, the distance metric for similarity quantification is not necessary to meet all of these properties especially the triangle inequality, under which such kinds of distance are called as non-metric distances [29].
Based on the above definition, the similarity metric can also be confirmed as S ∈ [0,1] with value of 1 if two compared EEG recordings are identical and 0 if nonidentical at all. In the following, we identify some typical metrics with potentials to solving our problem by careful reviewing of the relevant literature. In particular, during the identification, two following issues were considered:
The metric should satisfy three properties of scalability, sensitivity, and coverage, according to [30]
Among various metrics, we only pay attention to the ones which only calculate the similarity between two sequences with equal lengths
3. Common Metrics
This section introduces a variety of metrics from other areas that would be potentially available for our problem and modify/extend them if necessary to incorporate with the considered anomaly EEG detection problem.
Let us assume that we have two sequences, P={p(k)}, k=1,2,…, K, and Q={q(k)}, k=1,2,…, K, where p(k) and q(k) are the observed values of P and Q at time k, respectively. A variety of typical metrics, that are potentially available for EEG analysing, are introduced to measure the similarity between P and Q.
3.1. Euclidean Distance (ED)
ED is the most common metric that refers to the real distance between two points in space [31]. The ED between P and Q can be calculated by
| (1) |
Taking into account the characteristics of similarity metric described in Section 2, we use the reciprocal of d(ED) to represent the similarity as
| (2) |
3.2. Pearson Correlation Coefficient Distance (PCCD)
PCCD, proposed by Pearson, is a statistic used to reflect the degree of linear correlation between two series, with values between −1 and 1. A larger value of this metric implies a stronger correlation of the two compared series [32]. The PCCD between P and Q can be calculated by
| (3) |
So, the similarity defined by PCCD is then calculated by
| (4) |
3.3. Symmetric Kullback–Leibler Divergence (SKLD)
SKLD can be used to measure the difference between two probability distributions, widely used in information retrieval and data science [33, 34]. The SKLD between P and Q can be calculated by
| (5) |
but it is not a distance metric because of its asymmetry. In order to solve the problem, symmetric Kullback–Leibler divergence is very popular in various statistical distance metrics [35] and is calculated by
| (6) |
Then, the similarity can be gotten as
| (7) |
3.4. Hellinger Distance (HD)
HD was first proposed by Hellinger in [36]. It is used in probability and statistics to measure the similarity between two probability distributions, which belongs to f-divergence [36]. The HD between P and Q can be calculated by
| (8) |
Thus, the similarity based on HD can be calculated as
| (9) |
3.5. Kolmogorov Distance (KD)
KD was introduced by Kolmogorov [37]. This statistical distance plays an important role in probability theory and hypothesis testing [38], and it is widely used to measure the difference between two probability distributions [39]. Therefore, the KD between P and Q can be calculated by
| (10) |
Thus, the similarity based on KD can be calculated as
| (11) |
3.6. Bhattacharyya Distance (BD)
In the statistics, BD which was proposed by Bhattacharyya in [40], also known as the Hellinger distance, measures the similarity of two discrete or continuous probability distributions. It is closely related to the Bhattacharyya coefficient, which measures the overlap between two statistical samples or populations [23]. The Bhattacharyya coefficient can be used to determine the separability of the class classification used in the measurement of two samples that are considered relatively close. The BD between P and Q is defined as
| (12) |
where BC(X, Y) is the Bhattacharyya coefficient.
| (13) |
In the above schemes of distance metric, the similarity by some of them does not satisfy the condition s ∈ [0,1], as summarized in Table 1. To cope with this problem, the similarity needs to be normalized for some of them, and the normalization will be given in Section 4.2.
Table 1.
The range of the distance metrics.
| ED | PCCD | SKLD | HD | KD | BD | |
|---|---|---|---|---|---|---|
| Range of distance value | [0, +∞] | [−1,1] | [0, +∞] | [0, +∞] | [0, +∞] | — |
| Range of similarity score | [0, +∞] | [0,1] | [0, +∞] | [0, +∞] | [0, +∞] | [0,1] |
4. Materials and Methods
This section introduces the testing data and the implementation of our experiments.
4.1. Testing Data
The testing data in this section are from two data sets:
The first data set is established based on our system setup. The process of data collection is depicted in Figure 2. Electrodes are placed in accordance with the International 10–20 Electrode Placement Method to collect EEG signals. The original multichannel EEG signals are obtained using the data collector. The sampling rate of data collection used here is 512 Hz. The channel C4 was chosen for our testing. Three neurological experts are invited to check the original data and label the ground-truth according to their domain experiences, i.e., which part is normal and which part is abnormal. Here, it must be pointed out that the normal status represents that the EEG signal is in a stable status, and the abnormal status includes an unstable status of the EEG signal that might be caused by seizures or other abnormal physical activities. The data are divided into several samples using a 10,000 points nonoverlapping window. Examples of tested data samples are shown in Figure 3(a).
The second data set is taken from the public Bern-Barcelona EEG data set. They randomly select 3,750 pairs of simultaneously recorded signals from the pool of all signals measured at focal and nonfocal EEG channels, respectively, and divide the recordings into time windows of 20 seconds. The original data are recorded with a sampling rate of 1,024 Hz. Then, these EEG signals were downsampled to 512 Hz prior to further analysis so that each piece of EEG data contains 10,240 samples in length [41]. Examples of data in this data set are shown in Figure 3(b).
Figure 2.
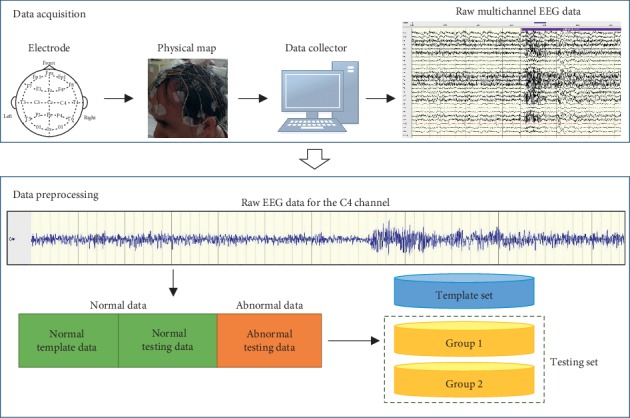
Collection of testing data based on our setup.
Figure 3.
