
Figure 1.
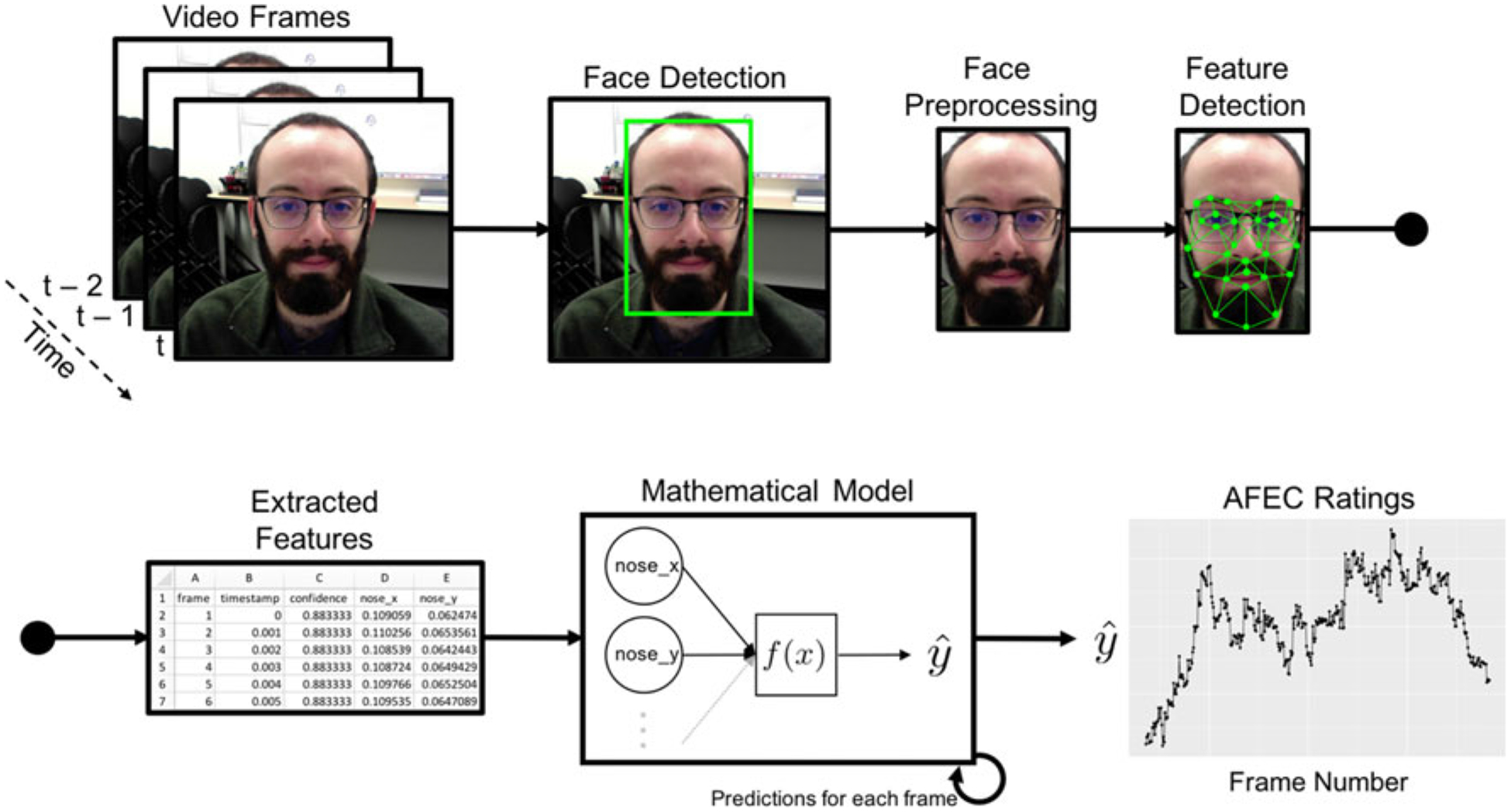
Steps in AFEC modeling. For each video frame (or image), AFEC uses computer-vision technology to detect a face, which is then preprocessed (cropped). Computer-vision then identifies a set of features on the preprocessed face (here represented by an Active Appearance Model that matches a statistical representation of a face to the detected face), which are tabulated and entered into a mathematical model. This model is developed to detect some aspect of emotion from a previously coded set of data (e.g., presence of a discrete emotion, valence intensity, FACS AUs, etc.), and outputs these emotion ratings based on extracted facial features of the new data. Ratings are output for each frame, resulting in a rich time series of emotional expressions. Of note, AFEC models can perform these steps in real time. In some cases, there can be a two-step mathematical model (e.g., FACS detection and then emotion detection given FACS AUs).