
Fig. 4. Performance of model variants with and without stimulus-driven theta oscillator on compressed speech.
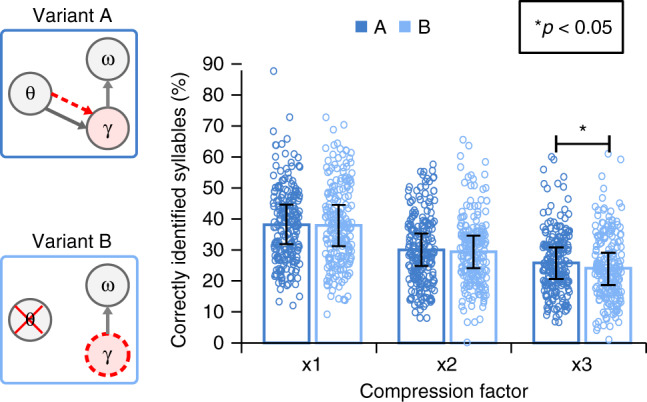
The bar plots represent the mean values (n = 210 samples) for each three compression factors (x1 stands for natural speech) with error bars showing standard deviation. For compression factor 3, there is a statistically significant difference in performance between models with stimulus-driven (A dark blue, 25.84% ± 10.2) versus endogenous (B light blue, 24.1% ± 10.6) theta oscillations (1-tailed t-test, p = 0.0248, t-value = 1.97, degrees of freedom = 209, s.d. = 12.76).