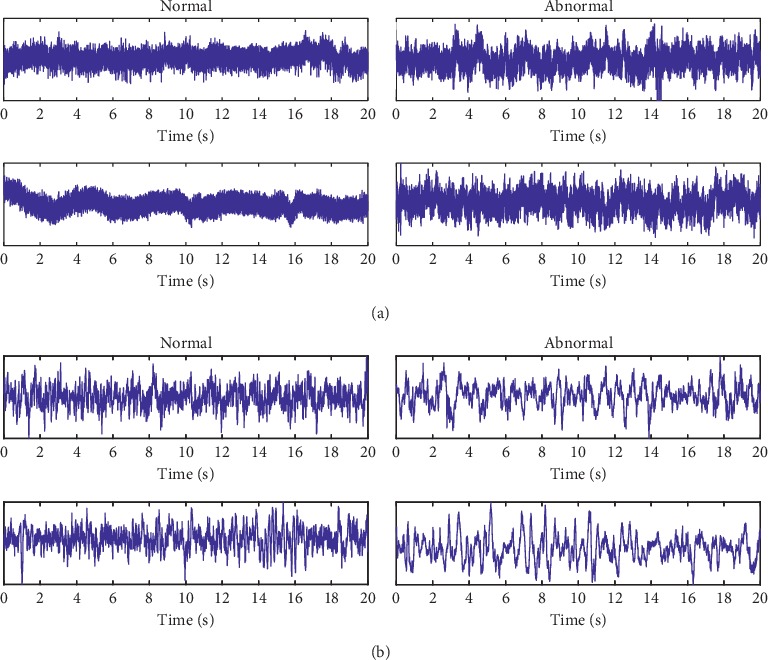
Examples of testing data: (a) collected data with our setup, and (b) data taken from Bern-Barcelona EEG database. From left to right: examples of normal data and examples of abnormal data.
Additionally, for each data set, we first select 30 pieces of most table normal data segments to form a template set, and the stability and normality here are judged according to domain experts, and the residuals are as the test data. Moreover, the test data are further equally divided into two groups: one for optimizing threshold and one for final testing. Both groups contain 30 pieces of data segments, of which 15 pieces are normal data segments, and the other pieces are abnormal. The detection performance was evaluated with cross-validation of these two groups. We repeat the whole process of the evaluation twenty times, such that the final results can be obtained and analysed.
4.2. Experimental Implementation
Consistent with the mechanism of anomaly EEG detection introduced previously in this paper, we perform three steps, i.e., feature extraction, similarity measure, and decision-making, to carry out our experiment. Let us first denote each ith piece of template data as yi(n), n=1,2,…, N, and denote each ith piece of testing data as xi(n), n=1,2,…, N. Main methodologies used in the experiments are then introduced in the following.
4.2.1. Feature Extraction
We extract the so-called power spectrum [21] from the raw EEG data as the feature. Let us assume that the observed value of a piece of the EEG signal at the nth point has been denoted as x(n), n=1,2,…, N. The EEG signal was observed in discrete situation, where the transform is discrete in both time and frequency domains [42]. We may review the discrete Fourier transform (DFT) calculation, which is formulated as
| (14) |
where X(k) is the output of the transform and k indicates the frequency index.
Recall that the main frequency components of EEG are δ-wave (<4 Hz), θ-wave (4–8 Hz), α-wave (8–14 Hz), β-wave (14–30 Hz), and γ-wave (>30 Hz) [43]. That is, if a neurological disorder happens, the amplitudes of these frequencies change accordingly. Thus, they are called characteristic frequencies; i.e., different disorders have different characteristic frequencies. Actually, many successful attempts have been reported using these frequencies to diagnose the neurological disorders [44, 45]. We hence use a subband of [0.1, 70] Hz covering these frequencies empirically for EEG inspection.
After a subband passing filtering (the resulting EEG data are denoted as x'(n) after filtering), the power spectrum can be estimated using the Welch method, a typical power spectrum estimation method, by
| (15) |
where U=(1/M)∑n=0M−1d22(n) and d2(n) is the window function. The resulting power spectrum allows for the quantitative inspection of EEG data. An example is shown in Figure 4. It can be found that the anomaly EEG signals have the disordering amplitude variations and are polluted with a high ratio of noise. As a result, it would be very difficult to judge whether the EEG signal is abnormal through time-domain analysis. In contrast, the difference between normal and abnormal EEG signals in the frequency domain is more clear, thus allowing for quantitative inspection, i.e., similarity measure, for EEG data inspection.
Figure 4.
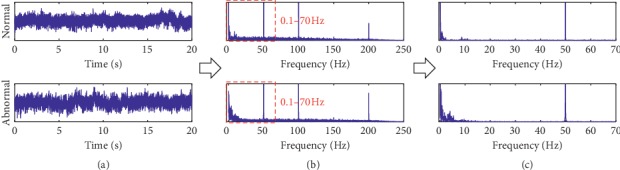
An example of feature extraction: (a) original signal; (b) DFT signal; (c) power spectrum.
Based on the above calculation of power spectrum, the testing data xi(n) and the compared template yj(n) can be represented as their corresponding power spectrums and , respectively.
4.2.2. Similarity Measure
is the similarity between and , which is calculated through the metrics described in Section 3. The similarity S(xi) of xi to a normal status is thought of as the minimum s among all templates, i.e., .
Furthermore, in order to satisfy the requirement described in Section 2, {S(xi)} should be normalized as [0,1] by
| (16) |
We still use {S(xi)} to represent the similarity for simplicity in the following.
4.2.3. Decision-Making
In order to inspect whether xi(n) is normal or not, a threshold λ should be predefined. The decision is subsequently made by testing the following hypothesis:
| (17) |
If the similarity between of testing data xi(n) is greater than the threshold λ, the data are inspected as a normal data; otherwise, it is considered as abnormal. We first carry out a prior estimation to confirm the optimal value of λ with a number of EEG testing data and then use it to detect all other testing EEG signals in the experiment. The results shown in the following section are obtained by the optimal value of λ.
5. Results and Discussion
5.1. Experiment I: Investigation on Data Set I
As described in Section 4.1, the evaluation was repeated 20 times to obtain the final result. In the following, detailed results for one of evaluations are provided.
Figure 5 provides the detection results for all investigated metrics using the data of our database. In the left of each subfigure, we show the computed similarities of each training data including normal training data and abnormal training data. The similarities are gathered and then arranged in ascending order (normal testing data) or descending order (abnormal testing data). As such, two curves corresponding to normal testing data and abnormal testing data can be obtained, and they intersect at point O. The abscissa of point O (AOPO) can provide an overall evaluation for normal and abnormal testing data. A smaller AOPO means a greater difference between the normal recordings and the abnormal recordings, indicating that the similarity indicator is better; otherwise, the similarities between the two classes of recordings are not much low, meaning that the similarity indicator is not good enough. From these results, it can be clearly seen that HD and BD achieve the best result and the KD and SKLD have achieved not-so-good results, while the ED and PCCD have the worst results.
Figure 5.
