

Abstract
Objectives:
Use of observational data to inform the response and care of patients during a pandemic faces unique challenges.
Design:
The Society of Critical Care Medicine Discovery Viral Infection and Respiratory Illness Universal Study COVID 2019 Registry Core data and research methodology team convened over virtual meetings throughout March to June 2020 to determine best practice goals for development of a pandemic disease registry to support rapid data collection and analysis.
Setting:
International, multi-center registry of hospitalized patients.
Patients:
None.
Interventions:
None.
Measurements and Main Results:
Large-scale observational data collection requires: 1) quality assurance and harmonization across many sites; 2) a transparent process for selecting from among many potential research questions; 3) the use of best practices in design of descriptive, predictive, and inferential studies; (4) innovative approaches to characterize random error in the setting of constantly updated data; (5) rapid peer-review and reporting; and (6) transitions from a focus on discovery to implementation. Herein, we describe the guiding principles to best practices and suggestions for innovations to study design and reporting within the coronavirus disease 2019 Viral Infection and Respiratory Illness Universal Study pandemic registry.
Conclusions:
Society of Critical Care Medicine Discovery Viral Infection and Respiratory Illness Universal Study coronavirus disease 2019 registry sought to develop and implement prespecified best practices combined with grassroots efforts from clinical sites worldwide in order to develop clinically useful knowledge in response to a pandemic.
Keywords: big data, coronavirus disease 2019, registries
The early coronavirus disease 2019 (COVID-19) pandemic revealed substantial deficits in current systems used to rapidly generate clinical knowledge. Nonpeer-reviewed preprints, uncontrolled single-center case series with incomplete follow-up, and data of unclear veracity dominated clinical communication during the early months of the COVID-19 pandemic, often spurring uncritical uptake of multiple unproven, untested, and potentially harmful treatment strategies (1–3). Despite the ubiquity of electronic health records and medical journals, healthcare delivery and research infrastructures were not designed to be part of a large-scale, interconnected learning healthcare system that efficiently shares clinical data, conducts reliable studies, evaluates veracity of research, disseminates, and implements new findings.
Generalizable clinical insights may occur via both interventional (e.g., clinical trials) and observational (e.g., cohort studies) methods. Randomized trials are generally best suited to generate evidence regarding efficacy and effectiveness (i.e., estimates of benefit under relaxed inclusion and criteria of real-world scenarios) of novel therapies but often require considerable infrastructures for patient consent, randomization, enrollment, medication delivery and prospective data. Thus, governmental organizations (e.g., Recovery trial) (4) and international trial networks (e.g., Randomised, Embedded, Multi-factorial, Adaptive Platform Trial for Community-Acquired Pneumonia [REMAP-CAP]) (5) were well-positioned to rapidly deploy pragmatic trials during the COVID-19 pandemic. Observational studies generally require fewer site-level resources than clinical trials and can therefore efficiently provide information that is often dependent on large-scale data: epidemiology, health services research, adverse events monitoring—and in some cases—effectiveness (6).
In response to the COVID-19 pandemic, the Society of Critical Care Medicine’s (SCCM’s) Discovery Network Viral Infection and Respiratory Illness Universal Study (VIRUS) (7) was designed to provide a novel infrastructure for observational research during a pandemic. The SCCM VIRUS COVID-19 Registry Core data and research methodology team convened over virtual meetings throughout March to June 2020 to determine best practice goals for development of a pandemic disease registry. Herein, we describe the theoretical background and approach of the SCCM VIRUS study to conduct rapid and transparent observational data collection, analysis, peer review, knowledge dissemination, and implementation during the COVID-19 pandemic (Table 1).
TABLE 1.
