
Fig. 1.
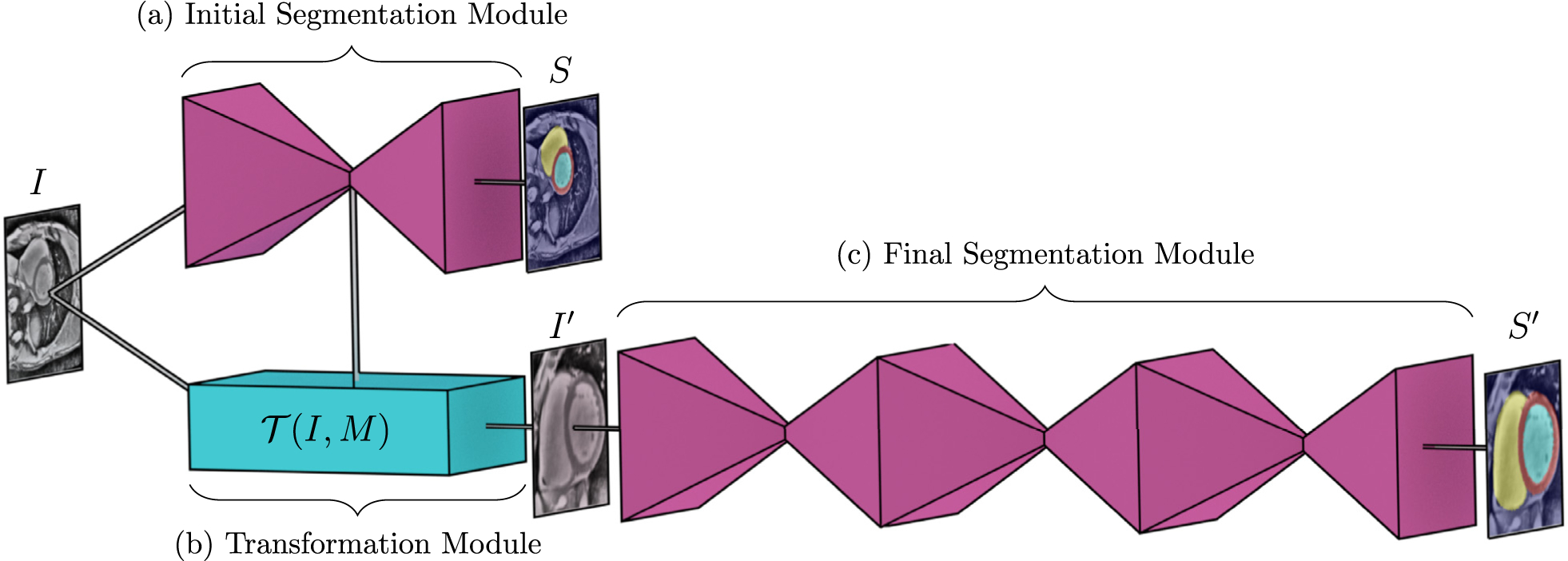
Overview of the Ω-Net architecture (a) The initial, unoriented SSFP image I is fed into a U-Net module, producing an initial segmentation S. (b) The features from the central (most downsampled) layers of this U-Net are used by the transformation module to predict the parameters M of a transformation and transform the input image into a cannonical orientation, . (C) This transformed image is fed into a stacked hourglass module to obtain a final segmentation in the canonical orientation S′. Note that, all modules shown are trained in an end-to-end way from scratch.