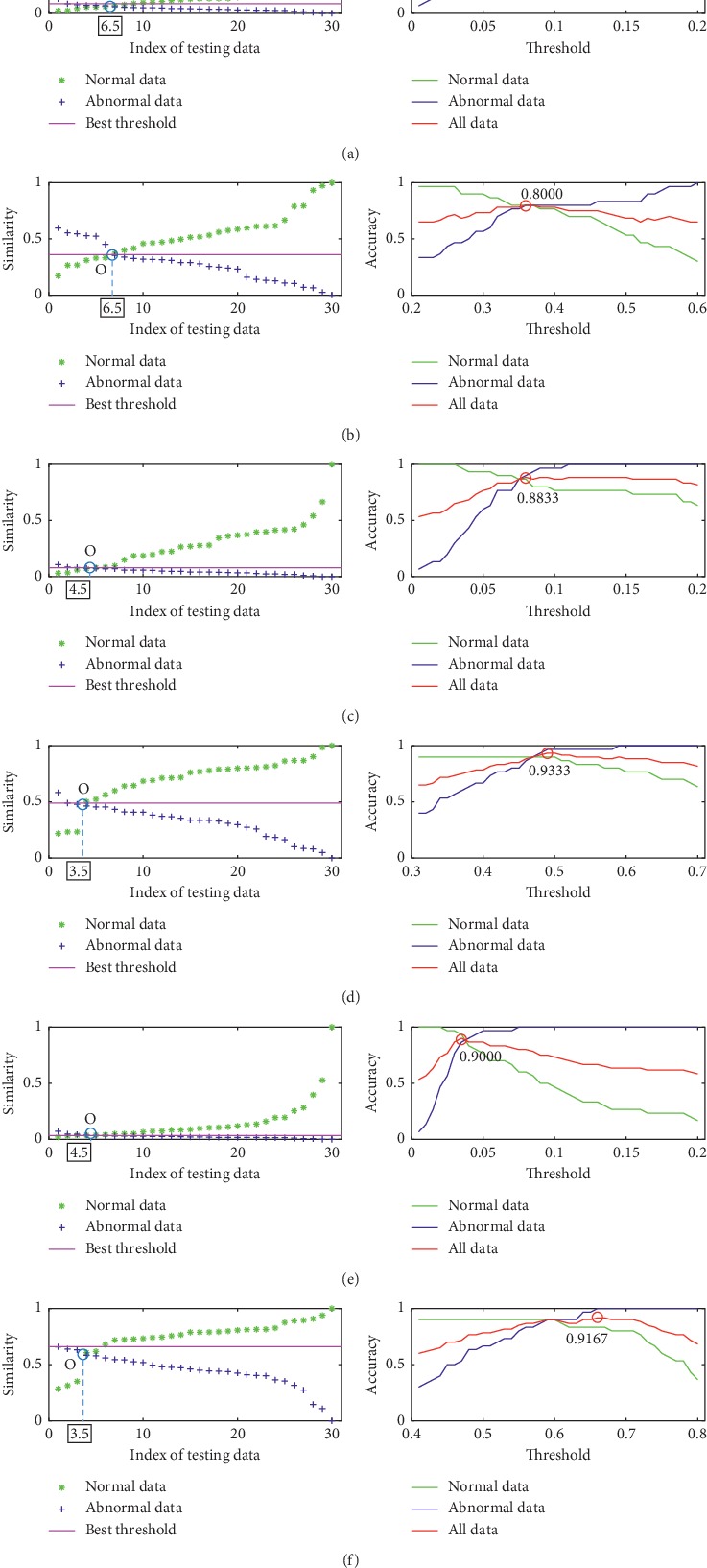
Results of six metrics using the training data of our database. From left to right: the similarity between each piece of data in the training data set and the template set and the accuracy of the metric for the normal training data, abnormal training data, and all training data. Detection result by using (a) ED, (b) PCCD, (c) SKLD, (d) HD, (e) KD, and (f) BD.
The other indicator of accuracy is also used to quantify the detection performance, which is defined as
| (18) |
where TP is true positive indicating the number of data that are inspected correctly and FN is false negative indicating the number of data that are inspected incorrectly. The right of each subfigure in Figure 5 shows the results of all metrics in term of accuracy. The hypothesis testing described in Section 4.2.3 is used to classify the group 1 of testing data using all investigated metrics with different threshold λ values. Therefore, the higher the accuracy, the better the metric. And it can be seen that, for each metric, as λ increases, accuracy increases first and then decreases. The values of λ corresponding to the highest accuracy are used to calculate the accuracy of the group 2 data set. Two examples are given in Figures 6 and 7, in which we show the similarity scores of all investigated metrics (using their optimal λ) for a normal testing recording and an abnormal testing recording. It can be found that PCCD and KD output wrong results for the abnormal testing data, while the others output the right results. It can be seen that the HD achieves the best performance outperforming other metrics.
Figure 6.
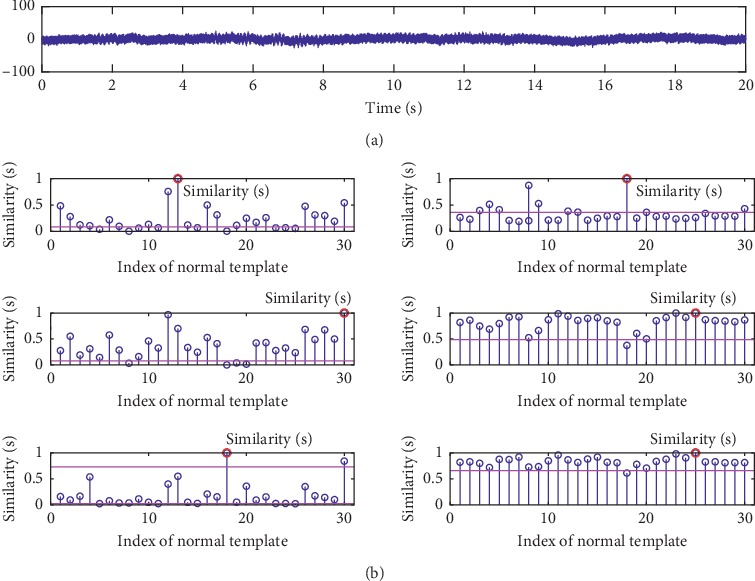
An example of similarity scores for a normal testing data in our database metrics. The similarities S between the testing data and the template set are labelled by red circles. From top to bottom: (a) the original data; (b) the similarities obtained by ED, PCCD, SKLD, HD, KD, and BD.
Figure 7.
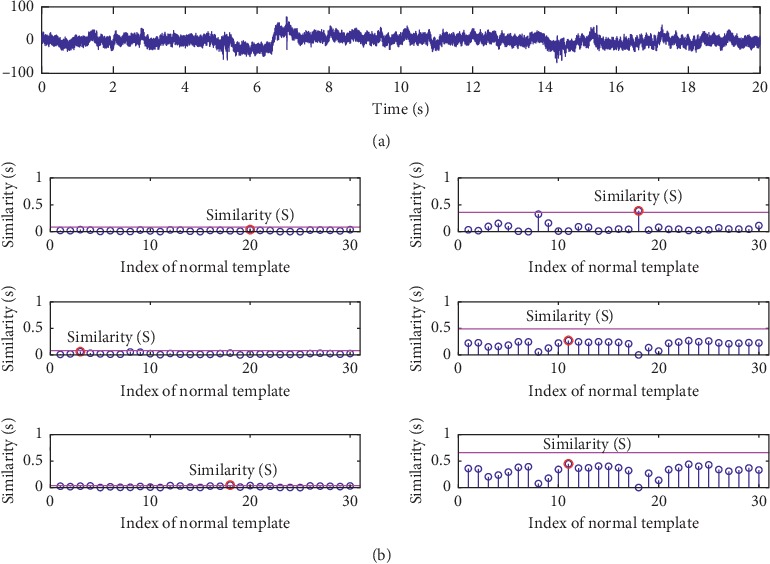
An example of the similarity scores for an abnormal testing data in our database. The similarities S between the testing data and the template set are labelled by red circles. From top to bottom: (a) the original data; (b) the similarities obtained by ED, PCCD, SKLD, HD, KD, and BD.