Pandemic Registry Common Data Standards for Critically Ill Patients
| Data Goals | Electronic Data Capture |
|---|---|
| Demographic patient profile | Age, gender, race, ethnicity, geographic localization, presentation to healthcare facility, coronavirus disease 2019 testing. |
| Clinical patient profile and processes of care | Signs and symptom, comorbidities, Acute Physiologic Assessment and Chronic Health Evaluation-II score, admission diagnosis, prehome medication, daily laboratories, daily vital signs, daily radiological and cardiology evaluation including electrocardiogram, echocardiogram, daily hospital medication/therapy, ventilator-associated pneumonia bundle compliance. |
| ICU and hospital-related outcomes | ICU length of stay, hospital length of stay, need of ICU admission/support, need for invasive or noninvasive mechanical ventilation, other oxygenation methods, renal replacement therapy need and duration, ICU or hospital discharge status and disposition, ICU and hospital mortality. |
RESEARCH WORKFORCE AND INFRASTRUCTURE
Successful projects begin with the right team. Components of a successful observational registry research team generally include people with expertise in the subject matter; human subjects research regulations; team building and outreach; data entry; data storage, cleaning and manipulation; and epidemiology, health services research, and statistics. The VIRUS study used the core competencies in critical care subject matter expertise, team building, data storage, cleaning, and manipulation and observational research that were already present within the SCCM Discovery Research Network (an existing critical care professional society data infrastructure) and expanded the SCCM core team. Support from SCCM and research foundations was used to support central database infrastructure and data entry within individual sites. Data cleaning and research expertise were assembled largely based upon volunteer contributions from SCCM membership, as well as industry partnerships. This multifaceted and multidisciplinary approach that targeted funding to grassroots data entry efforts and database infrastructure, while relying on volunteer time from academic and industry partners (in exchange for data access), allowed for rapid, efficient, and cost-effective expansion of the registry during a pandemic.
RAPID, HARMONIZED DATA COLLECTION
The first step in collecting clinically useful data in a pandemic is to establish a large consortium of healthcare centers to facilitate rapid data collection from sites with a representation of diverse patients and practice patterns. Later steps involve development of methods to validate and then automate upload of data from electronic health records to ease workloads from sites already strained by the burdens of pandemic response. This also allows for accurate and real-time dissemination of data. Such a consortium can then provide the foundation to build informative observational and randomized studies.
Implementation of a registry during a pandemic requires extensive project management, including the planning, initiation, execution, monitoring, and, eventually, closing of the registry (Table 1). Early steps require 1) human subjects research approvals and data use agreements; 2) development of electronic case report forms (CRF); 3) defining common data standards and terminology; 4) development of standard operating procedure (SOP) and training for data entry; 4) coordination with other studies; 5) data quality control, automation, and validation; and, finally 6) planning for diverse methods of knowledge dissemination through the registry dashboard and publications (Fig. 1).
