
Figure 1.
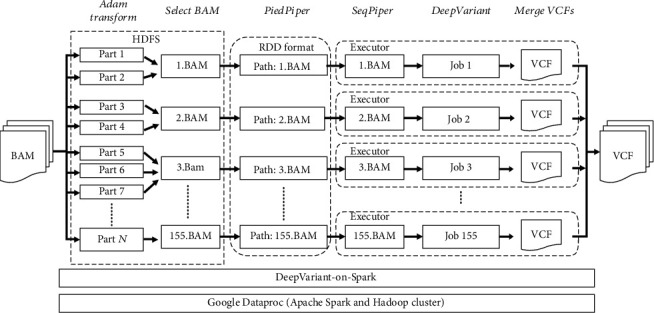
Framework of DeepVaraint-on-Spark. DeepVariant-on-Spark is based on the Google Dataproc service. After importing the BAM file into the DeepVariant-on-Spark cluster, the BAM file will be segmented into several 1 Mbp blocks in the “Adam Transform” step, and these blocks will be merged into 155 small BAM files in the “Select BAM” step. The 1 Mbp blocks and small BAM files are stored in the HDFS. PiedPiper will pipe the path of each BAM file to SeqPiper, which launches DeepVariant to produce the VCF file. Finally, in the “Merge VCFs” steps, each VCF file will be merged into a complete VCF file.