We summarize the results of investigated metrics by combining their results in two terms of AOPO and accuracy in Table 2. It can be seen that (1) HD and BD are the best metrics in terms of AOPO and (2) HD works best in terms of accuracy.
Table 2.
The compared results of the six metrics in two ways using the testing data of our database for one experiment.
| ED | PCCD | SKLD | HD | KD | BD | |
|---|---|---|---|---|---|---|
| AOPO | 6.5 | 6.5 | 4.5 | 3.5 | 4.5 | 3.5 |
| Accuracy | 0.8167 | 0.7500 | 0.8500 | 0.9167 | 0.8667 | 0.9000 |
The above experimental process was implemented 20 times. In order to analyse all the experimental results, we calculated the average of the AOPO and accuracy values obtained from all experiments based on a global mean measure and show the results in Table 3. It is noticed that the metrics of HD achieve the best performance in terms of AOPO, i.e., 3.65; in terms of accuracy, the HD outperforms others. Based on these results, the investigated metrics can be ranked as HD > BD > KD > SKLD > ED = PCCD.
Table 3.
The mean results using our database for all experiments.
| ED | PCCD | SKLD | HD | KD | BD | |
|---|---|---|---|---|---|---|
| AOPO | 6.75 | 6.35 | 4.85 | 3.65 | 4.75 | 3.70 |
| Accuracy | 0.8033 | 0.7583 | 0.8350 | 0.9133 | 0.8600 | 0.8933 |
5.2. Experiment II: Investigation on Bern-Barcelona Data Set
The result of one repetitive evaluation on the Bern-Barcelona data set is also shown. Figure 8 gives the detection results for all investigated metrics using the training data of the public Bern-Barcelona EEG database. In the left of each subfigure, we show the computed similarities of each testing data. And the similarities are also arranged in ascending order (normal testing data) or descending order (abnormal testing data). Therefore, the AOPOs in this experiment can be gotten. From these results, it can be clearly seen that HD, KD, and BD achieve the best result, the ED and PCCD have achieved not-so-good results, while the SKLD has the worst results. The right of each subfigure in Figure 8 shows the results of all metrics in term of accuracy. It is clear that, for each metric, as λ increases, accuracy increases first and then decreases too. The values of λ corresponding to the highest accuracy which is marked as λ0 are also used to calculate the accuracy of the group 2. Two examples are given in Figures 9 and 10, in which we show the similarity scores of all investigated metrics (using their λ0) for a normal testing recording and an abnormal testing recording. It can be found that all the metrics output the right result for the normal testing data. But for the abnormal testing data, only ED and HD output the correct result. In terms of accuracy, BD, HD, and HD are also better than the others.
Figure 8.
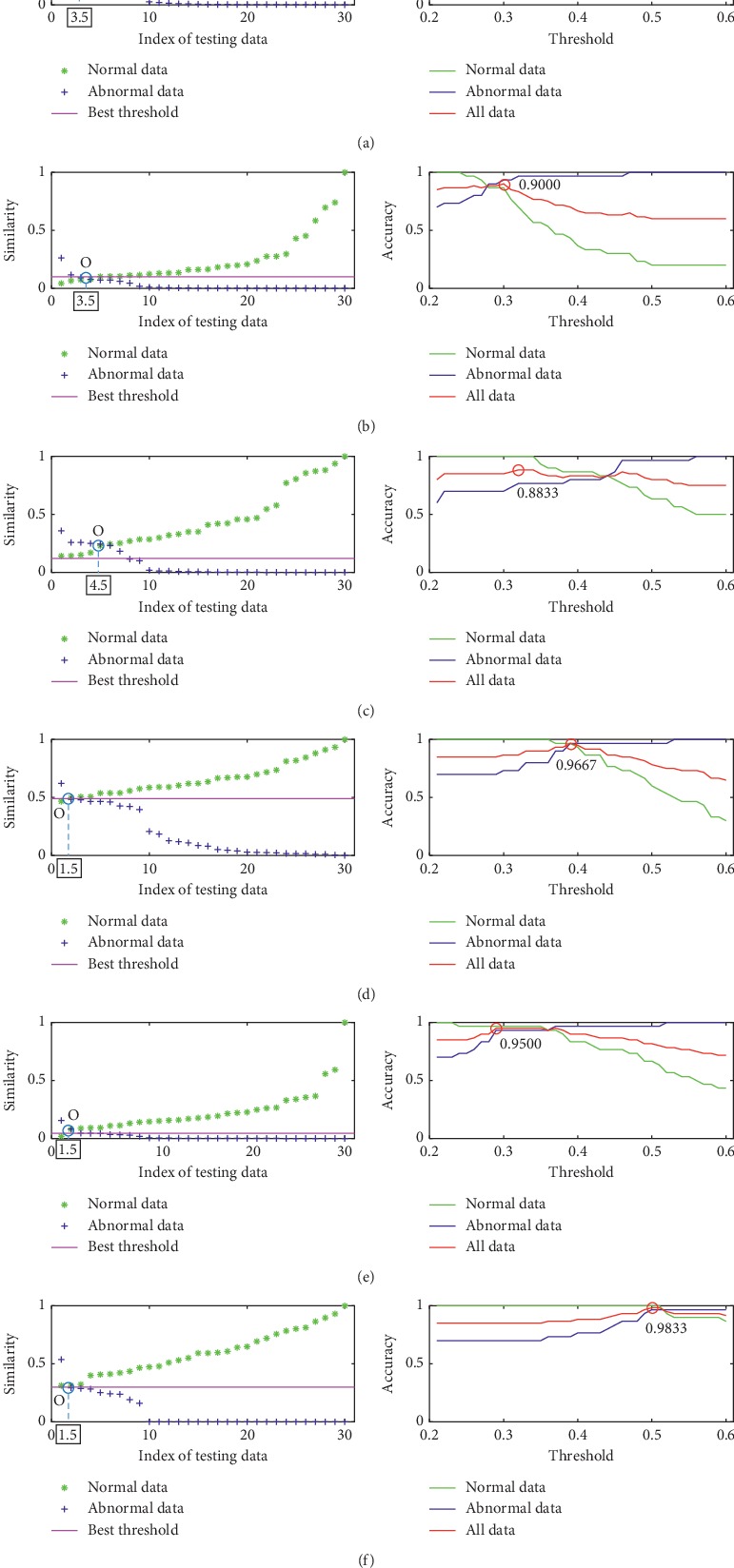
The detail results of six metrics using the training data of the Bern-Barcelona EEG database. From left to right: the similarity between each piece of data in the training data set and the template set; the accuracy of the metric for the normal training data, abnormal training data, and all training data. Detection result by using (a) ED, (b) PCCD, (c) SKLD, (d) HD, (e) KD, and (f) BD.
Figure 9.
