
Figure 1:
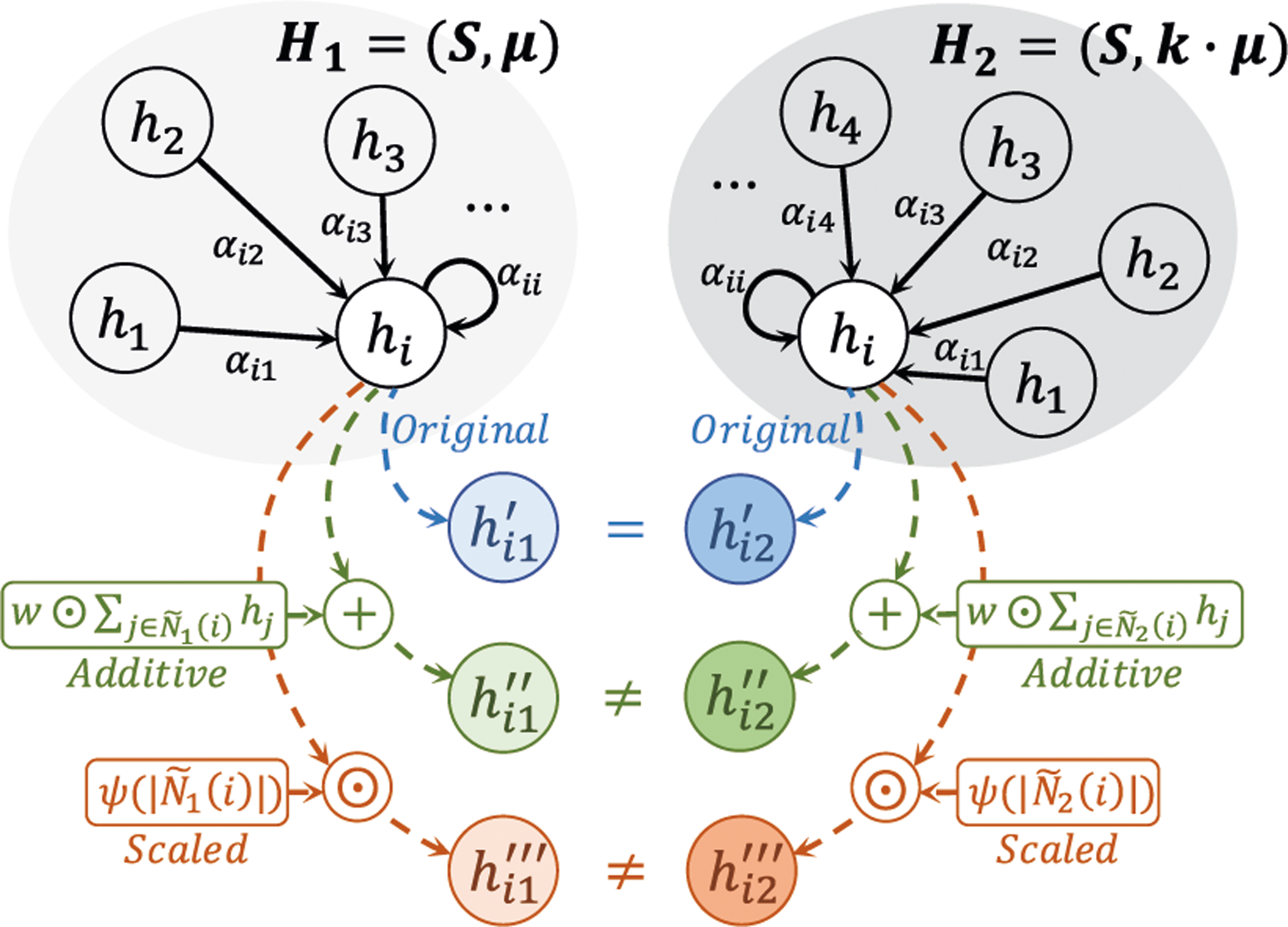
An illustration of different attention-based aggregators on multiset of node features. Given two distinct multisets H1 and H2 that have the same central node feature hi and the same distribution of node features, aggregators will map hi to hi1 and hi2 for H1 and H2. The Original model will get and fail to distinguish H1 and H2, while our Additive and Scaled models can always distinguish H1 and H2 with and .