
Figure 2:
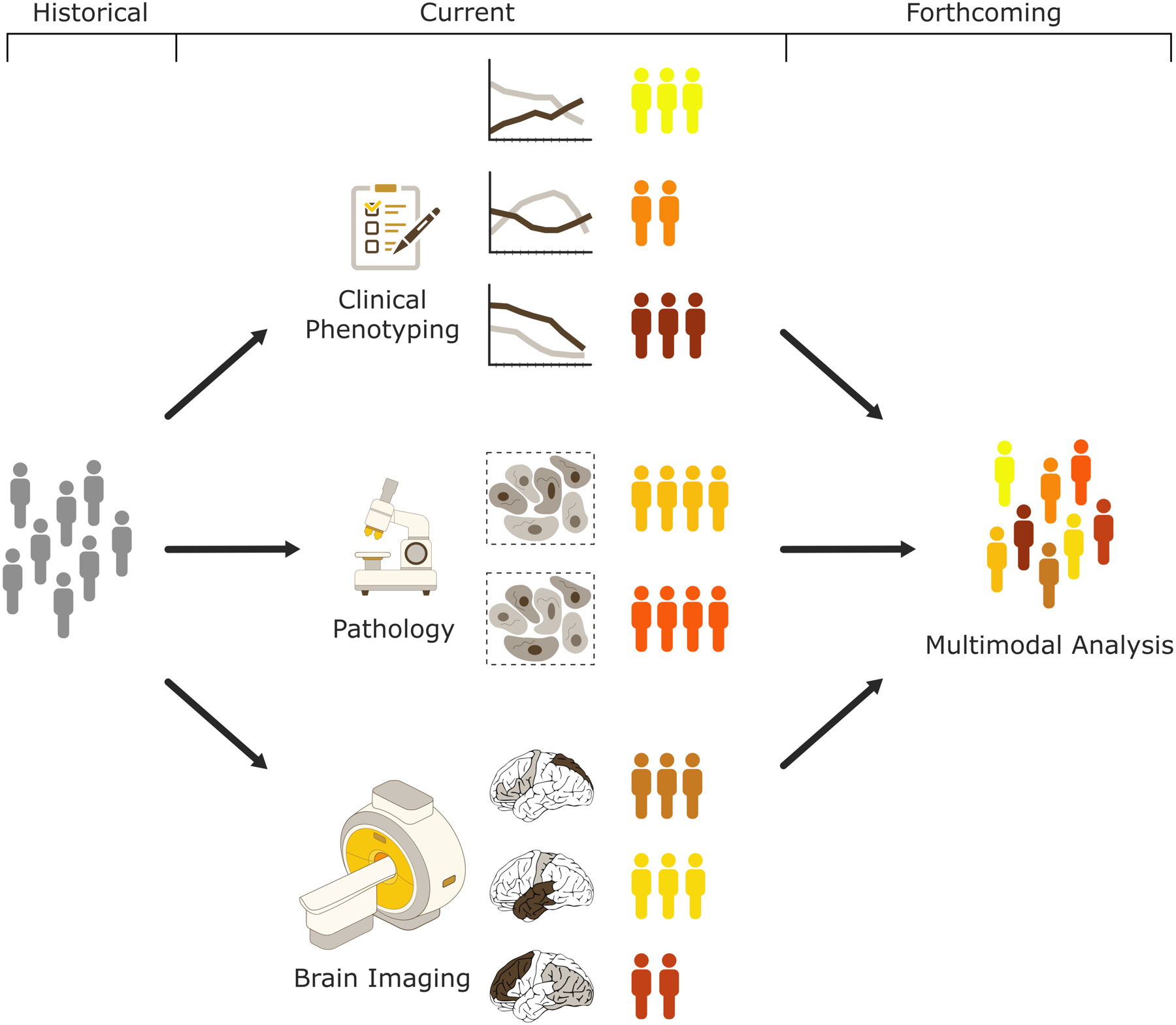
Over the past decade data-driven clustering approaches have helped in making new discoveries of previously unappreciated subtypes for the ADRD conditions, offering novel frameworks for improving individualized diagnosis and prognosis. Often these approaches made use of either simplistic metrics from multiple modalities or high-dimensional data from one single modality. As more phenotypic information is being collected within large-scale observational cohort studies together with improvements in computational power and algorithmic solutions, future work will incorporate combination of high-dimensional information from multiple modalities (i.e., clinical, pathological, and imaging) that may achieve a more comprehensive definition of distinct disease subtypes in AD and related dementia. Towards that standardization in data acquisition and harmonization between various cohorts is key element for future success for such frameworks implementing data synthesis across the different domains.