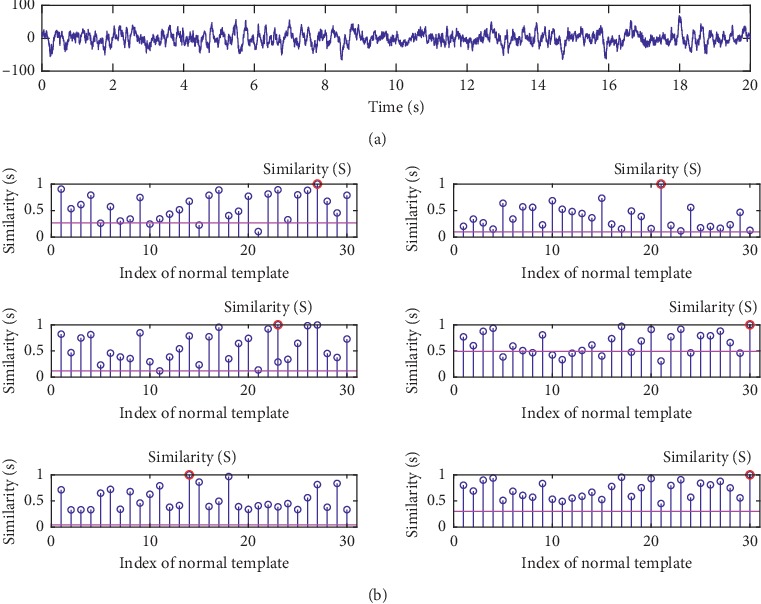
An example of similarity scores for a normal testing data of the Bern-Barcelona EEG database. The similarities S between the testing data and the template set are labelled by red circles. From top to bottom: (a) the original data; (b) the similarities obtained by ED, PCCD, SKLD, HD, KD, and BD.
Figure 10.
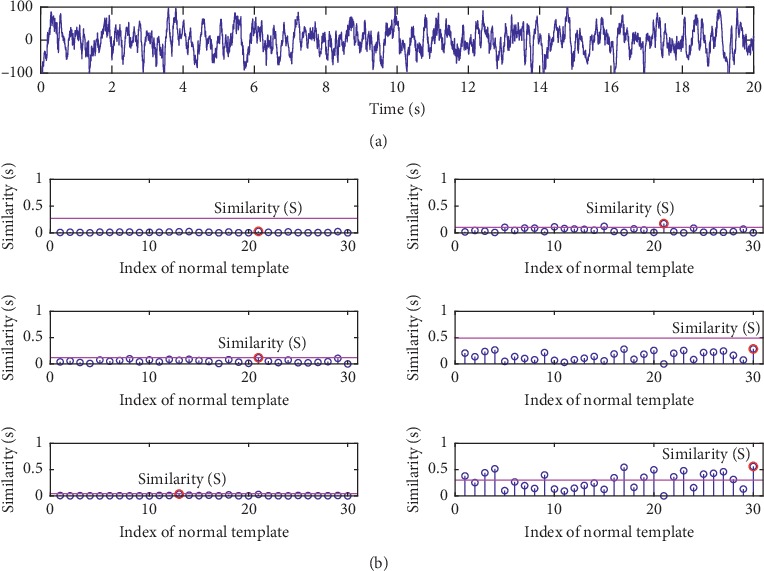
An example of similarity scores for an abnormal testing data of the Bern-Barcelona EEG database. The similarities S between the testing data and the template set are labelled by red circles. From top to bottom: (a) the original data; (b) the similarities obtained by ED, PCCD, SKLD, HD, KD, and BD.
The results of investigated metrics are also summarized in Table 4. It can be clearly seen that, in this experiment, HD, KD, and BD have achieved the best results in terms of AOPO; in terms of accuracy, BD works best.
Table 4.
The compared results of the six metrics in two ways using the testing data of the Bern-Barcelona EEG database for one experiment.
| ED | PCCD | SKLD | HD | KD | BD | |
|---|---|---|---|---|---|---|
| AOPO | 3.5 | 3.5 | 4.5 | 1.5 | 1.5 | 1.5 |
| Accuracy | 0.9167 | 0.8833 | 0.8500 | 0.9500 | 0.9333 | 0.9667 |
The above experimental procedure was also implemented 20 times. The averages of the AOPO and accuracy values obtained from all experiments are shown in Table 5. Therefore, for the Bern-Barcelona EEG database, the metrics of BD achieves the best performance in terms of AOPO, i.e., 1.55; in terms of accuracy, the BD outperforms others. Based on these results, the investigated metrics can be ranked as BD > HD > KD > PCCD > ED > SKLD.
Table 5.
The mean results using the Bern-Barcelona EEG database for all experiments.
| ED | PCCD | SKLD | HD | KD | BD | |
|---|---|---|---|---|---|---|
| AOPO | 3.75 | 3.60 | 4.35 | 1.65 | 1.80 | 1.55 |
| Accuracy | 0.8833 | 0.8883 | 0.8583 | 0.9567 | 0.9250 | 0.9633 |
5.3. Experiment III: Investigation on Effect of Feature Extraction
In order to investigate the effect of feature extraction on detection performance, five representative features including mean, root mean square (RMS), empirical mode decomposition (EMD), discrete wavelet transform (DWT), and artifact subspace reconstruction (ASR) that are used in EEG signal analysis, are investigated in this section. Their operations are provided in Table 6. The processes of similarity measure and decision-making stated in Section 4.2 are also implemented to classify the testing data. The results of AOPO and accuracy of our database are shown in Tables 7 and 8, respectively. The results of the Bern-Barcelona EEG database are shown in Tables 9 and 10, respectively.
Table 6.
Five compared feature extraction methods and the corresponding operations.
| Name | Operation |
|---|---|
| Mean | X Mean=(1/N)∑n=1Nx(n) |
| RMS | |
| EMD | Empirical mode decomposition (EMD) is a method of signal decomposition based on the time-scale characteristics of the data itself, the detailed process of which can refer to [46]. |
| DWT | Discrete wavelet transform (DWT) is a discrete wavelet transform method. Its detailed process can refer to [47]. |
| ASR | Artifact subspace reconstruction (ASR) is relatively new technique, and it is based on new approach of signal reconstruction with the reference signal fragment. The detailed process of ASR can refer to [48]. |
Table 7.
The AOPO results of the seven feature extraction methods using our database.
| ED | PCCD | SKLD | HD | KD | BD | |
|---|---|---|---|---|---|---|
| DFT | 6.5 | 6.5 | 4.5 | 3.5 | 4.5 | 3.5 |
| Mean | 14.5 | 13.5 | 10.5 | 7.5 | 10.5 | 8.5 |
| RMS | 10.5 | 8.5 | 7.5 | 4.5 | 6.5 | 5.5 |
| EMD | 9.5 | 7.5 | 7.5 | 5.5 | 7.5 | 4.5 |
| DWT | 9.5 | 6.5 | 8.5 | 4.5 | 6.5 | 6.5 |
| ASR | 7.5 | 5.5 | 4.5 | 3.5 | 5.5 | 3.5 |
Table 8.
