
Figure 1: Distributional value coding arises from a diversity of relative scaling of positive and negative prediction errors.
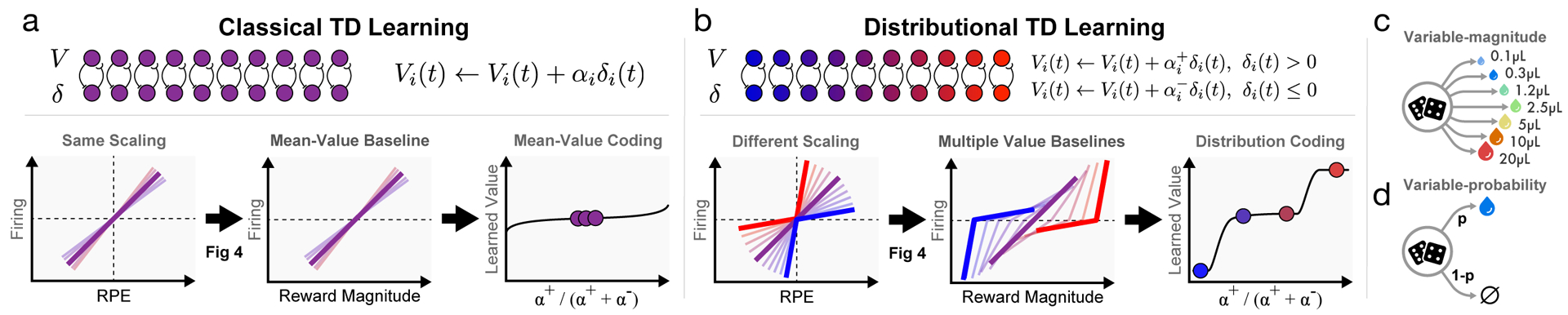
a, In the standard temporal difference (TD) theory of the dopamine system, all value predictors learn the same value V. Each dopamine cell is assumed to have the same relative scaling for positive and negative RPEs (left). This causes each value prediction (or value baseline) to be the mean of the outcome distribution (middle). Dotted lines indicate zero RPE or pre-stimulus firing. b, In our proposed model, distributional TD, different channels have different relative scaling for positive (α+) and negative (α−) RPEs. Red shading indicates α+ > α−, and blue shading indicates α−> α+. An imbalance between α+ and α− causes each channel to learn a different value prediction. This set of value predictions collectively represents the distribution over possible rewards. c, We analyze data from two tasks. In the variable-magnitude task, there is a single cue, followed by a reward of unpredictable magnitude. d, In the variable-probability task, there are three cues, which each signal a different probability of reward, and the reward magnitude is fixed.