Figure 1.
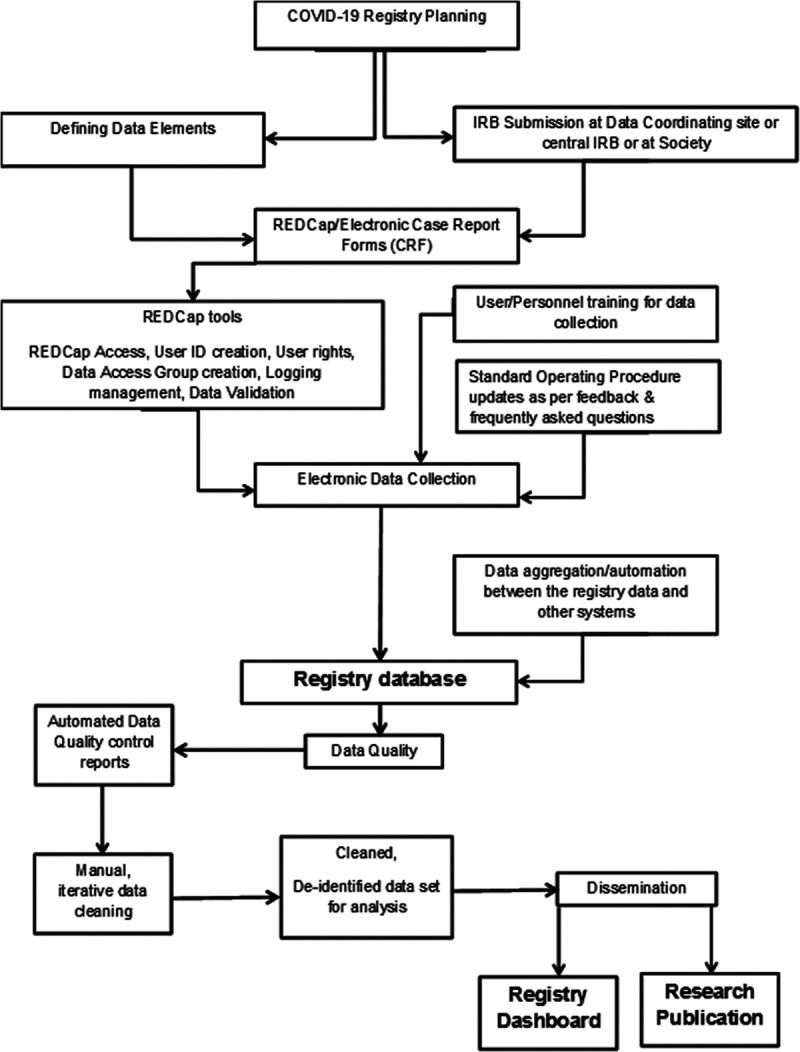
Flow diagram of data entry and presentation for Viral Infection and Respiratory Illness Universal Study. COVID-19 = coronavirus disease 2019, CRF = case report form, ID = identification, IRB = institutional review board, REDCap = Research Electronic Data Capture.
Human Subjects Research Approvals and Data Use Agreements
Appropriate oversight and approvals from institutional research review boards are necessary prior to collecting human subjects’ data for research purposes. The VIRUS study was designed to upload deidentified data from individual sites to a central database. Challenges to collection of deidentified data collection include the restrictions on collection of potential identifiers such as dates. Thus, we restricted data collection to relative time within a hospitalization (hospital day and intensive care day number), rather than absolute dates. Draft institutional review board applications and data use agreements were supplied to individual study sites to expedite the regulatory process.
Case Report Forms
The first step in developing case report forms (CRFs) is to define data elements. For VIRUS, we sought to include data elements common to prior COVID-19 registry work in order to enable future harmonization across studies and used the World Health Organization COVID-19 CRFs as a starting template. Data elements for inclusion were selected to capture elements of COVID-19 diagnosis, patient demographics, chronic comorbidities, acute illness characteristics, and details of critical care interventions and outcomes. Electronic CRFs were then constructed using Research Electronic Data Capture (REDCap) (8), a secure web-based software and workflow methodology for electronic collection and management of research data (Fig. 2). Among other characteristics, it provides 1) an intuitive interface for validated data entry, with automated data type and range checks; 2) audit trails for tracking data manipulation and export procedures; 3) automated data export procedures to common statistical packages; and 4) procedures for importing data from external sources.
Figure 2.
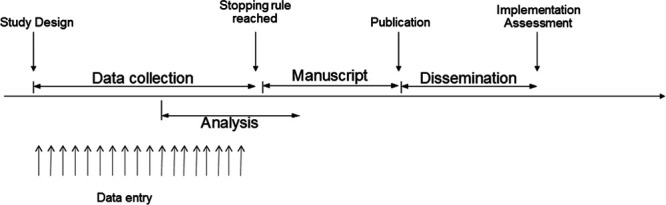
Pathways for rapid and rigorous generation and dissemination of knowledge in a pandemic setting.
Development of SOP and Training
Regular, recurrent, remote training with clinical research coordinators/data abstractors at participating study sites globally is necessary to ensure data prioritization, integrity, and maintain bidirectional open catheters of communication between study sites and central registry organization. The SOP provides a common and standard description of all data elements accessible to all investigators. For VIRUS, weekly data coordination meeting via teleconference resulted in not only top-down directives for relaying SOPs and answering questions but also for grassroots reports of data entry difficulties to be quickly communicated and resolved, enabling a continuously learning system for registry operations improvement.