The accuracy results of the seven feature extraction methods using our database.
| ED | PCCD | SKLD | HD | KD | BD | |
|---|---|---|---|---|---|---|
| DFT | 0.8167 | 0.7500 | 0.8500 | 0.9167 | 0.8667 | 0.9000 |
| Mean | 0.5333 | 0.6333 | 0.6833 | 0.7833 | 0.7333 | 0.7500 |
| RMS | 0.6833 | 0.8833 | 0.7667 | 0.9000 | 0.8333 | 0.8833 |
| EMD | 0.7333 | 0.9500 | 0.8667 | 0.9000 | 0.8167 | 0.9167 |
| DWT | 0.7167 | 0.9833 | 0.7667 | 0.8833 | 0.8167 | 0.8500 |
| ASR | 0.8333 | 0.8833 | 0.8500 | 0.9000 | 0.8667 | 0.9167 |
Table 9.
The AOPO results of the seven feature extraction methods using the Bern-Barcelona EEG database.
| ED | PCCD | SKLD | HD | KD | BD | |
|---|---|---|---|---|---|---|
| DFT | 3.5 | 3.5 | 4.5 | 1.5 | 1.5 | 1.5 |
| Mean | 13.5 | 9.5 | 8.5 | 7.5 | 8.5 | 5.5 |
| RMS | 7.5 | 6.5 | 6.5 | 4.5 | 5.5 | 2.5 |
| EMD | 10.5 | 6.5 | 4.5 | 3.5 | 5.5 | 3.5 |
| DWT | 9.5 | 5.5 | 7.5 | 4.5 | 6.5 | 3.5 |
| ASR | 7.5 | 3.5 | 4.5 | 1.5 | 6.5 | 2.5 |
Table 10.
The accuracy results of the seven feature extraction methods using the Bern-Barcelona EEG database.
| ED | PCCD | SKLD | HD | KD | BD | |
|---|---|---|---|---|---|---|
| DFT | 0.9167 | 0.8833 | 0.8500 | 0.9500 | 0.9333 | 0.9667 |
| Mean | 0.5833 | 0.6333 | 0.7667 | 0.7833 | 0.7333 | 0.8333 |
| RMS | 0.7333 | 0.8833 | 0.8167 | 0.9167 | 0.8500 | 0.9333 |
| EMD | 0.6167 | 0.7833 | 0.8833 | 0.9167 | 0.8167 | 0.8833 |
| DWT | 0.7500 | 0.8333 | 0.8167 | 0.8833 | 0.8667 | 0.9000 |
| ASR | 0.7333 | 0.8667 | 0.8500 | 0.9333 | 0.7833 | 0.9167 |
From the results shown in Table 7, we can see that, for our database, in terms of AOPO, the metrics of HD and BD perform better than others when using different features. Table 8 shows the results in term of accuracy. We see that the metrics of HD and BD performs better than others when using DFT, mean, RMS, and ASR; in comparison, PCCD also shows exciting results when using the features of EMD and DWT. Tables 9 and 10 show the detection results for the Bern-Barcelona EEG database. It can be clearly seen that the metrics of HD and BD perform better than other alternatives in both terms of AOPO and accuracy.
To summarize all these results, it can be also noted that, ED, as the most commonly used indicator, performs the worst in terms of AOPO and accuracy for both testing data sets. PCCD, SKLD, and KD have achieved not-so-good results. Among all investigated metrics, the metrics of HD and BD are more suitable for EEG signal analysis.
5.4. Result Summary and Discussion
Combining the results from two tested data sets, it is clear that HD and BD achieve a better performance than the other compared metrics. Recall that both BD and HD are obtained by certain transformations of the Bhattacharyya coefficient BC(P, Q), i.e.,
| (19) |
In this regard, HD and BD are thought of as an approximately equivalent measurement of two statistical samples. The difference between them is the sensitivity to noise, as discussed in [49]. However, it is very difficult to determine which of them is more appropriate for analysing the highly noisy EEG signals. As a potential solution of taking advantages of them, one can combine them using machine learning-based optimization methods, such as inputs selection and inputs weighting [50–52], to form an integrated metric to measure the considered EEG recordings. This also comprises the direction of our future work.
6. Conclusions
Anomaly EEG detection is a long-standing problem in analysis of EEG signals. The basic premise of this problem is consideration of the similarity between two nonstationary EEG recordings, where a well-established scheme is based on sequence matching. Typically, this scheme includes three steps: feature extraction, similarity measure, and decision-making. Current approaches mainly focus on EEG feature extraction and decision-making, and few of them involve the similarity measure/quantification. Generally, to design an appropriate similarity metric, that is compatible with the considered problem/data, is also an important issue in the design of such detection systems. It is however impossible to directly apply those existing metrics to anomaly EEG detection without any consideration of domain specificity. The main objective of this work is to investigate the impacts of different similarity metrics on anomaly EEG detection. A few metrics that is potentially available for the EEG analysis have been collected from other areas by a careful review of related works, including Euclidean distance (ED), Hellinger distance (HD), Bhattacharyya distance (BD), Kolmogorov distance (KD), Pearson correlation coefficient distance (PCCD), and Symmetric Kullback–Leibler divergence (SKLD). Experiments were conducted on two data sets to investigate them. Based on the results shown in Section 5, the following are found:
Experimental results demonstrate the positive impacts of different similarity metrics on anomaly EEG detection. Especially, the commonly used ED did not achieve satisfactory results when compared with other metrics. One main reason is that this metric does not consider the possibly different weight of each element in two compared EEG samples.
Among all investigated metrics, the HD and BD metrics, that are constructed based on the Bhattacharyya coefficient, show excellent performances. They achieved excellent performances for two inspected data sets: an AOPO value of 3.5 and an accuracy of 0.9167 for our data set and an AOPO value of 1.5 and an accuracy of 0.9667 for the Bern-Barcelona EEG data set. These findings reflect the priority of the Bhattacharyya coefficient when dealing with the highly noisy EEG signals. This study provides a preliminary basis for analysing the EEG data.
In order to take advantages of the Bhattacharyya coefficient, we will exploit an integrated metric combining HD and BD for similarity measure of EEG signals in the future work.
Acknowledgments
This study was supported by the Shandong Provincial Natural Science Foundation, China (ZR2019MEE063) and the Fundamental Research Funds of Shandong University (2018JC010).
Abbreviations
- AOPO:
The abscissa of point O
- BD:
Bhattacharyya distance
- DFT:
Discrete Fourier transform
- ED:
Euclidean distance
- EEG:
Electroencephalogram
- HD:
Hellinger distance
- KD:
Kolmogorov distance
- PCCD:
Pearson correlation coefficient distance
- SKLD:
Symmetric Kullback–Leibler divergence Notations
- d:
The distance calculated through the metrics
- P, Q:
Two given probability functions
- p(k):
The kth point of series P
- q(k):
The kth point of series Q
- :
The power spectrum of x
- :
The power spectrum of y
- :
An EEG recording that is not equivalent to both and
- :
The similarity between and
- S(xi):
The similarity between xi and the template set {yi}
- x(n):
The nth point of a given EEG recording
- x′(n):
The nth point of resulting EEG data after filtering
- xi:
The ith of EEG recording of the testing data set
- X(k):
The k point of the frequency spectrum of x(n)
- yj:
The jth EEG recording of the template set
- λ:
The threshold used for hypothesis testing.
Contributor Information
Guoliang Lu, Email: luguoliang@sdu.edu.cn.
