
Figure 2.
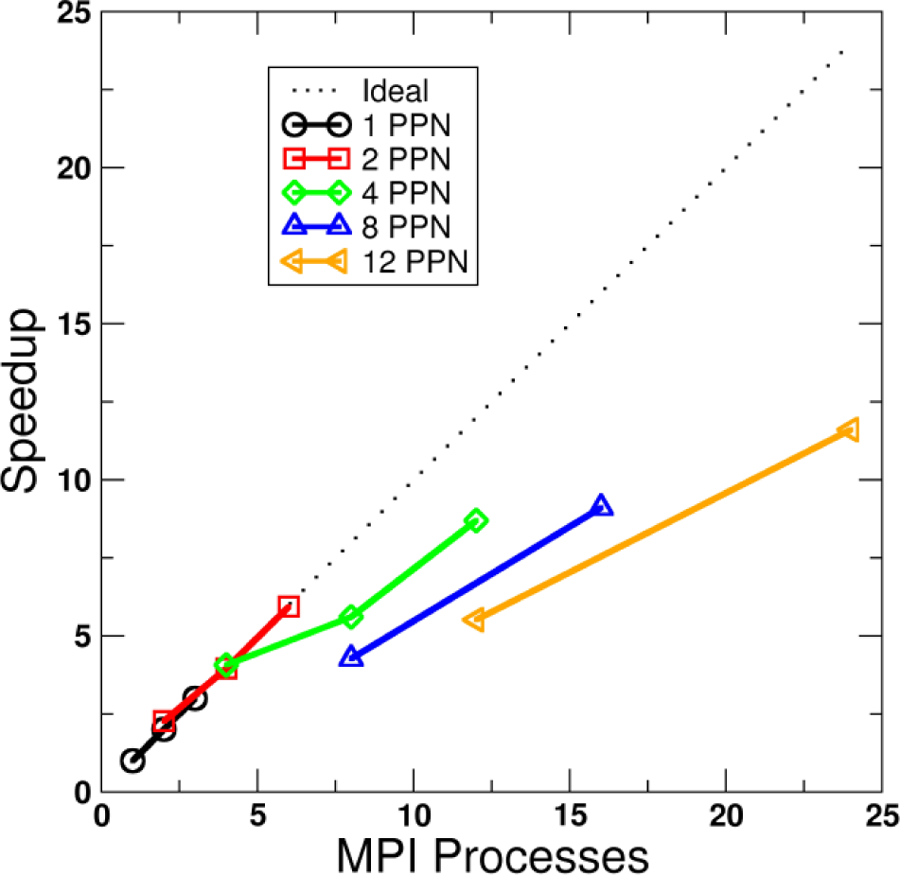
Speedup versus number of MPI processes for across-trajectory parallelization of an RMSD calculation (1293 atoms, 881,372 frames). Each line represents a different number of processes per node (PPN). Raw timing for 1 node, 1 PPN is 590 s. Calculations run on the Ember cluster, CHPC at University of Utah (Westmere 2.8 GHz, dual socket six-core nodes, NFS-mount file storage).