
Figure 1:
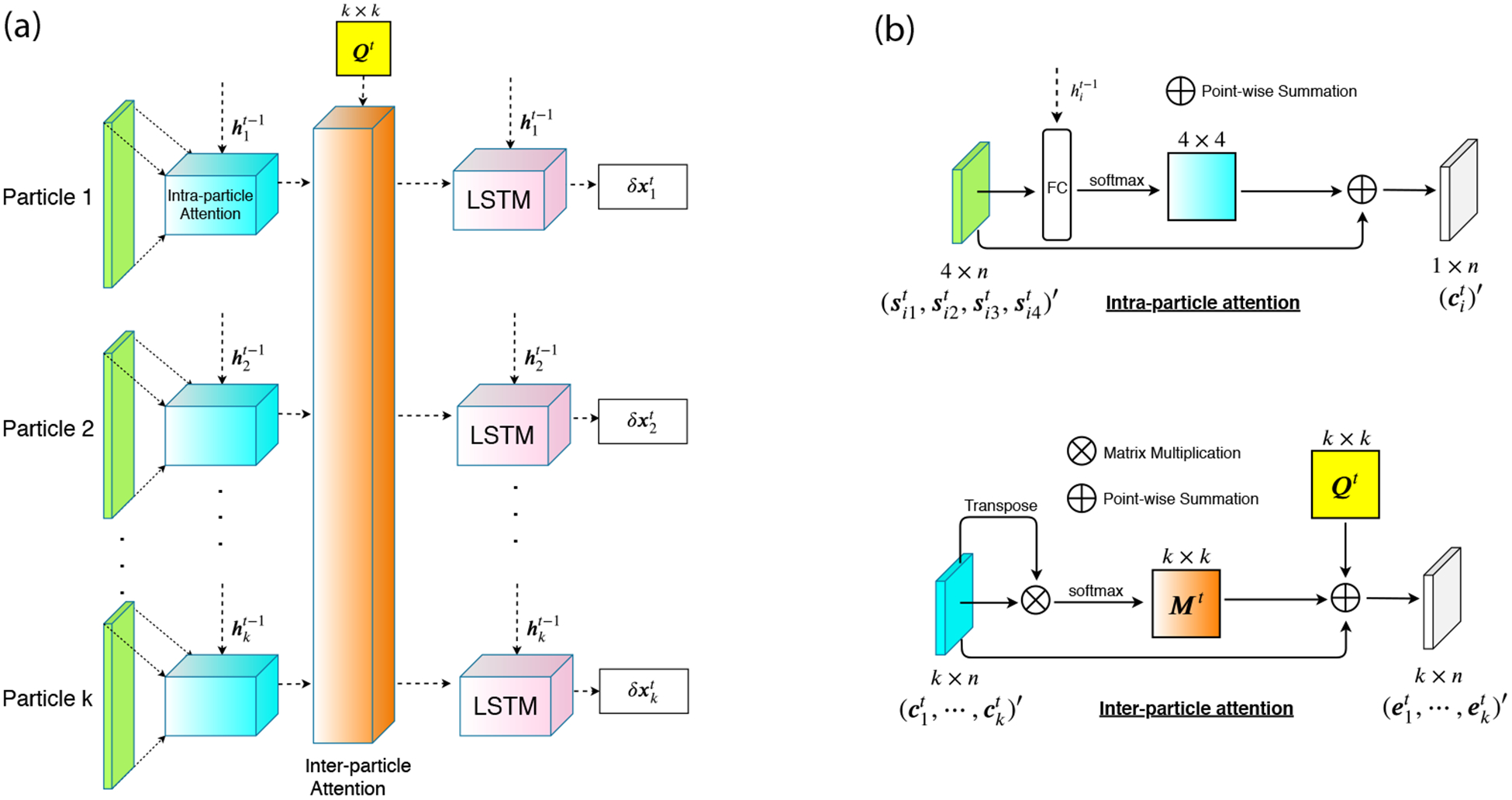
(a) The architecture of our meta-optimizer for one step. We have k particles here. For each particle, we have gradient, momentum, velocity and attraction as features. Features for each particle will be sent into an intra-particle (feature-level) attention module, together with the hidden state of the previous LSTM. The outputs of k intra-particle attention modules, together with a kernelized pairwise similarity matrix Qt (yellow box in the figure), will be the input of an inter-particle (sample-level) attention module. The role of inter-particle attention module is to capture the cooperativeness of all particles in order to reweight features and send them into k LSTMs. The LSTM’s outputs, δx, will be used for generating new samples. (b) The architectures of intra- and inter-particle attention modules.