Wei Shang, Email: wshang85@aliyun.com.
Data Availability
The data used to support the findings of this study are available from the corresponding author upon request.
Conflicts of Interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
References
- 1.Gajic D., Djurovic Z., Gligorijevic J., Di Gennaro S., Savic-Gajic I. Detection of epileptiform activity in EEG signals based on time-frequency and non-linear analysis. Frontiers in Computational Neuroscience. 2015;9:p. 38. doi: 10.3389/fncom.2015.00038. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Sikdar D., Roy R., Mahadevappa M. Epilepsy and seizure characterisation by multifractal analysis of EEG subbands. Biomedical Signal Processing and Control. 2018;41:264–270. doi: 10.1016/j.bspc.2017.12.006. [DOI] [Google Scholar]
- 3.Tzallas A. T., Tsipouras M. G., Fotiadis D. I. Automatic seizure detection based on time-frequency analysis and artificial neural networks. Computational Intelligence and Neuroscience. 2007;2007:13. doi: 10.1155/2007/80510.80510 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Hassan A. R., Subasi A. A decision support system for automated identification of sleep stages from single-channel EEG signals. Knowledge-Based Systems. 2017;128:115–124. doi: 10.1016/j.knosys.2017.05.005. [DOI] [Google Scholar]
- 5.Sors A., Bonnet S., Mirek S., Vercueil L., Payen J.-F. A convolutional neural network for sleep stage scoring from raw single-channel EEG. Biomedical Signal Processing and Control. 2018;42:107–114. doi: 10.1016/j.bspc.2017.12.001. [DOI] [Google Scholar]
- 6.Ranjan R., Arya R., Fernandes S. L., Sravya E., Jain V. A fuzzy neural network approach for automatic k-complex detection in sleep EEG signal. Pattern Recognition Letters. 2018;115:74–83. doi: 10.1016/j.patrec.2018.01.001. [DOI] [Google Scholar]
- 7.Devuyst S., Dutoit T., Stenuit P., Kerkhofs M. Automatic k-complexes detection in sleep EEG recordings using likelihood thresholds. Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology; August 2010; Buenos Aires, Argentina. IEEE; pp. 4658–4661. [DOI] [PubMed] [Google Scholar]
- 8.O’Neill B. R., Handler M. H., Tong S., Chapman K. E. Incidence of seizures on continuous EEG monitoring following traumatic brain injury in children. Journal of Neurosurgery: Pediatrics. 2015;16(2):167–176. doi: 10.3171/2014.12.peds14263. [DOI] [PubMed] [Google Scholar]
- 9.Amorim E., Rittenberger J. C., Zheng J. J., et al. Continuous EEG monitoring enhances multimodal outcome prediction in hypoxic-ischemic brain injury. Resuscitation. 2016;109:121–126. doi: 10.1016/j.resuscitation.2016.08.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Bachmann M., Lass J., Hinrikus H. Single channel EEG analysis for detection of depression. Biomedical Signal Processing and Control. 2017;31:391–397. doi: 10.1016/j.bspc.2016.09.010. [DOI] [Google Scholar]
- 11.Boashash B., Azemi G., Ali Khan N. Principles of time-frequency feature extraction for change detection in non-stationary signals: applications to newborn EEG abnormality detection. Pattern Recognition. 2015;48(3):616–627. doi: 10.1016/j.patcog.2014.08.016. [DOI] [Google Scholar]
- 12.Boashash B., Ouelha S. Automatic signal abnormality detection using time-frequency features and machine learning: a newborn EEG seizure case study. Knowledge-Based Systems. 2016;106:38–50. doi: 10.1016/j.knosys.2016.05.027. [DOI] [Google Scholar]
- 13.Gao Z., Lu G., Yan P., et al. Automatic change detection for real-time monitoring of EEG signals. Frontiers in Physiology. 2018;9:p. 325. doi: 10.3389/fphys.2018.00325. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Van Quyen M. L., Martinerie J., Baulac M., Varela F. Anticipating epileptic seizures in real time by a non-linear analysis of similarity between EEG recordings. Neuroreport. 1999;10(10):2149–2155. doi: 10.1097/00001756-199907130-00028. [DOI] [PubMed] [Google Scholar]
- 15.Gadhoumi K., Lina J.-M., Gotman J. Seizure prediction in patients with mesial temporal lobe epilepsy using EEG measures of state similarity. Clinical Neurophysiology. 2013;124(9):1745–1754. doi: 10.1016/j.clinph.2013.04.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Alotaiby T. N., Alshebeili S. A., Alotaibi F. M., Alrshoud S. R. Epileptic seizure prediction using CSP and LDA for scalp EEG signals. Computational Intelligence and Neuroscience. 2017;2017:11. doi: 10.1155/2017/1240323.1240323 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Jenke R., Peer A., Buss M. Feature extraction and selection for emotion recognition from EEG. IEEE Transactions on Affective Computing. 2014;5(3):327–339. doi: 10.1109/taffc.2014.2339834. [DOI] [Google Scholar]
- 18.Zhang T., Chen W., Li M. AR based quadratic feature extraction in the vmd domain for the automated seizure detection of EEG using random forest classifier. Biomedical Signal Processing and Control. 2017;31:550–559. doi: 10.1016/j.bspc.2016.10.001. [DOI] [Google Scholar]
- 19.Rabbi A. F., Fazel-Rezai R. A fuzzy logic system for seizure onset detection in intracranial EEG. Computational Intelligence and Neuroscience. 2012;2012:12. doi: 10.1155/2012/705140.705140 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Wang X.-W., Nie D., Lu B.-L. Emotional state classification from EEG data using machine learning approach. Neurocomputing. 2014;129:94–106. doi: 10.1016/j.neucom.2013.06.046. [DOI] [Google Scholar]
- 21.Liu Q., Zhao X.-g., Hou Z.-g. Metric learning for event-related potential component classification in EEG signals. Proceedings of the 2014 22nd European Signal Processing Conference (EUSIPCO); September 2014; Lisbon, Portugal. IEEE; pp. 2005–2009. [Google Scholar]
- 22.Patra B. K., Launonen R., Ollikainen V., Nandi S. A new similarity measure using Bhattacharyya coefficient for collaborative filtering in sparse data. Knowledge-Based Systems. 2015;82:163–177. doi: 10.1016/j.knosys.2015.03.001. [DOI] [Google Scholar]
- 23.Sidorov G., Gelbukh A., Gómez-Adorno H., Pinto D. Soft similarity and soft cosine measure: similarity of features in vector space model. Computación y Sistemas. 2014;18(3):491–504. doi: 10.13053/cys-18-3-2043. [DOI] [Google Scholar]
- 24.Lin L., Wang G., Zuo W., Feng X., Zhang L. Cross-domain visual matching via generalized similarity measure and feature learning. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2017;39(6):1089–1102. doi: 10.1109/tpami.2016.2567386. [DOI] [PubMed] [Google Scholar]
- 25.Chen G., Lu G., Shang W., Xie Z. Automated change-point detection of EEG signals based on structural time-series analysis. IEEE Access. 2019;7:180168–180180. doi: 10.1109/access.2019.2956768. [DOI] [Google Scholar]
