
Figure 1. Overview of the modeling process with DGMs.
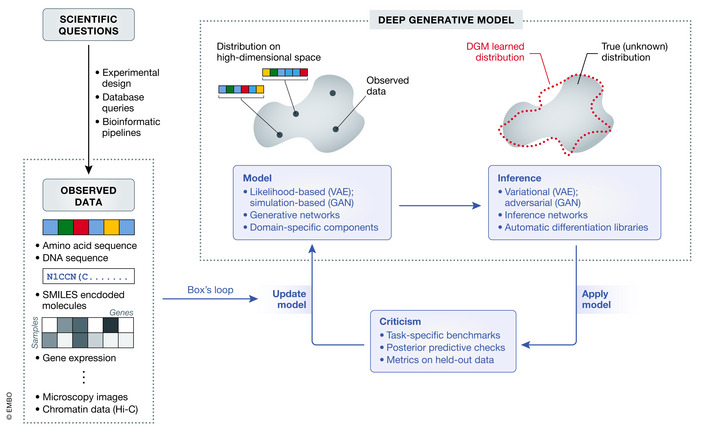
Research in molecular biology stems from the formulation of hypotheses. Such questions can be studied through the lens of a wide variety of data forms such as biological sequences, molecules, gene expression, or imaging data. The broad goal of a DGM is to estimate the distribution that generated the observed data. Constructing a DGM involves iterating through the steps of Box's loop. First, a model with domain‐specific components or assumptions is designed. Second, an inference procedure learns the optimal model parameters. Third, the model is criticized. This step consists of benchmarking the model on data sets and evaluating the goodness of fit of the model. Finally, the model is updated based on the criticism, starting a new iteration of the loop.