Data Quality Monitoring and reporting
After the initial few patients’ data entry, a frequent quality check should help ensure the adherence to the study protocol. Tools such as REDCap reporting tool for monitoring and querying patient records can help with this process. Necessary actions could be taken to address problems related to data inconsistency and missing information, for example, retraining and timely feedback on missing or out-of-range values and logical inconsistencies.
Potential differences in units, measurement, and normal ranges, especially for laboratory values, need to be identified, with plans for normalization and harmonization across the registry. A clinical pharmacist, microbiologist, and laboratory medicine specialist should be included in data planning. For VIRUS, we performed multilayered data quality monitoring. We evaluated weekly for missing data and contacted sites with high missingness rates. We initially asked sites to focus on establishing high-quality, validated data entry for the data fields most important to the data dashboard and then to focus on fields common to most research projects (i.e, demographics, comorbidities, outcomes). We established automated data upload in coordination with major electronic health record manufacturers and validated automated data upload versus manual review across greater than 20 sites. VIRUS engaged a core group of physicians, data scientists, statisticians, epidemiologists, and pharmacists to oversee data entry. Finally, we performed multistep data cleaning to look for field entries out of range or proper data type, with iterations to contact sites for correction of errant data.
Coordination With Other Studies
Potential problems arise when multiple research efforts seek to enroll similar patients across different studies, including duplication of data entry work, duplication of patients across registries (9), and inefficient duplication of research questions. The VIRUS investigators sought to address these problems early by planning with other registries to avoid duplicating study sites, as well as openly sharing CRFs to harmonize data collection to enable future collaboration across registries.
TRANSPARENT PROCESSES FOR CHOOSING RESEARCH QUESTIONS
Decisions to embark on a study question require determination as to whether a study is feasible and able to produce valid results. Therefore, study plans should a priori determine targets for database size, event and exposure rates, missing data, and extent of likely unmeasured confounding in which it is reasonable to begin an analysis. Determination of optimal times to make the data available for analysis can be accomplished via simulation studies modeling likely outcomes under various scenarios of database completion and missingness.
In principle, research questions should be chosen that promise the greatest probability of net benefit given constraints on data and available resources. In practice, prior research on evidence prioritization emphasizes the importance of making such determinations using an explicit process to engage key stakeholders that recognizes their diverse contexts and values (10). At a basic level, such processes can help to maximize resources by avoiding duplication and promoting collaboration (11). They can also go further by embracing standards that reflect accountability and reason, such as full public transparency (12)—in this case concerning the rationale, rules, and results of the prioritization process—and also by offering opportunity for challenge and dissent (13).
Consistent with published guidelines (14), VIRUS sought to engage a range of stakeholders. Most directly, it was designed to serve the needs of patients and the range of clinicians who care for them, including (but not limited to) physicians, nurses, pharmacists, respiratory therapists, advanced practice nurses, and physician assistants. Given early evidence that the COVID-19 pandemic was exacerbating existing health disparities, both enrollment and funding support of study sites from diverse areas, as well as solicitation of research questions addressing health equity, were a priority (15).
In accordance with an open science perspective that will maximize discovery, the VIRUS study implemented a mechanism for submission of ancillary proposal ideas. Ancillary study proposals may be submitted by VIRUS participating centers and outside investigators for the use of deidentified VIRUS registry data for research purposes. The proposals are submitted via an online submission portal and a standardized application template and are reviewed by the Discovery VIRUS publication review workgroup for approval and feedback. VIRUS core investigators are blinded to proposal topics during the submission period and are only shared with the VIRUS study group during the review period. Proposals are evaluated by two reviewers, using review criteria based on National Institutes of Health (NIH) scoring guidance. Teams that submit strong proposals (e.g., NIH scores of 5 or lower) are provided VIRUS data in accordance with the proposal. Proposals with similar aims are encouraged to collaborate.
For ancillary studies and VIRUS team publications, in addition to the article writing and analysis team, all VIRUS contributors (site principal investigators, research assistants of enrolling sites) will be listed by type of contribution in VIRUS manuscript appendices or supplements.
