
Figure 3.
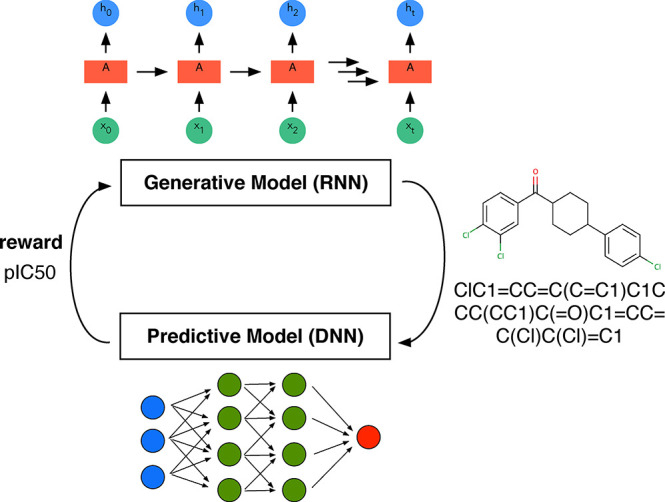
Reinforcement learning scheme illustrated based on the approach chosen by Popova et al.66 for drug design. They use a recurrent neural network (RNN) (cf. section 5.1.1.5) for the generation of simplified molecular input line entry system (SMILES) strings and a deep NN for property prediction. In a first stage, both models are trained separately, and then they are used jointly to bias, using the target properties as the reward, the generation of new molecules. This example also nicely shows that the boundary between the different “flavors” of ML is fuzzy and that they are often used together.