
Fig. 1.
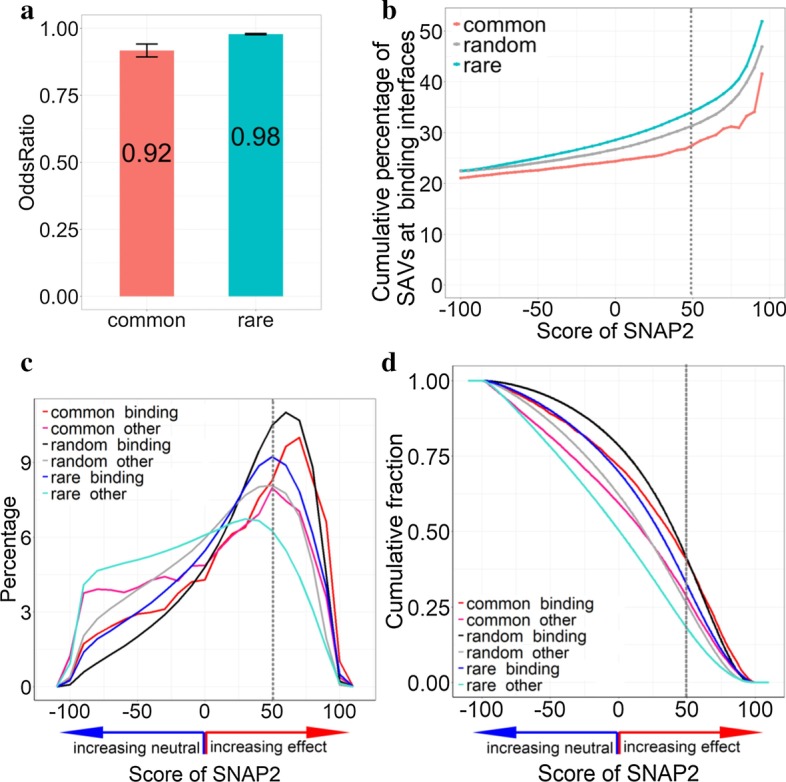
Macro-molecular binding SAVs. All results were based on the ExAC data from 60 k individuals [5]; SNAP2 [15, 16] predicted effects on molecular protein function, and ProNA2020 [4] predicted residues at ProNA-binding interfaces (binding either other proteins, DNA, or RNA). (a demonstrates the degree to which SAVs (Single Amino acid Variants) are predicted more or less often than expected by chance (Methods) in ProNA-binding interfaces by the method ProNA2020 [4]. In particular, common SAVs (observed in > 5% of population) and rare SAVs (observed in < 1% of population) were significantly under-represented in ProNA-binding. The lines below and above the bars for the odds ratios marked the 95% confidence intervals taken from Fisher’s exact test computed on the number of SAVs predicted as binding/non-binding in each class (common or rare; note the error bar for the rare SAVs is so small that it appears as a single horizontal line). b Zooms into the subset of all SAVs predicted as ProNA-binding. The y-axis gives the cumulative percentage of SAVs predicted above a certain SNAP2-score (x-axis) [15, 16] predicted to be in ProNA-binding interfaces. This score reflects the strength of predicting SAVs to affect molecular protein function (+ 100 strongest prediction of effect) or to be neutral (− 100 strongest prediction of neutrality). Random (gray line) was based on the average over all possible 19-non-native mutations computed in silico (Method). Computing Kolmogorov–Smirnov p values between all pairs of lines revealed that the differences between common and all others were extremely significant (common vs. rare: p value < 2.2 × 10–16 and common vs. random: p value < 2.7 × 10–15). The p value between random and rare was not quite significant (p value < 2 × 10–2, Additional File 1: Table S1; c, d distinguish distributions between SAVs at residue positions predicted in ProNA-binding interfaces (dubbed binding) and non-binding (dubbed other) for different SNAP2-score thresholds. While c shows the raw distribution, c highlighted the cumulative distribution (as in b). The differences between all pairwise curves were statistically significant (Additional File 1: Table S1). For instance, for very reliable effect predictions with SNAP2-scores ≥ 50 (dashed vertical lines), about 40% of all common SAVs were predicted to affect molecular function and to be in a residue predicted or observed (ProNA2020 [4] uses whatever is available, either a homology-based inference from experimental information or machine learning prediction) to be in an interface binding a large molecule (protein, DNA, or RNA)