STATE-OF-THE-ART OBSERVATIONAL METHODS
Rigorous, well-designed observational studies are critical to understanding emerging pandemics. Registries are well-positioned to provide clinically useful data to inform epidemiology, risk factors, practice pattern variation, and, in some select cases, provide early signals of treatment effectiveness and safety. Valid observational studies require accurate and detailed data regarding a patient’s exposure history, prior medical history, comorbidities, medications, as well as time-varying events and risk measures during the illness. In addition, design of studies seeking observational inference requires prior information—often from content area experts—regarding determinants of exposure and outcome in order to limit systematic error, as well as statistical methods to address random error.
We have proposed the following general principles for the conduct of observational studies using VIRUS registry data: studies must clearly define their objective. Too often studies muddle the goal of being descriptive, seeking to assess a causal question, or performing prediction. The result is often an ensemble of inappropriate and improper methodological decisions. Descriptive studies that test for group differences will be explicit that these differences not infer causal relationships. The desire to venture into causal inference will be avoided unless explicitly stated. Studies with causal intent will adhere to causal theory and best practices. At a minimum, this will include careful and precise question articulation, inclusion/exclusion criteria consideration (as one would do in a randomized trial), prespecified causal hypotheses (e.g., using directed acyclic graphs) that inform the analytic approach and promote transparency regarding assumptions, and sensitivity analyses to assess how a priori assumptions regarding potential selection, information, and confounding biases may impact resulting effect estimates and interpretations. We believe target trial emulation, with attention to problems with immortal person time and common types of selection bias (6, 16), is desirable as it inherently follows these principles while maintaining transparency. Accordingly, we will recommend that causal inference studies follow and report the STrengthening the Reporting of OBservational studies in Epidemiology, Risk Of Bias In Non-randomized Studies - of Interventions (ROBINS-I) (17), or Consolidated Standards of Reporting Trials guidelines and checklists. Prediction models will be designed with their intended use in mind and adhere to the Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD) statement and guidelines (18). All approaches will explicitly outline plans to deal with problems introduced by missing data (19). Although machine learning-based methods of prediction and causal inference may be useful in large observational studies, principles of study design and conduct outlined above should be maintained regardless of methods of covariate and confounder selection.
GUIDANCE TO ACCOUNT FOR RANDOM ERROR IN EFFECT ESTIMATES
Other important questions arise when a continuously updated database is queried for relevant research questions. One pressing point is how to deal with cases who are still receiving hospital care at the moment of the database inquiry, an issue that may radically change result interpretation (20). Another important point is defining how to determine when it is time to run a specific analysis for a given research question in the database. Within the VIRUS registry, we will seek to use Bayesian approaches to decision-making regarding the progress of studies through the stages of analysis, results reporting, and subsequent evaluation of practice change and implementation (Fig. 2). In observational studies designed to infer causal associations, designing a target emulated trial with stopping rules can assist in decisions to report results for a given hypothesis. For example, the emulated trial may assess the effects of an intervention on mortality of severe COVID-19 patients with data continuously acquired. Once a predefined stopping rule is achieved, data will be analyzed, and results disseminated. For example, the emulated study will be “interrupted and reported” (i.e., although subsequent information will still be collected, the data used for the specific report will be considered “closed”, like a database lock for a clinical trial) for superiority after the target trial has a posterior probability of benefit above 90% (for example) or for futility if there is a high chance that the estimate of intervention effect is within a prespecified region of practical equivalence. This process is not meant to be exhaustive.
