
Figure 2.
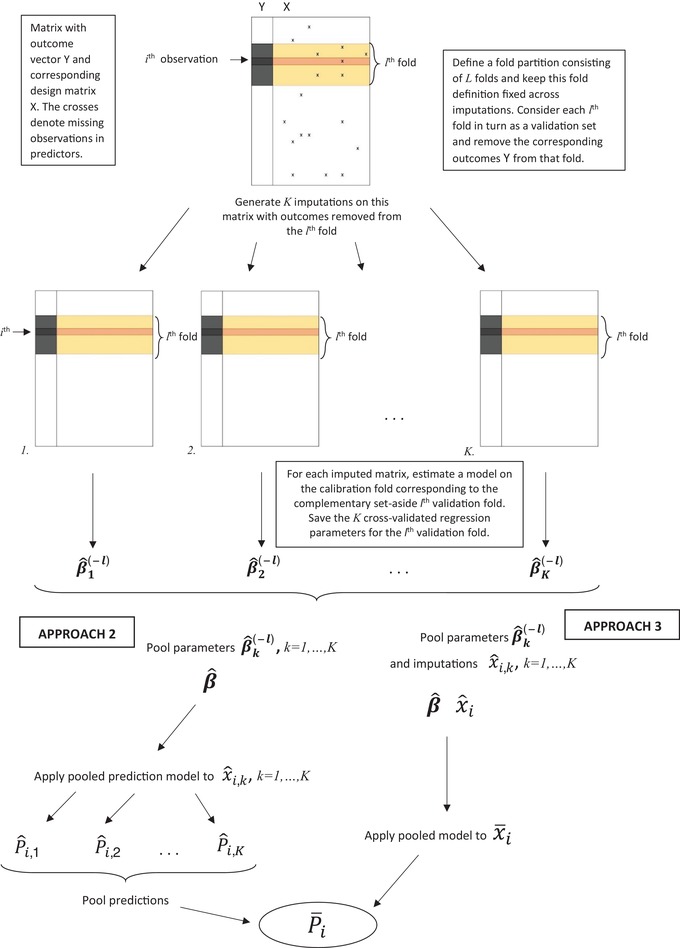
Approaches 2 and 3 use the same fold‐partition across K copies of the data matrix. To generate cross‐validated predictions for each (validation) fold, outcomes are first removed from that fold and K imputations (multiple) are performed on this outcome‐deleted matrix. K models are then generated on the K imputed calibration portions of the data, which are combined in a pooled model. This combined model is then applied to the (imputed) data in the set‐aside validation folds