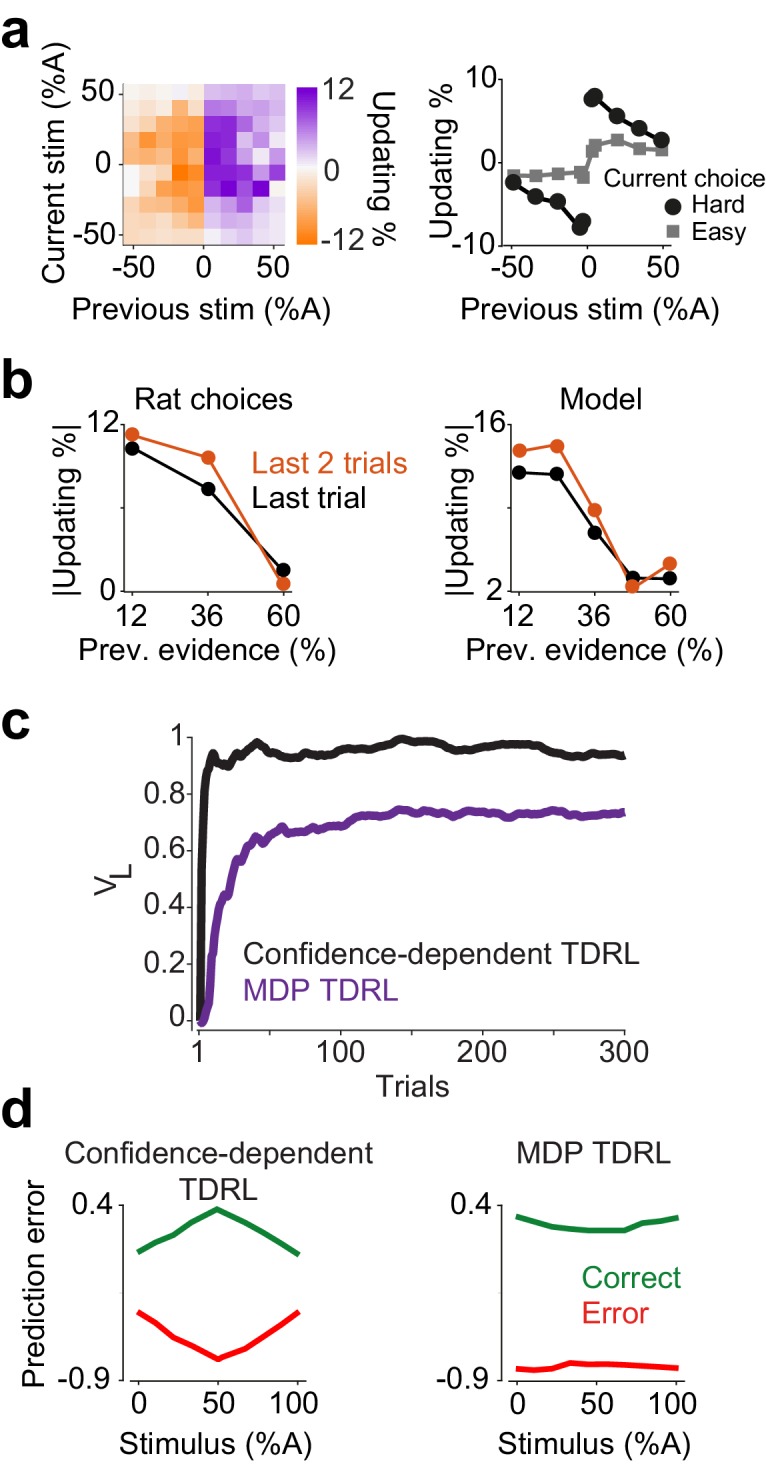
Figure 3. Belief-based reinforcement learning model accounts for choice updating.
(a) Left: schematics of the temporal difference reinforcement learning (TDRL) model that includes belief state reflecting perceptual decision confidence. Right: predicted values and reward prediction errors of the model. After receiving a reward, reward prediction errors depend on the difficulty of the choice and are largest after a hard decision. Reward prediction errors of this model are sufficient to replicate our observed choice updating effect. (b) Choice updating of the model shown in a. This effect can be observed even after correcting for non-specific drifts in the choice bias (right panel). The model in all panels had =0.2 and =0.5. (c) A TDRL model which follows a Markov decision process (MDP) and that does not include decision confidence into prediction error computation produces choice updating that is largely independent of the difficulty of the previous decision. (d) A MDP TDRL model that includes slow non-specific drift in choice bias fails to produce true choice updating. The normalization removes the effect of drift in the choice bias, but leaves the difficulty-independent effect of past reward (e) A MDP TDRL model that includes win-stay-lose-switch strategy fails to produce true choice updating. For this simulation, win-stay-lose-switch strategy is applied to 10% of randomly-selected trials. See Figure 3—figure supplement 1 and the Materials and methods for further details of the models.

Figure 3—figure supplement 1. Further characteristics of the confidence-dependent TDRL model and the MDP TDRL model.