Ancillary studies will have the opportunity to collaborate with independent methodology experts within observational inference and Bayesian designs, who will assist with analysis plans and stopping rule decisions. This independent committee, like a traditional data monitoring committee, can perform recommendations on whether the reports are sufficient to allow a clear report or if more data are needed. For example, let us consider an intervention that has a high adjusted posterior probability of severe harm (say over 0.8 probability of an odds ratio [OR] for mortality above 1.25). In this scenario, an independent committee may judge that reporting data is of public interest. Other criteria may be applied to different scenarios. For example, consider that after 4,000 patients included (of whom 1,000 received an intervention), the model is consistent with a high probability (defined a priory) that the intervention effect is within a practical equivalence value (e.g., an OR between 0.90 and 1.1). In this scenario, it may be useful to consider reporting these results (and continue data collection) to reinforce equipoise for randomized clinical trials or to remove expectations of general public, including physicians and patients, of an effect size of high magnitude. This approach will avoid excessive reporting of inconclusive data, which can be an issue in observational studies.
Finally, one important point is the assessment of the implementation of results within the cohort. After insights from clinical trials or from VIRUS data, we will track and report whether the new evidence was adopted by the participating sites (e.g., removal of a given treatment shown to be harmful or neutral). This represents a unique opportunity to advance both clinical research and implementation science.
INNOVATIVE PEER REVIEW PATHWAYS
Harm can result from the uncritical propagation of spurious findings but also from the delayed dissemination of rigorous research. Posting of nonpeer-reviewed preprints of manuscripts can more rapidly spread information, but without proper vetting, there is a high risk of misinformation. The current system of peer review of manuscripts often provides a check to the promotion of spurious findings but may take weeks or sometimes months to complete. Welsh et al (21) found the median age of data in high impact clinical trials was 3 years. New pathways are needed that combine the rigor of peer review with the speed of preprints. Similar to the idea of “registered reports” advocated by the Center for Open Science to promote sound science through replication, we support a system in which introduction and methods are peerreviewed prior to data analysis (22). If the proposed methods (and the related assumptions) and sensitivity analyses are deemed rigorous in early peer review, then participating journals may verify the study as having undergone methodological peer review. Studies deemed “acceptable” at the methodological peer review stage could then move forward with posting results in near real time as described under the “Guidance to Limit Random Error”. Because even perfect methods need to be well-executed in order to produce valid data, journals would then provide an expedited review of the results. Subsequent peer-review would then primarily focus on the proper execution and testing of assumptions rather than the methodology. This would ideally be completed using full code and data sharing by authors.
The intent of expedited results review following methods review would be to either verify that the previously reviewed methods were accomplished and that the journal continues to stand behind the study or provide rationale for a change of status to the probationary, methods-based study approval. In this model, both researchers and certified commentators could post comments on the interpretation of the results similar to postpublication peer review currently performed on social media. Along a derived timeline, analysis would be closed and the final manuscript published in the certifying journal. Such a process would combine rigor and efficiency, within the current model of journal- and crowdsource-based research vetting and dissemination, in order to provide more near real-time information to inform clinical practice. The VIRUS team will seek to work with established journals toward achieving these goals. For example, VIRUS investigators may choose to have their project run through traditional publication pathways—or for selected projects in which the investigators and journal are amenable—to pass through the innovation pathway of two-stage peer review and continuously updated results posting (Fig. 3).
Figure 3.
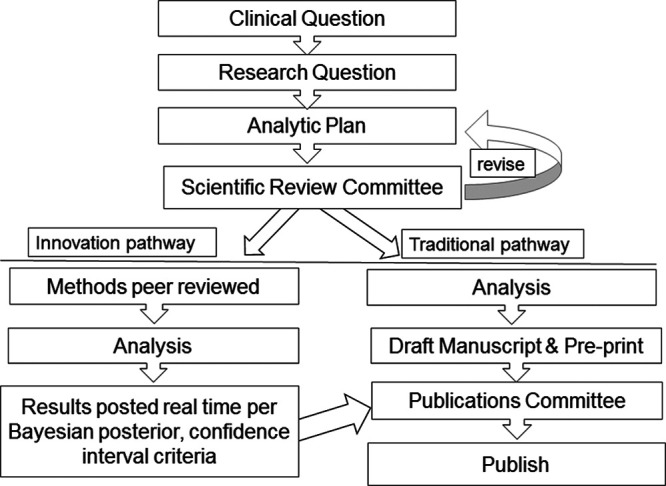
Schema of study proposal review and dissemination pathways.
