
Fig. 4 |. Pathology analysis of the misclassification errors on the test sets.
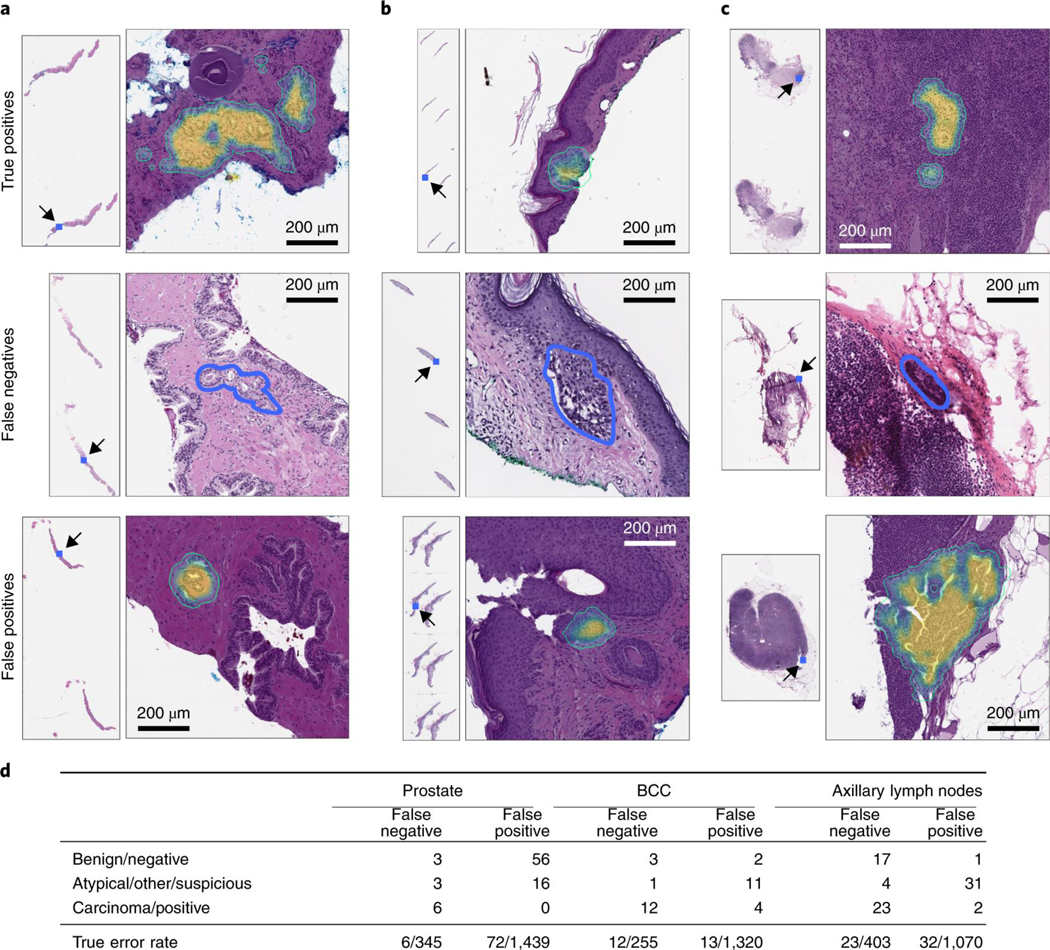
a–c, Randomly selected examples of classification results on the test set. Examples of true positive, false negative and false positive classifications are shown for each tumor type. The MIL-RNN model trained at 20× magnification was run with a step size of 20 pixels across a region of interest, generating a tumor probability heat map. On every slide, the blue square represents the enlarged area. For the prostate dataset (a), the true positive represents a difficult diagnosis due to tumor found next to atrophy and inflammation; the false negative shows a very low tumor volume; and for the false positive the model identified atypical small acinar proliferation, showing a small focus of glands with atypical epithelial cells. For the BCC dataset (b), the true positive has a low tumor volume; the false negative has a low tumor volume; and for the false positive the tongue of the epithelium abutting from the base of the epidermis shows an architecture similar to BCC. For the axillary lymph nodes dataset (c), the true positive shows ITCs with a neoadjuvant chemotherapy treatment effect; the false negative shows a slightly out of focus cluster of ITCs missed due to the very low tumor volume and blurring; and the false positive shows displaced epithelium/benign papillary inclusion in a lymph node. d, Subspecialty pathologists analyzed the slides that were misclassified by the MIL-RNN models. While slides can either be positive or negative for a specific tumor, sometimes it is not possible to diagnose a single slide with certainty based on morphology alone. These cases were grouped into the categories ‘atypical’ and ‘suspicious’ for prostate and breast lesions, respectively. The ‘other’ category consisted of skin biopsies that contained tumors other than BCC. We observed that some of the misclassifications stem from incorrect ground truth labels.