- 26.Pimentel M. A. F., Clifton D. A., Clifton L., Tarassenko L. A review of novelty detection. Signal Processing. 2014;99:215–249. doi: 10.1016/j.sigpro.2013.12.026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Delorme A., Sejnowski T., Makeig S. Enhanced detection of artifacts in EEG data using higher-order statistics and independent component analysis. Neuroimage. 2007;34(4):1443–1449. doi: 10.1016/j.neuroimage.2006.11.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Giannakakis G., Sakkalis V., Pediaditis M., Tsiknakis M. Modern Electroencephalographic Assessment Techniques. Berlin, Germany: Springer; 2014. Methods for seizure detection and prediction: an overview; pp. 131–157. [DOI] [Google Scholar]
- 29.Alamuri M., Surampudi B. R., Negi A. A survey of distance/similarity measures for categorical data. Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN); July 2014; Beijing, China. IEEE; pp. 1907–1914. [DOI] [Google Scholar]
- 30.Papadimitriou P., Dasdan A., Garcia-Molina H. Web graph similarity for anomaly detection. Journal of Internet Services and Applications. 2010;1(1):19–30. doi: 10.1007/s13174-010-0003-x. [DOI] [Google Scholar]
- 31.Dokmanic I., Parhizkar R., Ranieri J., Vetterli M. Euclidean distance matrices: essential theory, algorithms, and applications. IEEE Signal Processing Magazine. 2015;32(6):12–30. doi: 10.1109/msp.2015.2398954. [DOI] [Google Scholar]
- 32.Whitlock M. C., Schluter D. The Analysis of Biological Data. Greenwood Village, CO, USA: Roberts and Company Publishers; 2009. [Google Scholar]
- 33.Hershey J. R., Olsen P. A. Approximating the Kullback Leibler divergence between Gaussian mixture models. Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07; April 2007; Honolulu, HI, USA. IEEE; [DOI] [Google Scholar]
- 34.Kullback S. Information Theory and Statistics. Chelmsford, MA, USA: Courier Corporation; 1997. [Google Scholar]
- 35.Tabibian S., Akbari A., Nasersharif B. Speech enhancement using a wavelet thresholding method based on symmetric Kullback-Leibler divergence. Signal Processing. 2015;106:184–197. doi: 10.1016/j.sigpro.2014.06.027. [DOI] [Google Scholar]
- 36.Hellinger E. Neue begründung der theorie quadratischer formen von unendlichvielen veränderlichen. Journal für die Reine und Angewandte Mathematik (Crelles Journal) 1909;1909(136):210–271. doi: 10.1515/crll.1909.136.210. [DOI] [Google Scholar]
- 37.Kolmogorov A. Contributions to Statistics. Amsterdam, Netherlands: Elsevier; 1965. On the approximation of distributions of sums of independent summands by infinitely divisible distributions; pp. 159–174. [Google Scholar]
- 38.Fuchs C. A., van de Graaf J. Cryptographic distinguishability measures for quantum-mechanical states. IEEE Transactions on Information Theory. 1999;45(4):1216–1227. doi: 10.1109/18.761271. [DOI] [Google Scholar]
- 39.Laurent H., Doncarli C. Stationarity index for abrupt changes detection in the time-frequency plane. IEEE Signal Processing Letters. 1998;5(2):43–45. doi: 10.1109/97.659547. [DOI] [Google Scholar]
- 40.Bhattacharyya A. On a measure of divergence between two statistical populations defined by their probability distributions. Bulletin of the Calcutta Mathematical Society. 1943;35:99–110. [Google Scholar]
- 41.Andrzejak R. G., Schindler K., Rummel C. Nonrandomness, nonlinear dependence, and nonstationarity of electroencephalographic recordings from epilepsy patients. Physical Review E. 2012;86(4) doi: 10.1103/physreve.86.046206.046206 [DOI] [PubMed] [Google Scholar]
- 42.Hassan A. R., Siuly S., Zhang Y. Epileptic seizure detection in EEG signals using tunable-Q factor wavelet transform and bootstrap aggregating. Computer Methods and Programs in Biomedicine. 2016;137:247–259. doi: 10.1016/j.cmpb.2016.09.008. [DOI] [PubMed] [Google Scholar]
- 43.Kellaway P. Current Practice: Clinical Electroencephalography. New York, NY, USA: Raven Press; 1990. An orderly approach to visual analysis: characteristics of the normal EEG of adults and children; pp. 139–199. [Google Scholar]
- 44.Subasi A., Ismail Gursoy M. EEG signal classification using PCA, ICA, LDA and support vector machines. Expert Systems with Applications. 2010;37(12):8659–8666. doi: 10.1016/j.eswa.2010.06.065. [DOI] [Google Scholar]
- 45.Başar E., Güntekin B. Supplements to Clinical Neurophysiology. Vol. 62. Amsterdam, Netherlands: Elsevier; 2013. Review of delta, theta, alpha, beta, and gamma response oscillations in neuropsychiatric disorders; pp. 303–341. [DOI] [PubMed] [Google Scholar]
- 46.Li S., Zhou W., Yuan Q., Geng S., Cai D. Feature extraction and recognition of ictal EEG using EMD and SVM. Computers in Biology and Medicine. 2013;43(7):807–816. doi: 10.1016/j.compbiomed.2013.04.002. [DOI] [PubMed] [Google Scholar]
- 47.Kumar Y., Dewal M. L., Anand R. S. Epileptic seizures detection in EEG using DWT-based ApEn and artificial neural network. Signal, Image and Video Processing. 2014;8(7):1323–1334. doi: 10.1007/s11760-012-0362-9. [DOI] [Google Scholar]
- 48.Plechawska-Wojcik M., Kaczorowska M., Zapala D. The artifact subspace reconstruction (ASR) for EEG signal correction. A comparative study. Proceedings of the 2018 International Conference on Information Systems Architecture and Technology; September 2018; Nysa, Poland. Springer; pp. 125–135. [DOI] [Google Scholar]
- 49.Bhattacharya A., Kar P., Pal M. On low distortion embeddings of statistical distance measures into low dimensional spaces. Proceedings of the International Conference on Database and Expert Systems Applications; August 2009; Linz, Austria. Springer; pp. 164–172. [DOI] [Google Scholar]
- 50.Haghighat M., Abdel-Mottaleb M., Alhalabi W. Discriminant correlation analysis: real-time feature level fusion for multimodal biometric recognition. IEEE Transactions on Information Forensics and Security. 2016;11(9):1984–1996. doi: 10.1109/tifs.2016.2569061. [DOI] [Google Scholar]
- 51.Du P., Liu S., Xia J., Zhao Y. Information fusion techniques for change detection from multi-temporal remote sensing images. Information Fusion. 2013;14(1):19–27. doi: 10.1016/j.inffus.2012.05.003. [DOI] [Google Scholar]
- 52.Paul S., Das S. Simultaneous feature selection and weighting—an evolutionary multi-objective optimization approach. Pattern Recognition Letters. 2015;65:51–59. doi: 10.1016/j.patrec.2015.07.007. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data used to support the findings of this study are available from the corresponding author upon request.