IMPLEMENTATION AND IMPROVEMENT
The key postulate of evidence based medicine is integration of clinical research findings into rational decision making at the bedside while taking into consideration clinical context and patient preference (23). Despite the proliferation of ICU clinical research over the past two decades, application of the research findings has been challenging. The NIH and professional organizations have emphasized the role of implementation science (i.e., T4 translation) in closing evidence to practice gaps (24). The COVID-19 pandemic has exposed the existing weaknesses and at the same time provided impetus for development and rapid adoption of innovative solutions (25). To facilitate rapid adoption and dissemination of actionable clinical research findings, the SCCM VIRUS investigators have adopted implementation science tools into reporting of research findings. To facilitate bedside (shared) decision-making processes, new research findings will be incorporated into web-based decision aids. The decision aids will be designed to present the risk, benefit, and burden of specific interventions taking into consideration prior knowledge, clinical context, and preference and how these are modified by the new research findings. The first version of SCCM VIRUS dashboard https://sccmcovid19.org/ provides continuously updated display of organ support and outcome of COVID-19 patients, with plans for updating with clinical decision support tools as they become available in the future.
CONCLUSIONS
Use of observational data to inform the response and care of patients during a pandemic faces unique challenges to data collection, choice of research questions, study design, analysis, and interpretation. Pandemic registries require attention to ensure data quality and harmonization across hundreds of sites; transparent process for choice of research questions; use of current best practices in design of descriptive, predictive, and inferential studies; innovative approaches to characterize random error in the setting of constantly updated data; and transitions from a focus on discovery to implementation.
The SCCM Discovery VIRUS COVID-19 registry seeks to use the proposed best practices described herein—combined with the organizational infrastructure of the SCCM and a grassroots effort from clinical sites worldwide—in order to develop clinically useful knowledge against a common threat to the health of humanity. Impact of the registry will be measured through research publications, citations, and continuous surveillance of practice change. Future use of the established registry infrastructure can potentially springboard to a clinical trials network. Successful accomplishment of our goals will result in novel collaborations across nations, opportunities for mentored research involving early-stage investigators, and an oversight structure that standardizes research to high quality methods.
Footnotes
The Coronavirus Disease Viral Infection and Respiratory Illness Universal Study registry is funded in part by the Gordon and Betty Moore Foundation.
Dr. Walkey receives funding from the National Institutes of Health/National Heart, Lung and Blood Institute (NIH/NHLBI) grants R01HL151607, R01HL139751, R01HL136660, Agency of Healthcare Research and Quality R01HS026485, Boston Biomedical Innovation Center/NIH/NHLBI 5U54HL119145-07, and royalties from UptoDate. Dr. Harhay receives funding from NIH/NHLBI grant R00 HL141678. The remaining authors have disclosed that they do not have any potential conflicts of interest.
REFERENCES
- 1.Rome BN, Avorn J. Drug evaluation during the Covid-19 pandemic. N Engl J Med. 2020; 382:2282–2284 [DOI] [PubMed] [Google Scholar]
- 2.Rowland C. FDA authorizes widespread use of unproven drugs to treat coronavirus, saying possible benefit outweighs risk. Washington Post. 2020. Available at: https://www.washingtonpost.com/business/2020/03/30/coronavirus-drugs-hydroxychloroquin-chloroquine/. Accessed July 13, 2020 [Google Scholar]
- 3.Mehra MR, Desai SS, Ruschitzka F, et al. Hydroxychloroquine or chloroquine with or without a macrolide for treatment of COVID-19: A multinational registry analysis. Lancet. 2020. May 22. [online ahead of print] [DOI] [PMC free article] [PubMed] [Google Scholar] [Retracted]
- 4.2020. . Available at: https://www.recoverytrial.net/. Accessed July 13, 2020.
