
Fig. 5.
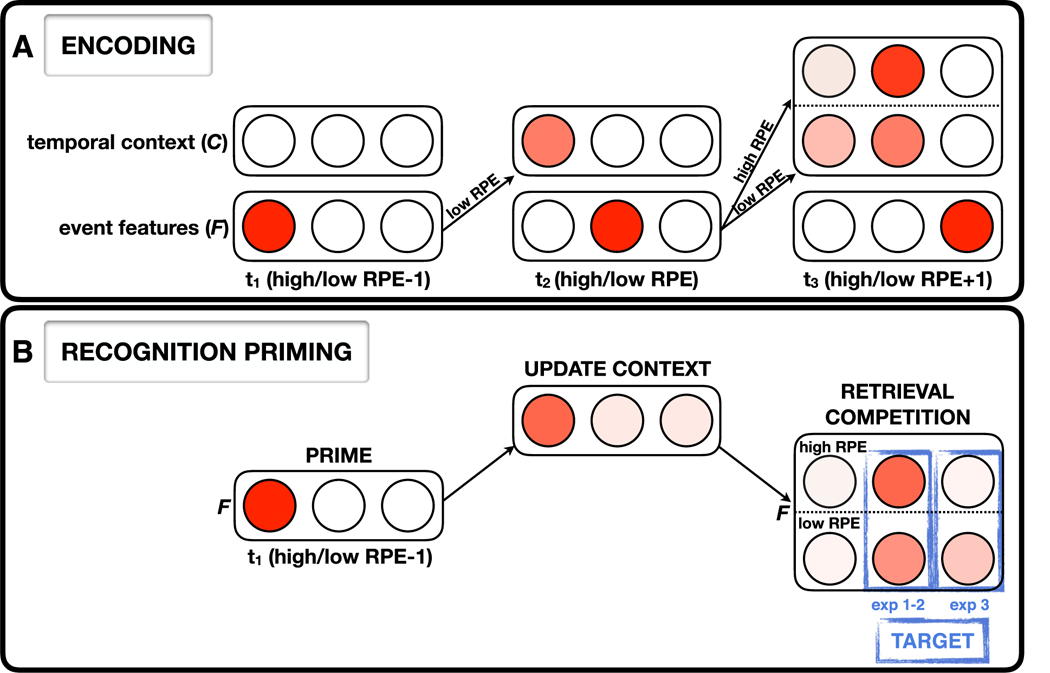
Illustration of how high- versus low-RPE events are encoded and retrieved by the model. A. Encoding. The high-RPE event enters the next event’s context with increased drift, leading to greater activation of the high-RPE event at the expense of the activation of the high-RPE −1 item in context. Learning of context-feature associations in the model is based on co-activity of context and feature units (Hebbian learning); because the high-RPE −1 item is less active in context, it becomes less strongly associated with the high-RPE +1 item in the feature layer. B. Recognition priming. (1) The prime (high/low RPE −1 event) is retrieved by the network, (2) Activation spreads up from F to C via MFC, leading to higher activation of the prime in context, (3) Activation then spreads down from C to F via the MCF, leading to activation of events that contained the prime in their context, (4) The prime strongly cues both the high/low-RPE targets (Exp. 1 and 2). However, when the target item is the high-RPE +1 event (Exp. 3), that item receives less activation because of the weaker association between the high-RPE −1 item (in context) and the high-RPE +1 item (in the feature layer), as mentioned above.