
Extended Data Figure 2: Learning the distribution of returns improves performance of deep RL agents across multiple domains.
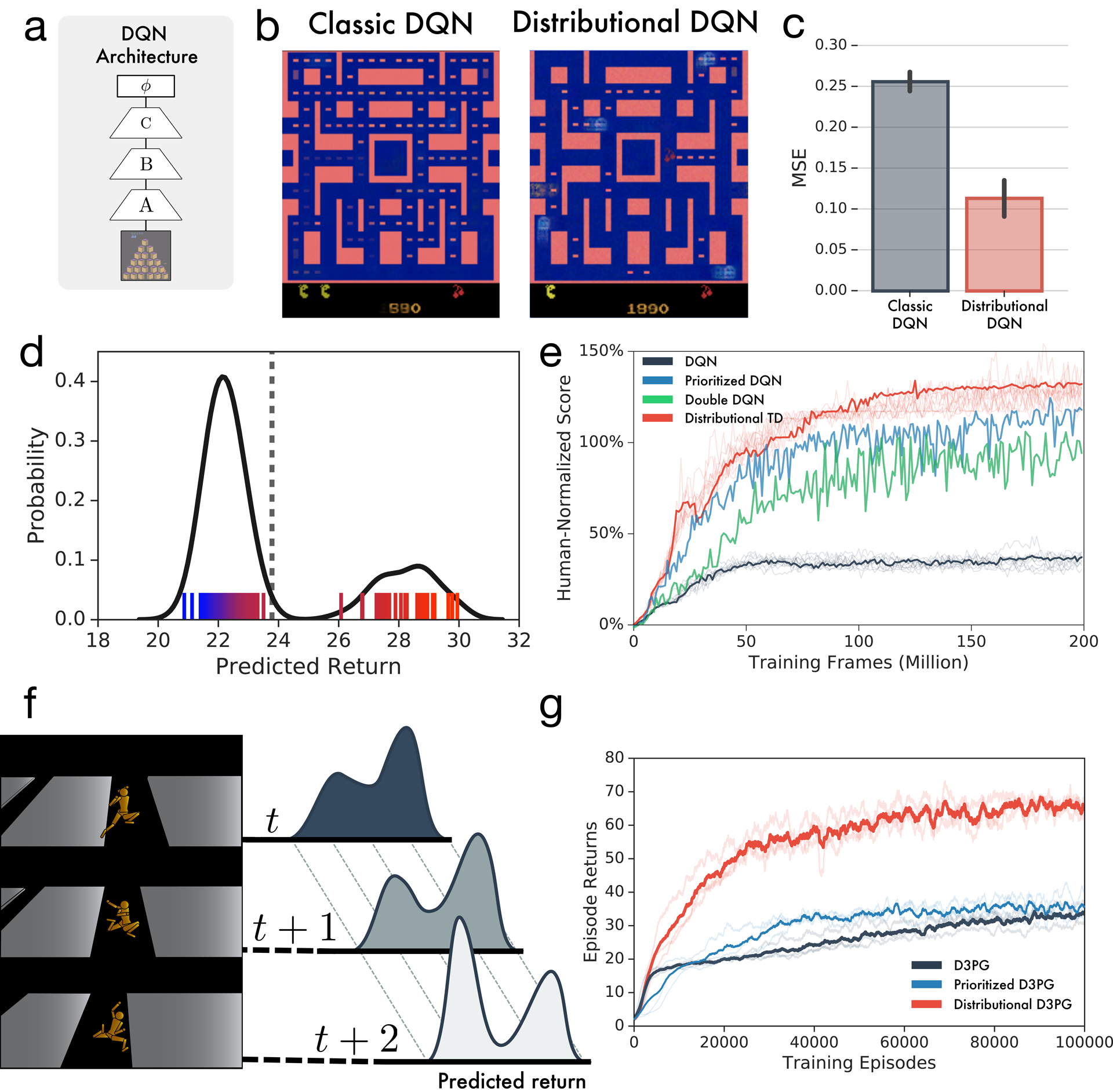
a, DQN and Distributional TD share identical non-linear network structures. b-c, After training classic or distributional DQN on MsPacman, we freeze the agent and then train a separate linear decoder to reconstruct frames from the agent’s final layer representation. For each agent, reconstructions are shown. The distributional model’s representation allows significantly better reconstruction. d, At a single frame of MsPacman (not shown), the agent’s value predictions together represent a probability distribution over future rewards. Reward predictions of individual RPE channels shown as tick marks ranging from pessimistic (blue) to optimistic (red), and kernel density estimate shown in black. e, Atari-57 experiments with single runs of prioritized experience replay40 and double DQN41 agents for reference. Benefits of distributional learning exceed other popular innovations. f-g, The performance payoff of distributional RL can be seen across a wide diversity of tasks. Here we give another example, a humanoid motor-control task in the MuJoCo physics simulator. Prioritized experience replay agent is shown for reference.42 Traces show individual runs, averages in bold.