- 5.REMAP-CAP. 2020. . Available at: https://www.remapcap.org/. Accessed July 13, 2020
- 6.Gershon AS, Jafarzadeh SR, Wilson KC, et al. Clinical knowledge from observational studies. Everything you wanted to know but were afraid to ask. Am J Respir Crit Care Med. 2018; 198:859–867 [DOI] [PubMed] [Google Scholar]
- 7.Walkey AJ, Kumar VK, Harhay MO, et al. The Viral Infection and Respiratory Illness Universal Study (VIRUS): An international registry of coronavirus 2019-related critical illness. Crit Care Explor. 2020; 2:e0113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Harris PA, Taylor R, Thielke R, et al. Research electronic data capture (REDCap)–a metadata-driven methodology and workflow process for providing translational research informatics support. J Biomed Inform. 2009; 42:377–381 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Bauchner H, Golub RM, Zylke J. Editorial concern-possible reporting of the same patients with COVID-19 in different reports. JAMA. 2020; 323:1256. [DOI] [PubMed] [Google Scholar]
- 10.Sibbald SL, Singer PA, Upshur R, et al. Priority setting: What constitutes success? A conceptual framework for successful priority setting. BMC Health Serv Res. 2009; 9:43. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Nasser M, Welch V, Tugwell P, et al. Ensuring relevance for cochrane reviews: Evaluating processes and methods for prioritizing topics for cochrane reviews. J Clin Epidemiol. 2013; 66:474–482 [DOI] [PubMed] [Google Scholar]
- 12.Nosek BA, Alter G, Banks GC, et al. SCIENTIFIC STANDARDS. Promoting an open research culture. Science. 2015; 348:1422–1425 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Daniels N, Sabin J. The ethics of accountability in managed care reform. Health Aff (Millwood). 1998; 17:50–64 [DOI] [PubMed] [Google Scholar]
- 14.Concannon TW, Meissner P, Grunbaum JA, et al. A new taxonomy for stakeholder engagement in patient-centered outcomes research. J Gen Intern Med. 2012; 27:985–991 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Nasser M, Ueffing E, Welch V, et al. An equity lens can ensure an equity-oriented approach to agenda setting and priority setting of Cochrane Reviews. J Clin Epidemiol. 2013; 66:511–521 [DOI] [PubMed] [Google Scholar]
- 16.Lederer DJ, Bell SC, Branson RD, et al. Control of confounding and reporting of results in causal inference studies. Guidance for authors from editors of respiratory, sleep, and critical care journals. Ann Am Thorac Soc. 2019; 16:22–28 [DOI] [PubMed] [Google Scholar]
- 17.Sterne JA, Hernán MA, Reeves BC, et al. ROBINS-I: A tool for assessing risk of bias in non-randomised studies of interventions. BMJ. 2016; 355:i4919. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Collins GS, Reitsma JB, Altman DG, et al. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): The TRIPOD statement. Ann Intern Med. 2015; 162:55–63 [DOI] [PubMed] [Google Scholar]
- 19.Desai M, Esserman DA, Gammon MD, et al. The use of complete-case and multiple imputation-based analyses in molecular epidemiology studies that assess interaction effects. Epidemiol Perspect Innov. 2011; 8:5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Clarification of mortality rate and data in abstract, results, and table 2. JAMA. 2020; 323:2098. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Welsh J, Lu Y, Dhruva SS, et al. Age of data at the time of publication of contemporary clinical trials. JAMA Netw Open. 2018; 1:e181065. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Smulders YM. A two-step manuscript submission process can reduce publication bias. J Clin Epidemiol. 2013; 66:946–947 [DOI] [PubMed] [Google Scholar]
- 23.Sackett DL, Rosenberg WM. The need for evidence-based medicine. J R Soc Med. 1995; 88:620–624 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Weiss CH, Krishnan JA, Au DH, et al. ; ATS Ad Hoc Committee on Implementation Science. An official American Thoracic Society research statement: Implementation science in pulmonary, critical care, and sleep medicine. Am J Respir Crit Care Med. 2016; 194:1015–1025 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Dong E, Du H, Gardner L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect Dis. 2020; 20:533–534 [DOI] [PMC free article] [PubMed] [Google Scholar]